
pytorch 计算混淆矩阵
创始人
2025-05-28 15:17:22
0次
混淆矩阵是评估模型结果的一种指标 用来判断分类模型的好坏
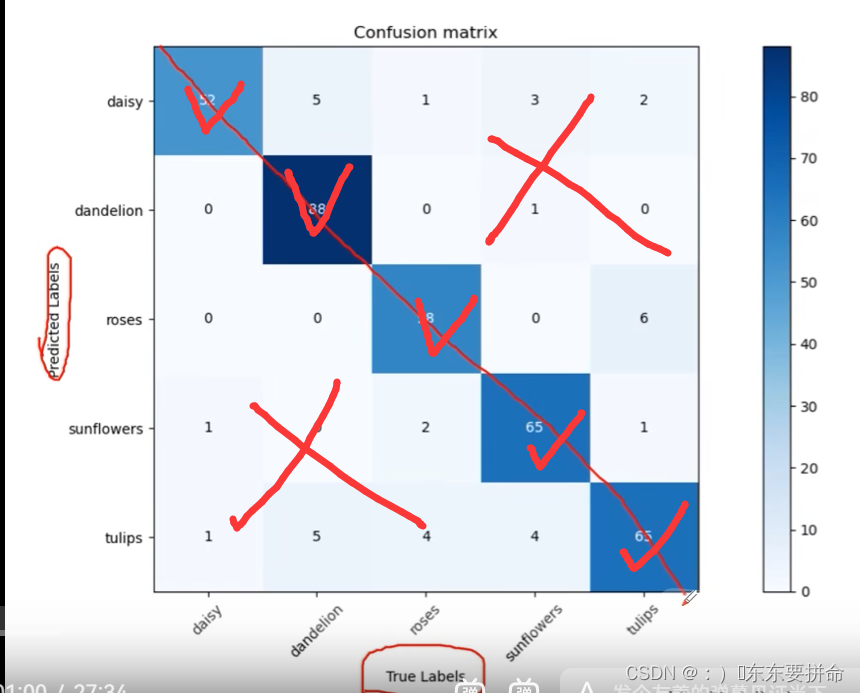
预测对了 为对角线
还可以通过矩阵的上下角发现哪些容易出错
从这个 矩阵出发 可以得到 acc != precision recall 特异度?

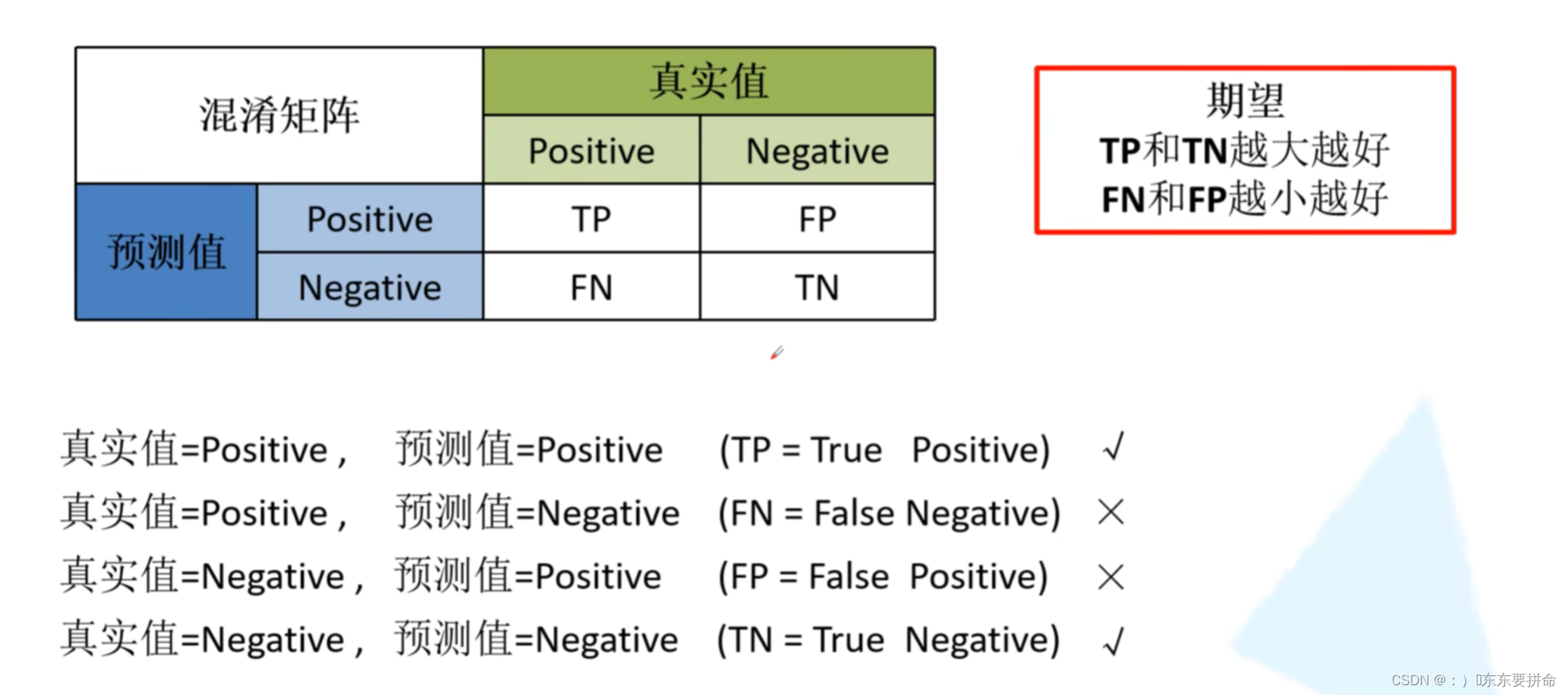
目标检测01笔记AP mAP recall precision是什么 查全率是什么 查准率是什么 什么是准确率 什么是召回率_:)�东东要拼命的博客-CSDN博客
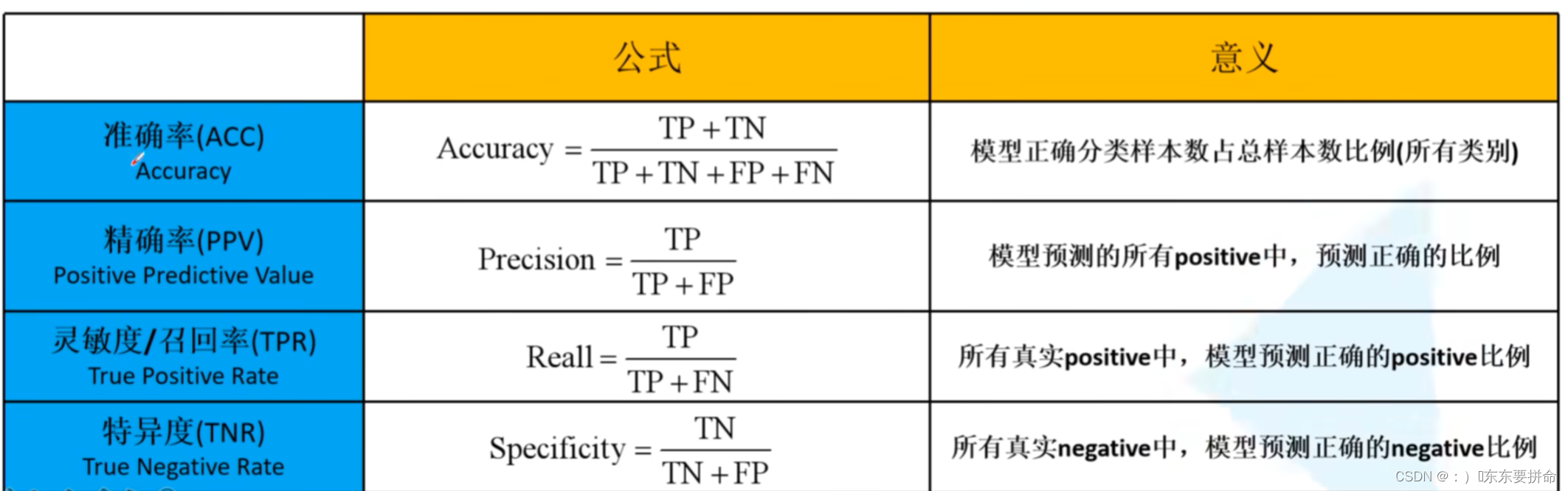
acc 是对所有类别来说的
其他三个都是 对于类别来说的

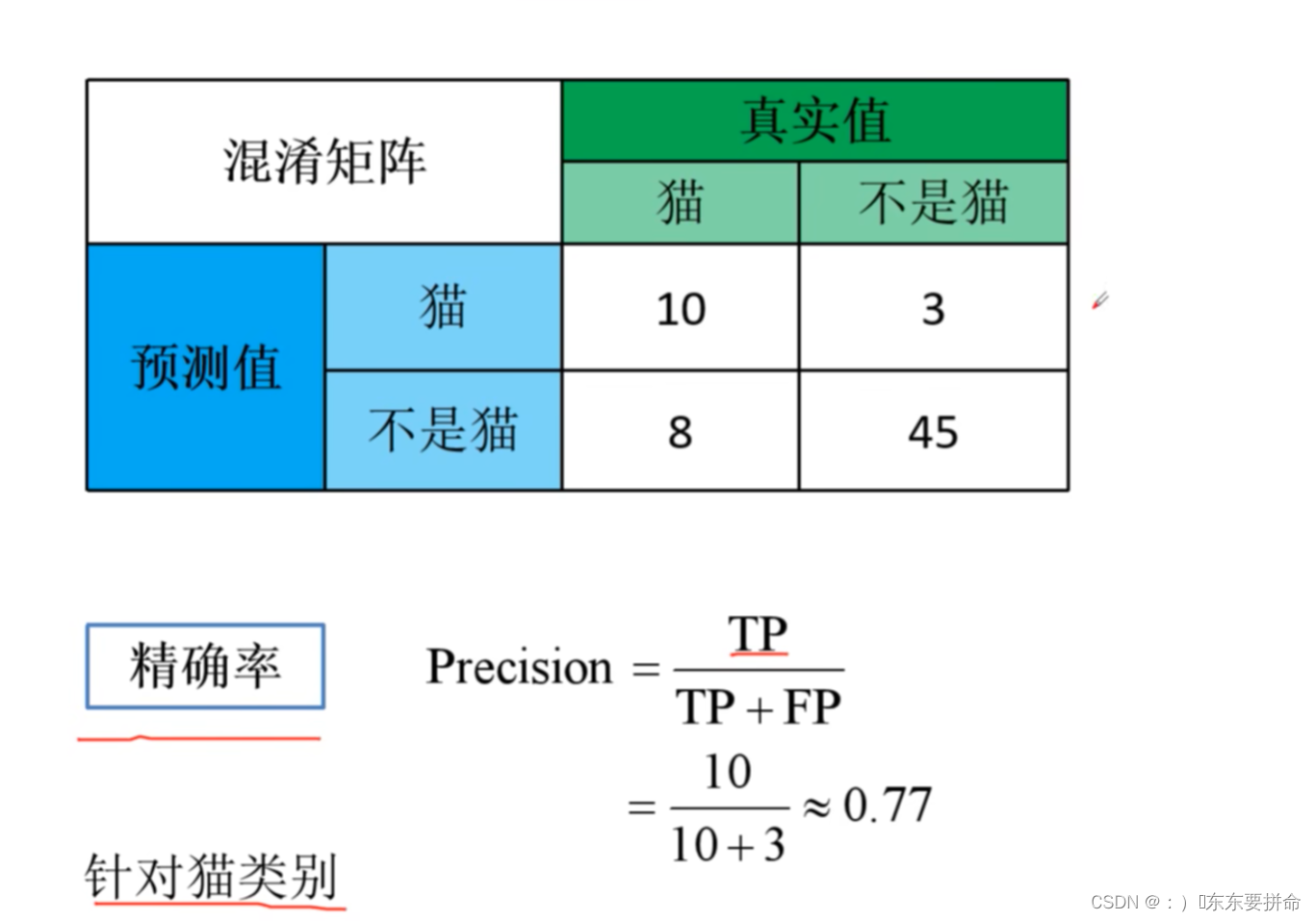
下面给出源码
import json
import osimport matplotlib.pyplot as plt
import numpy as np
import torch
from prettytable import PrettyTable
from torchvision import datasets
from torchvision.models import MobileNetV2
from torchvision.transforms import transformsclass ConfusionMatrix(object):"""注意版本问题,使用numpy来进行数值计算的"""def __init__(self, num_classes: int, labels: list):self.matrix = np.zeros((num_classes, num_classes))self.num_classes = num_classesself.labels = labelsdef update(self, preds, labels):for p, t in zip(preds, labels):self.matrix[t, p] += 1# 行代表预测标签 列表示真实标签def summary(self):# calculate accuracysum_TP = 0for i in range(self.num_classes):sum_TP += self.matrix[i, i]acc = sum_TP / np.sum(self.matrix)print("acc is", acc)# precision, recall, specificitytable = PrettyTable()table.fields_names = ["", "pre", "recall", "spec"]for i in range(self.num_classes):TP = self.matrix[i, i]FP = np.sum(self.matrix[i, :]) - TPFN = np.sum(self.matrix[:, i]) - TPTN = np.sum(self.matrix) - TP - FP - FNpre = round(TP / (TP + FP), 3) # round 保留三位小数recall = round(TP / (TP + FN), 3)spec = round(TN / (FP + FN), 3)table.add_row([self.labels[i], pre, recall, spec])print(table)def plot(self):matrix = self.matrixprint(matrix)plt.imshow(matrix, cmap=plt.cm.Blues) # 颜色变化从白色到蓝色# 设置 x 轴坐标 labelplt.xticks(range(self.num_classes), self.labels, rotation=45)# 将原来的 x 轴的数字替换成我们想要的信息 self.num_classes x 轴旋转45度# 设置 y 轴坐标 labelplt.yticks(range(self.num_classes), self.labels)# 显示 color bar 可以通过颜色的密度看出数值的分布plt.colorbar()plt.xlabel("true_label")plt.ylabel("Predicted_label")plt.title("ConfusionMatrix")# 在图中标注数量 概率信息thresh = matrix.max() / 2# 设定阈值来设定数值文本的颜色 开始遍历图像的时候一般是图像的左上角for x in range(self.num_classes):for y in range(self.num_classes):# 这里矩阵的行列交换,因为遍历的方向 第y行 第x列info = int(matrix[y, x])plt.text(x, y, info,verticalalignment='center',horizontalalignment='center',color="white" if info > thresh else "black")plt.tight_layout()# 图形显示更加的紧凑plt.show()if __name__ ==' __main__':device = torch.device("cuda:0" if torch.cuda.is_available()else "cpu")print(device)# 使用验证集的预处理方式data_transform = transforms.Compose([transforms.Resize(256),transforms.CenterCrop(224),transforms.ToTensor()transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])])data_loot = os.path.abspath(os.path.join(os.getcwd(), "../.."))# get data root pathimage_path = data_loot + "/data_set/flower_data/"# flower data set pathvalidate_dataset = datasets.ImageFolder(root=image_path +"val",transform=data_transform)batch_size = 16validate_loader = torch.utils.data.DataLoder(validate_dataset,batch_size=batch_size,shuffle=False,num_workers=2)net = MobileNetV2(num_classes=5)#加载预训练的权重model_weight_path = "./MobileNetV2.pth"net.load_state_dict(torch.load(model_weight_path, map_location=device))net.to(device)#read class_indicttry:json_file = open('./class_indicts.json', 'r')class_indict = json.load(json_file)except Exception as e:print(e)exit(-1)labels = [label for _, label in class_indict.item()]# 通过json文件读出来的labelconfusion = ConfusionMatrix(num_classes=5, labels=labels)net.eval()# 启动验证模式# 通过上下文管理器 no_grad 来停止pytorch的变量对梯度的跟踪with torch.no_grad():for val_data in validate_loader:val_images, val_labels = val_dataoutputs = net(val_images.to(device))outputs = torch.softmax(outputs, dim=1)outputs = torch.argmax(outputs, dim=1)# 获取概率最大的元素confusion.update(outputs.numpy(), val_labels.numpy())# 预测值和标签值confusion.plot()# 绘制混淆矩阵confusion.summary()# 来打印各个指标信息是这样的 这篇算是一个学习笔记,其中的基础图都源于我的导师
霹雳吧啦Wz的个人空间_哔哩哔哩_bilibili
欢迎无依无靠的CV同学加入
讲的非常好 代码其实也是导师给的
我能做的就是读懂每一行加点注释
给不想看视频的同学留点时间
相关内容
热门资讯
电视安卓系统哪个品牌好,哪家品...
你有没有想过,家里的电视是不是该升级换代了呢?现在市面上电视品牌琳琅满目,各种操作系统也是让人眼花缭...
安卓会员管理系统怎么用,提升服...
你有没有想过,手机里那些你爱不释手的APP,背后其实有个强大的会员管理系统在默默支持呢?没错,就是那...
安卓系统软件使用技巧,解锁软件...
你有没有发现,用安卓手机的时候,总有一些小技巧能让你玩得更溜?别小看了这些小细节,它们可是能让你的手...
安卓系统提示音替换
你知道吗?手机里那个时不时响起的提示音,有时候真的能让人心情大好,有时候又让人抓狂不已。今天,就让我...
安卓开机不了系统更新
手机突然开不了机,系统更新还卡在那里,这可真是让人头疼的问题啊!你是不是也遇到了这种情况?别急,今天...
安卓系统中微信视频,安卓系统下...
你有没有发现,现在用手机聊天,视频通话简直成了标配!尤其是咱们安卓系统的小伙伴们,微信视频功能更是用...
安卓系统是服务器,服务器端的智...
你知道吗?在科技的世界里,安卓系统可是个超级明星呢!它不仅仅是个手机操作系统,竟然还能成为服务器的得...
pc电脑安卓系统下载软件,轻松...
你有没有想过,你的PC电脑上安装了安卓系统,是不是瞬间觉得世界都大不一样了呢?没错,就是那种“一机在...
电影院购票系统安卓,便捷观影新...
你有没有想过,在繁忙的生活中,一部好电影就像是一剂强心针,能瞬间让你放松心情?而我今天要和你分享的,...
安卓系统可以写程序?
你有没有想过,安卓系统竟然也能写程序呢?没错,你没听错!这个我们日常使用的智能手机操作系统,竟然有着...
安卓系统架构书籍推荐,权威书籍...
你有没有想过,想要深入了解安卓系统架构,却不知道从何下手?别急,今天我就要给你推荐几本超级实用的书籍...
安卓系统看到的炸弹,技术解析与...
安卓系统看到的炸弹——揭秘手机中的隐形威胁在数字化时代,智能手机已经成为我们生活中不可或缺的一部分。...
鸿蒙系统有安卓文件,畅享多平台...
你知道吗?最近在科技圈里,有个大新闻可是闹得沸沸扬扬的,那就是鸿蒙系统竟然有了安卓文件!是不是觉得有...
宝马安卓车机系统切换,驾驭未来...
你有没有发现,现在的汽车越来越智能了?尤其是那些豪华品牌,比如宝马,它们的内饰里那个大屏幕,简直就像...
p30退回安卓系统
你有没有听说最近P30的用户们都在忙活一件大事?没错,就是他们的手机要退回安卓系统啦!这可不是一个简...
oppoa57安卓原生系统,原...
你有没有发现,最近OPPO A57这款手机在安卓原生系统上的表现真是让人眼前一亮呢?今天,就让我带你...
安卓系统输入法联想,安卓系统输...
你有没有发现,手机上的输入法真的是个神奇的小助手呢?尤其是安卓系统的输入法,简直就是智能生活的点睛之...
怎么进入安卓刷机系统,安卓刷机...
亲爱的手机控们,你是否曾对安卓手机的刷机系统充满好奇?想要解锁手机潜能,体验全新的系统魅力?别急,今...
安卓系统程序有病毒
你知道吗?在这个数字化时代,手机已经成了我们生活中不可或缺的好伙伴。但是,你知道吗?即使是安卓系统,...
奥迪中控安卓系统下载,畅享智能...
你有没有发现,现在汽车的中控系统越来越智能了?尤其是奥迪这种豪华品牌,他们的中控系统简直就是科技与艺...