朴素贝叶斯学习报告
报告
- 朴素贝叶斯算法描述
公式: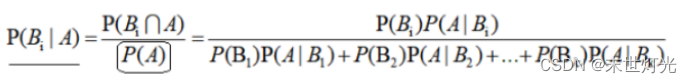
案例计算步骤:
- 一个数据集中有两个样本(B1,B2, B3)、(C1,C2,C3)和一个标签的两组(A1,A2);
- 给定一个测试样本(D1,D2,D3),使用贝叶斯公式求出测试样本属于A1组还是A2组;

3. 由于两式分母都是相同的,所以只需要考虑分子就可以了;

4.这时遇到一个问题,如果所选特征在训练集中不存在P(测试特征∣A1)将会等于0,最终的概率也会等于0,显然这样的结果不是我们想要的;
5. 这就需要我们引入特征相互独立的假设了;
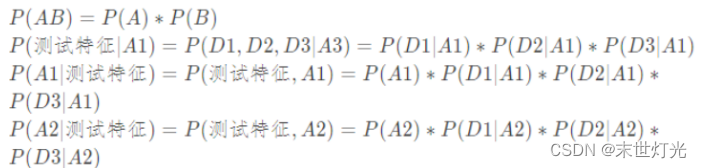
6. 根据在训练集数据就可以计算出A1的概率以及A1的条件下D1、D2、D3发生的概率了;
7. 虽然是能计算出来,但是可能会出现D1这个特征没有出现在训练集特征的情况,比如D1=高,恰好A1组相应类型特征对应的数据低,它的概率也会变成0;
8. 这是就出现了一个拉普拉斯系数,当测试集特征不存在(为0次)时,给它变成1,相应的分母也要加一。例如,测试集某个特征不存在,概率本应该是 0 \ n ,使用拉普拉斯系数后就变成了1\(n+1),一旦有一个是找不到的,所有测试集特征都要分子分母各加1。
- 朴素贝叶斯算法代码实现
调包:
import numpy as np
import scipy as sp
import time, sklearn, math
from sklearn.model_selection import train_test_split
import sklearn.datasets, sklearn.neighbors, sklearn.tree, sklearn.metrics, sklearn.naive_bayesdef sklearnNBTest():# Step 1. Load the dataset'''乳腺癌数据集经典的二分类数据集569个样本,每个样本30个特征,阳性样本357,阴性样本212'''# tempDataset = sklearn.datasets.load_breast_cancer()# 手写数字分类数据集# tempDataset = sklearn.datasets.load_digits()# 葡萄酒分类数据集tempDataset = sklearn.datasets.load_wine()x = tempDataset.datay = tempDataset.target# Split for training and testingx_train, x_test, y_train, y_test = train_test_split(x, y, test_size=0.1)# Step 2. Build classifier# tempClassifier = sklearn.naive_bayes.MultinomialNB()tempClassifier = sklearn.naive_bayes.GaussianNB()# tempClassifier = sklearn.naive_bayes.BernoulliNB()tempClassifier.fit(x_train, y_train)# Step 3. Test# precision, recall, thresholds = sklearn.metrics.precision_recall_curve(y_test, tempClassifier.predict(x_test))tempAccuracy = sklearn.metrics.accuracy_score(y_test, tempClassifier.predict(x_test))# tempRecall = sklearn.metrics.recall_score(y_test, tempClassifier.predict(x_test))# Step 4. Output# print("precision = {}, recall = {}".format(tempAccuracy, tempRecall))print("precision = {}.".format(tempAccuracy))sklearnNBTest()
数据集选择以及计算结果:
数据集1:乳腺癌数据集,经典的二分类数据集,569个样本,每个样本30个特征,阳性样本357,阴性样本212。
数据集2:手写分类数据集,在这个数据集中,包含1797张8*8灰度的图像。每个数据点都是一个数字,共有10种类别(数字0~9)。
数据集3:葡萄酒分类数据集,Wine葡萄酒数据集是来自UCI上面的公开数据集,这些数据是对意大利同一地区种植的葡萄酒进行化学分析的结果,这些葡萄酒来自三个不同的品种。该分析确定了三种葡萄酒中每种葡萄酒中含有的13种成分的数量。从UCI数据库中得到的这个wine数据记录的是在意大利某一地区同一区域上三种不同品种的葡萄酒的化学成分分析。数据里含有178个样本分别属于三个类别,这些类别已经给出。每个样本含有13个特征分量(化学成分),分析确定了13种成分的数量,然后对其余葡萄酒进行分析发现该葡萄酒的分类。在wine数据集中,这些数据包括了三种酒中13种不同成分的数量。文件中,每行代表一种酒的样本,共有178个样本;一共有14列,其中,第一个属性是类标识符,分别是1/2/3来表示,代表葡萄酒的三个分类。后面的13列为每个样本的对应属性的样本值。剩余的13个属性是,酒精、苹果酸、灰、灰分的碱度、镁、总酚、黄酮类化合物、非黄烷类酚类、原花色素、颜色强度、色调、稀释葡萄酒的OD280/OD315、脯氨酸。其中第1类有59个样本,第2类有71个样本,第3类有48个样本。

函数自己实现:
# Read the data from a file, return the header and the data (nominal values)
import numpy as npdef readNominalData(paraFilename):resultData = []tempFile = open(paraFilename)tempLine = tempFile.readline().replace('\n', '')tempNames = np.array(tempLine.split(','))resultNames = [tempValue for tempValue in tempNames]# print("resultNames ", resultNames)# print("resultNames[0] = ", resultNames[0])tempLine = tempFile.readline().replace('\n', '')while tempLine != '':tempValues = np.array(tempLine.split(','))tempArray = [tempValue for tempValue in tempValues]resultData.append(tempArray)tempLine = tempFile.readline().replace('\n', '')# print(resultData)tempFile.close()return resultNames, resultData# Obtain all values of all features (including the decision) as a matrix
def obtainFeaturesValues(paraDataset):resultMatrix = []for i in range(len(paraDataset[0])):featureValues = [example[i] for example in paraDataset]uniqueValues = set(featureValues)# print("uniqueValues = ", uniqueValues)currentValues = [tempValue for tempValue in uniqueValues]# print("currentValues = ", currentValues)resultMatrix.append(currentValues)# print("The values matrix is: ", resultMatrix)return resultMatrix# Calculate class values
def calculateClassCounts(paraData, paraValuesMatrix):classCount = {}tempNumInstances = len(paraData)tempNumClasses = len(paraValuesMatrix[-1])for i in range(tempNumInstances):tempClass = paraData[i][-1]if tempClass not in classCount.keys():classCount[tempClass] = 0classCount[tempClass] += 1resultCounts = np.array(classCount)return resultCounts# Calculate distributions,类概率分布
def calculateClassDistributionLaplacian(paraData, paraValuesMatrix):classCount = {}tempNumInstances = len(paraData)tempNumClasses = len(paraValuesMatrix[-1])for i in range(tempNumInstances):tempClass = paraData[i][-1]if tempClass not in classCount.keys():classCount[tempClass] = 0classCount[tempClass] += 1resultClassDistribution = []for tempValue in paraValuesMatrix[-1]:resultClassDistribution.append((classCount[tempValue] + 1.0) / (tempNumInstances + tempNumClasses))print("tempNumClasses", tempNumClasses)return resultClassDistributiondef calculateMappings(paraValuesMatrix):resultMappings = []for i in range(len(paraValuesMatrix)):tempMapping = {}for j in range(len(paraValuesMatrix[i])):tempMapping[paraValuesMatrix[i][j]] = jresultMappings.append(tempMapping)# print("tempMappings", resultMappings)return resultMappings# Calculate distributions, 计算条件概率
def calculateConditionalDistributionsLaplacian(paraData, paraValuesMatrix, paraMappings):tempNumInstances = len(paraData)tempNumConditions = len(paraData[0]) - 1tempNumClasses = len(paraValuesMatrix[-1])# Step 1. Allocate spacetempCountCubic = []resultDistributionsLaplacianCubic = []for i in range(tempNumClasses):tempMatrix = []tempMatrix2 = []# Over all conditionsfor j in range(tempNumConditions):# Over all valuestempNumValues = len(paraValuesMatrix[j])tempArray = [0.0] * tempNumValuestempArray2 = [0.0] * tempNumValuestempMatrix.append(tempArray)tempMatrix2.append(tempArray2)tempCountCubic.append(tempMatrix)resultDistributionsLaplacianCubic.append(tempMatrix2)# Step 2. Scan the datasetfor i in range(tempNumInstances):tempClass = paraData[i][-1]# print("tempClass = ", tempClass)tempIntClass = paraMappings[tempNumConditions][tempClass]for j in range(tempNumConditions):tempValue = paraData[i][j]tempIntValue = paraMappings[j][tempValue]tempCountCubic[tempIntClass][j][tempIntValue] += 1# Step 3. Calculate the real probability with LaplaciantempClassCounts = [0] * tempNumClassesfor i in range(tempNumInstances):tempValue = paraData[i][-1]tempIntValue = paraMappings[tempNumConditions][tempValue]tempClassCounts[tempIntValue] += 1for i in range(tempNumClasses):# Over all conditionsfor j in range(tempNumConditions):for k in range(len(tempCountCubic[i][j])):resultDistributionsLaplacianCubic[i][j][k] = (tempCountCubic[i][j][k] + 1) / (tempClassCounts[i] + tempNumClasses)# print("tempCountCubic", tempCountCubic)# print("resultDistributionsLaplacianCubic", resultDistributionsLaplacianCubic)return resultDistributionsLaplacianCubic# Classification, 分类
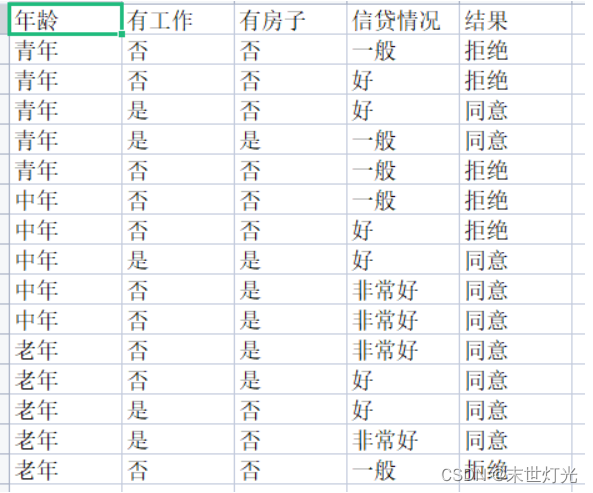
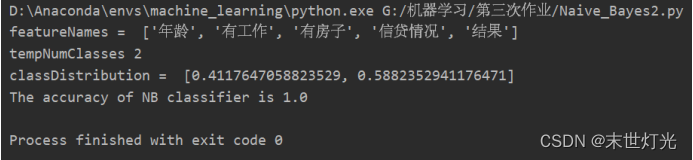
def nbClassify(paraTestData, paraValuesMatrix, paraClassValues, paraMappings, paraClassDistribution,paraDistributionCubic):tempCorrect = 0.0tempNumInstances = len(paraTestData)tempNumConditions = len(paraTestData[0]) - 1tempNumClasses = len(paraValuesMatrix[-1])tempTotal = len(paraTestData)tempBiggest = -1000tempBest = -1# print("paraMapping", paraMappings)# All instancesfor featureVector in paraTestData:# print("featureVector[-1]", featureVector[-1])tempActualLabel = paraMappings[tempNumConditions][featureVector[-1]]# print("tempActualLabel ", tempActualLabel)tempBiggest = -1000tempBest = -1for i in range(tempNumClasses):tempPseudoProbability = np.log(paraClassDistribution[i])for j in range(tempNumConditions):tempValue = featureVector[j]tempIntValue = paraMappings[j][tempValue]tempPseudoProbability += np.log(paraDistributionCubic[i][j][tempIntValue])if tempBiggest < tempPseudoProbability:tempBiggest = tempPseudoProbabilitytempBest = i# Is the prediction correct?# print("tempBest = {} and tempActualLabel = {}".format(tempBest, tempActualLabel))if tempBest == tempActualLabel:tempCorrect += 1return tempCorrect / tempNumInstancesdef mfNBTest(paraFilename):# Step 1. Load the datasetfeatureNames, dataset = readNominalData(paraFilename)# classValues = ['P', 'N']print("featureNames = ", featureNames)# print("dataset = ", dataset)valuesMatrix = obtainFeaturesValues(dataset)tempMappings = calculateMappings(valuesMatrix)classValues = calculateClassCounts(dataset, valuesMatrix)classDistribution = calculateClassDistributionLaplacian(dataset, valuesMatrix)print("classDistribution = ", classDistribution)conditionalDistributions = calculateConditionalDistributionsLaplacian(dataset, valuesMatrix, tempMappings)# print("conditionalDistributions = ", conditionalDistributions)# print("valuesMatrix[0][1] = ", valuesMatrix[0][1])# featureName = ['Outlook', 'Temperature', 'Humidity', 'Windy']# print("Before classification, feature names = ", featureNames)tempAccuracy = nbClassify(dataset, valuesMatrix, classValues, tempMappings, classDistribution,conditionalDistributions)print("The accuracy of NB classifier is {}".format(tempAccuracy))def main():# 统计了14天的气象数据(指标包括outlook,temperature,humidity,windy),# 并已知这些天气是否打球(play)。如果给出新一天的气象指标数据:sunny,cool,high,TRUE,判断一下会不会去打球。#mfNBTest('1.csv')# 动物类别分类#mfNBTest('2.csv')# 个人信息mfNBTest('3.csv')main()
数据集选择以及计算结果:
数据集1:
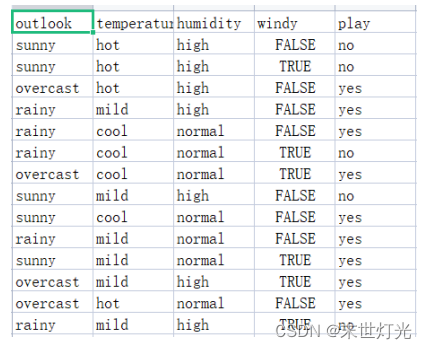
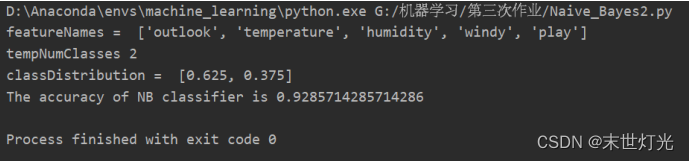
数据集2:
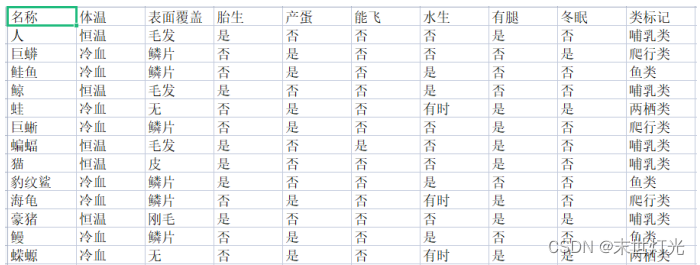

数据集3: