
阻塞式队列、定时器、线程池
1. JUC:多线程的很多类都在 java.util.concurrent 这个包里。
2.一个典型应用场景:生产者消费者模型
特点:
1)应用解耦
解耦
架构设计:高内聚低耦合
耦合:降低两个项目之间的关联程度
高内聚:集中精力,把精力都放在自己的项目上
2)异步提速
3)流量削峰
服务B处理请求的速度完全不影响A,哪怕B瘫痪了,也不影响A,A瘫痪了也不会影响B。
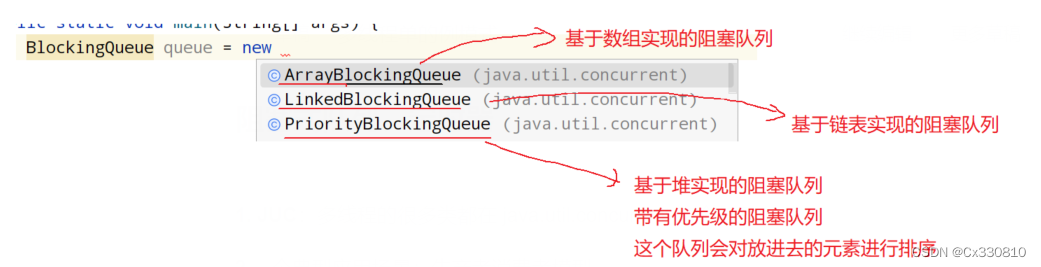
3.阻塞队列
(1)又叫消息队列,kafka / RocketMQ / RabbitMQ
是一个队列(先进先出);线程安全;带有阻塞功能。
JDK也提供了一些阻塞队列的实现。
(2)实现
ps:链表、数组都可以用,数组较简单
4.定时器
(1)到一个时间去执行具体某一个任务。软件开发在中的一个重要组件,类似于一个“闹钟”。
(2)实现
任务以及任务的指向时间;
有一个队列来存储这些任务;(为啥要带优先级呢? --> 因为阻塞队列中的任务都有各自的执行时刻 (delay). 最先执行的任务一定是 delay 最小的. 使用带 优先级的队列就可以高效的把这个 delay 最小的任务找出来.。)
提供一个方法想定时器提交任务;
有一个线程来遍历这个队列,再执行任务。
import java.util.concurrent.BlockingQueue;
import java.util.concurrent.PriorityBlockingQueue;/*** 任务*/
class MyTask implements Comparable{// 使用Runnable 来描述任务private Runnable runnable;//描述任务的执行时间, 采用时间戳private long time;/**** @param runnable* @param after 当前时间后多久开始执行, 单位是ms*/public MyTask(Runnable runnable, long after){this.runnable = runnable;this.time = System.currentTimeMillis() + after;}public void run(){this.runnable.run();}public Runnable getRunnable() {return runnable;}public long getTime() {return time;}/*** 比较两个任务的大小* 按照执行时间去比较* time越小, 任务越小(任务执行的越早, 需要放在队首)* @param o the object to be compared.* @return*/@Overridepublic int compareTo(MyTask o) {return (int) (this.time - o.getTime());}
}/*** 定时器*/
public class MyTimer {//创建一个队列, 来存储任务BlockingQueue queue = new PriorityBlockingQueue<>();Object locker = new Object();/*** 向定时器提交任务* @param task*/public void schedule(MyTask task){try{queue.put(task);synchronized (locker){locker.notify();}}catch (Exception e){e.printStackTrace();}}public MyTimer(){Thread thread = new Thread(()->{try {//取出队首的任务, 判断是否需要执行while (true){MyTask task = queue.take();//如果时间未到, 把任务重新放回队列里//如果时间到了, 就执行if (task.getTime()>System.currentTimeMillis()){queue.put(task);//接下来等待一定的时间synchronized (locker){locker.wait(task.getTime() - System.currentTimeMillis());}}else {task.run();}}}catch (Exception e){e.printStackTrace();}});thread.start();}public static void main(String[] args) {MyTimer myTimer = new MyTimer();myTimer.schedule(new MyTask(()->{System.out.println("执行任务1");},5000));myTimer.schedule(new MyTask(()->{System.out.println("执行任务2");},1000));myTimer.schedule(new MyTask(()->{System.out.println("执行任务3");},3000));}
} 5. 线程池
(1)线程池:
提前创建好了一批线程,放到池子中,当有任务来时,从池子中取出一个线程去执行;任务执行结束时,把线程放回到池子中。(循环使用)
线程比进程快,创建和销毁、调度都快。线程池就可以省略掉创建和销毁的成本。
PS:有关线程池可参考:http://t.csdn.cn/AWJsp
(2)标准库的线程池
corePoolSIze 核心线程数--->正式工的数量(常备线程数)
maximumPoolSize 最大线程数--->正式工+临时工的数量(常备线程数+临时线程数)(任务多了就创建一些临时线程,任务完了就销毁)
keepAliveTime 线程的空闲时间--->临时工干完活后,领导会考察一段时间
TimeUnit unit 时间单位---> s、ms等
workQueue 工作队列--->没临时工时,任务太多了,正式工会做不完,就把任务存储在工作队列
ThreadFactory threadfactor 线程工厂--->用什么取创建线程,如线程的命名,一般使用默认线程工厂就可以
RejectedExcutionHandler handler 拒绝策略---> 任务太多时,要把任务记录下来,记录在本子上,但本子记不下了,就会采取拒绝策略(拒绝任务并抛出异常;由调用者来执行;丢弃更老的任务并把新任务加入;直接丢弃且什么也不做)
(3)线程池的工作流程
1)最开始时,线程池是空的;
2)随着任务的提交开始创建线程(
若当前线程数< corePoolSize,就创建线程;
若前线程数== corePoolSize,就把任务添加到工作队列中;
若队列满了,当前线程数< maximumPoolSize ,创建线程;
若队列满了,当前线程数==maximumPoolSize ,就执行拒绝策略);
3)随着任务的执行,剩余任务逐渐减少,逐渐有利空闲线程(若空闲时间> keepAliveTime 且当前线程数> corePoolSize ,销毁线程,直到当前线程数==corePoolSize)。
(4)线程池的参数设置
一般可分为:
CPU密集型(任务需要大量的CPU来参与运算,任务大多数时间都是CPU来执行):线程数=CPU的核数 或 CPU核数+1
IO密集型:线程数=CPU的核数*(1+CPU等待时间/CPU执行时间)(或有时 2*CPU的核数+1)
PS:上述理论在实际都要以压测为准,压测就是压力测试。
压测:都是QA压测,但QA 几乎没有压测线程的数量。QA是对整个项目负责的,站在整个项目的角度去测试。接口的响应时间(使用多线程的原因就是为了提高接口的响应时间)。CPU的负载情况(QA关注CPU的负载不要超过多少)。
PS:可参考:http://t.csdn.cn/is9Wb
(5)线程池的实现
PS:Excutors,看作一个工具,提供了一些创建线程的方法,这些线程已经有了一些默认的参数配置,就不需要再去写了。ExecutorService,线程池。(Executors 本质上是ThreadPoolExecutor 类的封装。)
1)线程;
2)有一个保存线程的容器;
3)任务;(就使用Runnable 来表示)
4)队列(用来存放任务);
5)需要提供一个方法,往线程池里添加任务
/*** 线程池的实现*/
import java.util.ArrayList;
import java.util.Date;
import java.util.List;
import java.util.concurrent.BlockingQueue;
import java.util.concurrent.LinkedBlockingQueue;class Worker extends Thread{BlockingQueue queue = null;public Worker(BlockingQueue queue){this.queue = queue;}@Overridepublic void run() {//TODO//扫描任务队列, 并执行while (true){try {Runnable runnable = queue.take();runnable.run();}catch (Exception e){e.printStackTrace();}}}
}
public class MyThreadPool {public static void main(String[] args) {MyThreadPool pool = new MyThreadPool(3);//创建3个线程池for (int i = 0; i < 10; i++) {pool.submit(() -> {System.out.println("hello" + new Date());try {Thread.sleep(1000);} catch (InterruptedException e) {e.printStackTrace();}});}}BlockingQueue queue = new LinkedBlockingQueue();List workerList = new ArrayList<>();public MyThreadPool(int corePoolSize){for (int i = 0; i < corePoolSize; i++) {Worker worker = new Worker(queue);worker.start();workerList.add(worker);}}public void submit(Runnable runnable){try {queue.put(runnable);} catch (InterruptedException e) {e.printStackTrace();}}
}
上一篇:MySQL的索引
下一篇:【K8S系列】Pod详解