
论文解读:通过可解释的集成深度学习学习蛋白质组范围内蛋白质-蛋白质结合位点的蛋白质语言
Title:Learning the protein language of proteome-wide protein-protein binding sites via explainable ensemble deep learning.
期刊:communications biology
中科院分区:1区
影像因子:6.548
Github:https://github.com/houzl3416/EDLMPPI
DOI:10.1038/s42003-023-04462-5
WebSever:http://www.edlmppi.top:5002/
摘要
蛋白质-蛋白质相互作用(PPIs)通过显著影响蛋白质的功能表达来控制细胞通路和过程。因此,准确识别蛋白质-蛋白质相互作用结合位点已成为蛋白质功能分析的关键步骤。然而,由于大多数计算方法都是基于生物学特征设计的,因此没有可用的蛋白质语言模型来直接将氨基酸序列编码为分布式向量表示,以模拟蛋白质结合事件的特征。此外,实验检测到的蛋白质相互作用位点数量远远小于蛋白质-蛋白质相互作用位点或蛋白质复合物中的蛋白质位点,导致数据集不平衡,从而为其性能的改进留下了空间。为了解决这些问题,我们开发了一种基于集成深度学习模型(EDLM)的蛋白质-蛋白质相互作用(PPI)位点识别方法(EDLMPPI)。
评估结果表明,在Dset_448、Dset_72和Dset_164三个广泛使用的基准数据集上,EDLMPPI优于包括几种PPI站点预测模型在内的最先进技术,平均精度优于这些PPI站点预测模型近10%。此外,生物学和可解释性分析从不同角度为蛋白质结合位点的鉴定和表征机制提供了新的见解。EDLMPPI web服务器可在http://www.edlmppi.top:5002/上获得
背景
另一方面,已经提出了大量的蛋白质序列编码方法来将蛋白质序列建模为特征矩阵。蛋白质相互作用位点的单热编码是一种非常有效的方法,已被用于许多计算方法10,12。然而,它们不能准确地表达氨基酸之间的功能差异。位置特定评分矩阵(Position-specific scoring matrix, PSSM)经常被用于序列级和残差级预测任务,以描述序列与函数s4,6,10,11,13之间的关系,由于PSSM需要对大型数据库的序列进行比对,因此相对耗时。近年来,自然语言处理中的词嵌入模型的发展为蛋白质编码寻址提供了可能。Word2Vec14、Doc2Vec15、fastText16、GloVe17等词嵌入模型在生物信息学领域得到了广泛的应用;例如,Zeng等6使用基于ProtVec18的静态词嵌入模型对氨基酸进行编码,提高了PPIs预测的准确性。Yang等19提出的iCircRBP-DHN提高了Doc2Vec15对circRNARBP相互作用位点的识别精度。Min等20使用GloVe17作为基因序列的包埋方法进行染色质可及性预测。Hamid21用Word2Vec22表示蛋白质序列,用于区分细菌素。遗憾的是,这种静态词向量嵌入不能很好地捕捉序列和结构之间的关联,忽略了序列上下文之间的潜在联系。为了解决这些限制,以BERT (Bidirectional Encoder representation from Transformers)模型为代表的动态词嵌入在语义分析方面表现出非常好的性能,能够通过双向预训练大规模未标记语料库来学习蛋白质序列的序列上下文BiLSTM26和胶囊网络27,其中BiLSTM可以全面学习蛋白质序列正向和反向的特征,胶囊网络可以进一步发现特征之间的相关性。为了应对不平衡数据集的影响,我们训练多个深度学习模型来形成集成深度学习,然后进行预测。为了研究我们提出的EDLMPPI的有效性,我们对网络机制和特征提取部分进行了实验。所有实验都是基于“方法”一节中描述的训练和测试集。验证集随机token为训练集的20%,我们也采用分层随机抽样的方法对验证集进行划分,以保证训练集和验证集分布的一致性。为了验证EDLMPPI的有效性,我们将其与基准数据集上的十种不同的机器学习模型和深度学习模型进行了比较。此外,我们还将EDLMPPI与其他PPI站点预测模型进行了比较,结果表明EDLMPPI的站点预测能力遥遥领先,验证了EDLMPPI的特征提取和网络架构的有效性。为了探究EDLMPPI的生物学意义,我们提取了蛋白序列的结构域。与其他方法相比,EDLMPPI预测的相互作用位点与结构域中的原生位点具有更高的相关性。此外,我们进行了可解释的分析,以说明EDLMPPI的特征表示的内部过程。我们在http://www.edlmppi.top:5002/上为EDLMPPI预测构建了一个web服务器。
方法和数据集
数据集
对于数据集,我们收集了三个广泛使用的基准数据集,Dset_18654, Dset_7254和Dset_16455。Dset_186由PDB数据库3构建,包含186个蛋白序列,分辨率<3.0 Å,序列同源性<25%。该数据集经过多个步骤的细化,包括去除具有相同UniprotKB/Swiss-Prot序列的链,去除跨膜蛋白,去除二聚体结构,去除表面可达性和界面极性埋藏在一定范围内的蛋白质,以及去除相似性。Dset_72和Dset_164的构建方法与Dset_186相同,分别由72个和186个蛋白质序列组成。
Dset_1291是来自BioLip数据库的数据集,如果一个残基的一个原子和一个给定蛋白质伙伴的原子之间的距离为0.5 Å加上两个原子的范德华半径之和13,则定义了一个结合位点。Zhang等13剔除碎片化蛋白,将结合残基的注释转移到相同的UniProt序列上。因此,Blast-Clust方法将序列之间的相似性降低到25%以下。
最后使用Dset_843 (Dset_1291中的843个序列)来训练我们的模型,其余448个序列(Dset_448)作为独立的测试集。
使用这些数据集,我们构建了训练集和测试集。由于Dset_843和Dset_448完全由全长蛋白质序列组成,而Dset_71、Dset_186和Dset_164是由片段序列组成;为了增强模型的可泛化性,我们分别选择代表两种不同类型数据集的Dset_843和Dset_186作为我们的训练数据集。然后将Dset_448、Dset_72和Dset_164作为独立的测试集,测试不同PPI站点预测模型的性能。此外,为了降低训练集和测试集之间的相似性,我们使用PSI-BlAST56程序进行一致性冗余去除,以确保相似性低于25%。表1总结了每个数据集中蛋白质残基的数量和结合位点的比例,从中不难看出数据集的分布相对不平衡,阳性样本仅占总样本量的10-18%,这对模型的泛化性提出了挑战。
方法
胶囊网络
集成深度记忆胶囊网络。为了更有效地捕获混合特征方案中的关键信息,我们开发了集成深度记忆胶囊网络(EDMCN),以最大限度地提高蛋白质-蛋白质相互作用位点识别的特征学习性能,如图1所示。深度记忆胶囊网络扩展了传统记忆网络的并行性,将它们与不同的输出大小连接起来,以捕获不同深度尺度上氨基酸之间的相关性。此外,胶囊结构可以进一步挖掘特征之间的内在联系,保留样本之间的位置信息。此外,为了提高模型的泛化性和稳定性,我们引入了非对称bagging算法来解决样本间高度不平衡的问题。
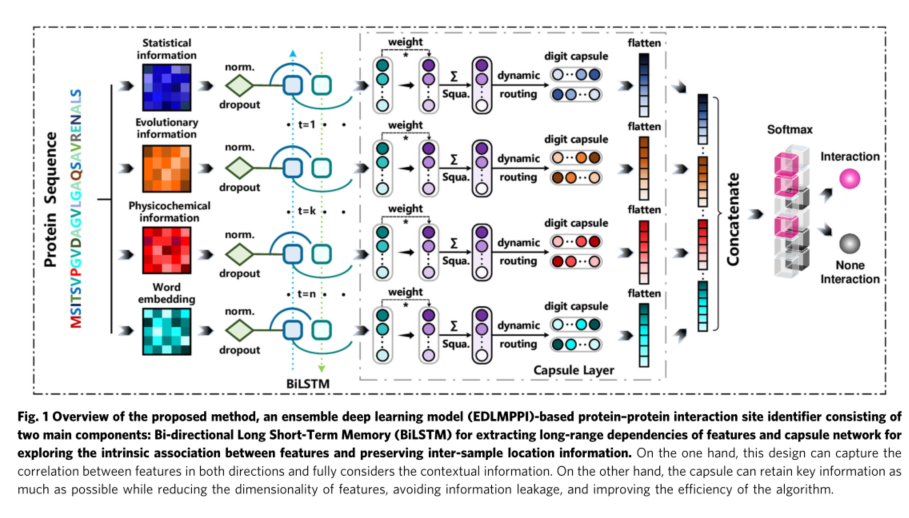
深度学习
对于EDLMPPI,我们使用tanh函数作为激活函数,采用均匀分布的gloriot初始化器初始化BiLSTM部分的权重。然后,对于隐藏层的神经元数量,我们固定一组候选值[32,64,128,256]。对于胶囊网络,主要的超参数是神经胶囊的数量和每个神经元向量的维数,我们分别设置了一组候选值[32,64,128,256]和[3,5,7,10]。为了获得最好的超参数,我们在Tensorflow 2.5.0和Keras 2.4.3下通过网格搜索方法对上述三组候选值进行优化。将epoch设置为100,并应用提前停止机制来防止算法的过拟合。
为了与TextCNN38、Single-Capsule27、BiLSTM39、BiGRU40、MultiHead Attention41等深度学习算法进行公平的比较,超参数优化方法采用了与EDLMPPI相同的原理;我们还采用了与EDLMPPI相同的超参数优化方法规则,使用网格搜索程序来选择合理的超参数。对于TextCNN,不同大小的卷积核的不同组合的测试设置为{{1,3,5,7},{7,9,11,13},{4,5,6,7},{7,8,9,10}},其中每种组合的过滤器数量分别从16,32,64,128中选择。BiLSTM和BiGRU的隐层单元格数从{32,64,128}中选择。在胶囊网络中,神经胶囊的数量和每个神经元向量的维数的候选值为{32,64,128,256}和{3,5,7,10},分别。最后,Multi-Head注意网络从{4,8,16,32}中选择注意头数。
机器学习
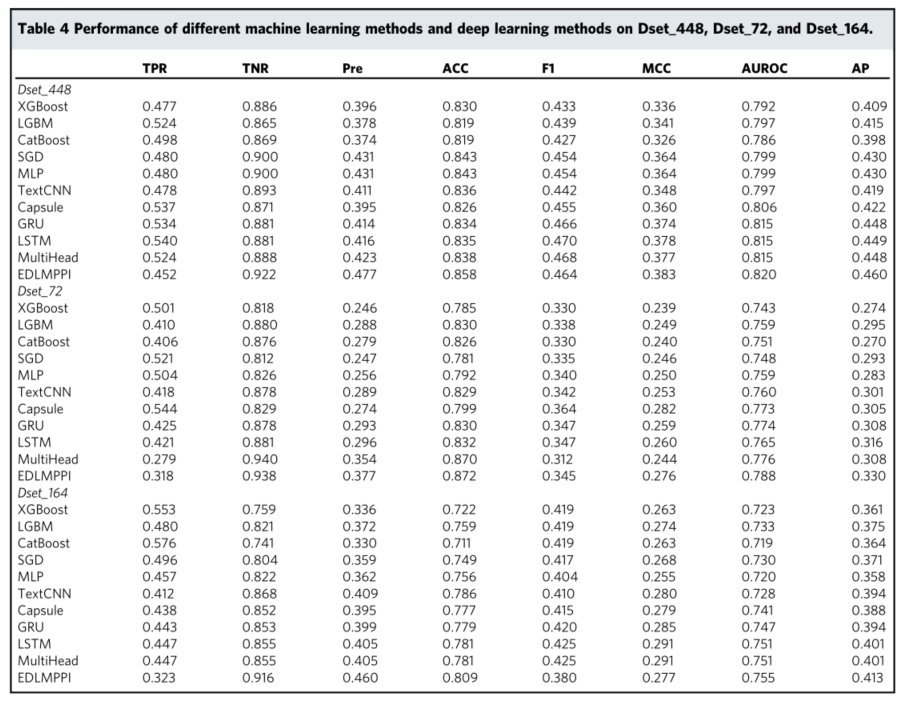
机器学习方法包含三种集成学习方法(XGBoost35、LightGBM36和CatBoost37)、SGDClassifier(随机梯度下降)和MLPClassifier(多层感知器),它们在Python环境中的scikit-learn60依赖包下。XGBoost采用逐级决策树构建策略,LightGBM使用逐叶构建策略,CatBoost应用具有全二叉决策树的对称树结构。sgd分类器是一个具有正则化线性方法的随机梯度下降学习模型。每次估计每个样品的损失梯度,并在此过程中使用强度递减时间表更新模型。MLP是一种前向结构的人工神经网络,可以快速解决复杂问题。网格搜索过程也用于为这五个分类器找到最优超参数。候选参数和最优参数组合汇总在补充表2中。
结果与讨论
EDLMPPI可以提供一种更有效的蛋白质序列表征方案。在我们的研究中,我们采用多通道策略,分别以MBF (Multisource Biological features,包括蛋白质残基的进化信息、物理性质和物理化学性质)和ProtT5作为模型的输入,形成组合特征。
然后,在softmax分类层之前,将两组向量进行级联和归一化。在MBF中,采用滑动窗口机制对每个残基的局部上下文信息进行编码,可以有效防止过拟合,提高模型的泛化性。当窗口大小为n (n为奇数)时,最中间的氨基酸为要预测的目标氨基酸,滑动步长为1。因此,我们首先从{5,11,15,21,25,33}集合中评估不同窗口大小的MBF模型的性能,从而进行MBF中最优窗口大小的实验。以Dset_448为例,不同窗口大小的实验结果如图2a所示。很明显,该模型在窗口大小为25的情况下,通过包括AP、AUROC和MCC在内的几个关键指标来衡量,获得了最佳性能。然而,当窗口大小为31时,算法的整体性能会下降,这表明窗口越大并不总是越好。因此,在我们的研究中,我们选择25作为最终的窗口大小。
此外,为了进一步研究我们提出的特征描述符的优越性,我们分别将EDLMPPI中的组合特征与包括MBF和ProtT5在内的单个特征描述符进行了比较。实验结果如表1和图2b所示。可以观察到,结合MBF和ProtT5的特征在所有三个数据集上的表现都大大优于单独的特征描述符。事实上,对于经常用于评估不平衡数据的评估指标AP,组合特征在三个数据集上分别超过MBF,并分别优于ProtT5 1.8%, 3%和2.9%,表明组合特征丰富了蛋白质表达并增强了模型的性能。
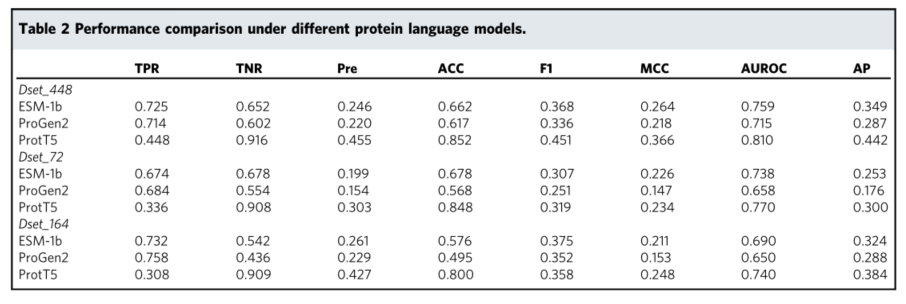
此外,当比较Prot5和MBF时,还可以发现Prot5的AP值在这三个数据集上表现得更好,在AUROC上分别比MBF高出10.7%、11.2%和8.6%,揭示了动态词嵌入在蛋白质-蛋白质结合位点预测中的有效性。原因可能是ProtT5从我们标记的训练数据中更好地捕获了氨基酸之间的差异(结合位点和非结合位点),而MBF难以根据进化信息和其他生物学功能区分氨基酸特异性。
蛋白质结合域分析。蛋白质结构域与蛋白质生理功能的完成密切相关,是蛋白质细胞功能的结构基础50。为了深入了解蛋白质结构域和蛋白质-蛋白质相互作用位点之间的潜在关系,我们进行了一个实验来验证EDLMPPI是否能准确预测蛋白质结构域中的PPIs。我们利用Pfam51对Dset_448数据集中的448个蛋白质序列进行注释,去除重叠的结构域,最终得到501个结构域。图3b显示了每个尺寸的结构域与其中ppi数量的对应关系,我们比较了EDLMPPI、DELPHI和SCRIBER13的预测结果。此外,为了增强实验的合理性,我们增加了一个对照组:从序列中随机选取一个与蛋白质结构域大小相同的片段。从结果来看,EDLMPPI的预测结果比其他两种方法更为乐观,随着结构域的增大,EDLMPPI预测的PPIs数量增加。根据之前的一项研究52,长度偏差结构域超家族具有高度相互作用,功能更加混合,并受多种蛋白质调控,这支持了EDLMPPI预测蛋白质功能的合理性。此外,我们计算了EDLMPPI、DELPHI和SCRIBER对每个结构域估计的预测PPIs的比例,并计算了与真实比例向量的Pearson相关系数。EDLMPPI与原生注释的相关性最高,得分为0.70,而DELPHI、SCRIBER和对照组的相关性分别为0.63、0.57和0.21。
为了进一步证明EDLMPPI能够准确预测蛋白质结构域结合位点的性能,我们选择了三种具有高催化活性的酶蛋白P19821 DPO1_THEAQ, P9WHH9 - DLDH_MYCTU和P17109 MEND_ECOLI来验证不同方法预测性能的差异。由于SCRIBER和DELPHI在PPI位点预测中比其他PPI位点预测模型具有更好的预测效果,因此我们将这三个序列种的SCRIBER和DELPHI预测结果进行比较,结果如表6所示。P19821 DPO1_THEAQ的蛋白质结构域大小为337,实验检测到的PPIs的真实数量为31个,EDLMPPI的预测为36个,与SCRIBER和DELPHI的真实数量更接近。这