
spark第三章:工程化代码
系列文章目录
spark第一章:环境安装
spark第二章:sparkcore实例
spark第三章:工程化代码
文章目录
- 系列文章目录
- 前言
- 一、三层架构
- 二、拆分WordCount
- 1.三层拆分
- 2.代码抽取
- 总结
前言
我们上一次博客,完成了一些案例的练习,现在我要要进行一些结构上的完善,上一次的案例中,代码的耦合性非常高,想要修改就十分复杂,而且有很多代码都在重复使用,我们想要把一些重复的代码抽取出来,进而完成解耦合的操作,提高代码的复用。
一、三层架构
大数据的三层架构其中包括
controller(控制层):负责调度各模块
service(服务层):存放逻辑代码
dao(持久层):进行文件交互
现在我们分别给各层创建一个包
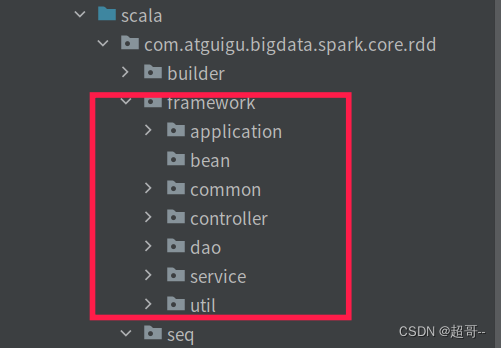
解释一下其中几个
application:项目的启动文件
bean:存放实体类
common:存放这个项目的通用代码
util:存放通用代码(所有项目均可)
二、拆分WordCount
万物皆可WordCount我们就以上次的WordCount为例操作。放一下源代码
object WordCount {def main(args: Array[String]): Unit = {// 创建 Spark 运行配置对象val sparkConf: SparkConf = new SparkConf().setMaster("local[*]").setAppName("WordCount")// 创建 Spark 上下文环境对象(连接对象)val sc : SparkContext = new SparkContext(sparkConf)// 读取文件 获取一行一行的数据val lines: RDD[String] = sc.textFile("datas/word.txt")// 将一行数据进行拆分val words: RDD[String] = lines.flatMap(_.split(" "))// 将数据根据单次进行分组,便于统计val wordToOne: RDD[(String, Int)] = words.map(word => (word, 1))// 对分组后的数据进行转换val wordToSum: RDD[(String, Int)] = wordToOne.reduceByKey(_ + _)// 打印输出val array: Array[(String, Int)] = wordToSum.collect()array.foreach(println)sc.stop()}}
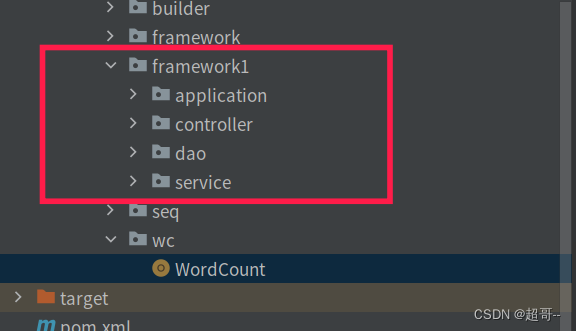
1.三层拆分
在进行数据抽取之前,我们先进行简单的三层架构拆分
记得把包名路径换成自己的
WordCountDao.scala
负责文件交互,也就是第一步的读取文件
package com.atguigu.bigdata.spark.core.rdd.framework1.daoimport com.atguigu.bigdata.spark.core.rdd.framework1.application.WordCountApplication.scclass WordCountDao {def readFile(path:String) ={sc.textFile(path)}
}
WordCountService.scala
负责逻辑运算
package com.atguigu.bigdata.spark.core.rdd.framework1.serviceimport com.atguigu.bigdata.spark.core.rdd.framework1.dao.WordCountDaoimport org.apache.spark.rdd.RDDclass WordCountService {private val wordCountDao =new WordCountDao()def dataAnalysis(): Array[(String, Int)] ={val lines: RDD[String] =wordCountDao.readFile("datas/word.txt")val words: RDD[String] = lines.flatMap(_.split(" "))val wordToOne: RDD[(String, Int)] = words.map(word => (word, 1))val wordToSum: RDD[(String, Int)] = wordToOne.reduceByKey(_ + _)val array: Array[(String, Int)] = wordToSum.collect()array}
}
WordCountController.scala
负责调度项目
package com.atguigu.bigdata.spark.core.rdd.framework1.controllerimport com.atguigu.bigdata.spark.core.rdd.framework1.service.WordCountServiceclass WordCountController {private val wordCountService =new WordCountService()def dispath(): Unit ={val array=wordCountService.dataAnalysis()array.foreach(println)}
}
WordCountApplication.scala
main方法启动项目
package com.atguigu.bigdata.spark.core.rdd.framework1.applicationimport com.atguigu.bigdata.spark.core.rdd.framework1.controller.WordCountController
import org.apache.spark.{SparkConf, SparkContext}object WordCountApplication extends App {val sparkConf: SparkConf = new SparkConf().setMaster("local[*]").setAppName("WordCount")val sc : SparkContext = new SparkContext(sparkConf)val controller = new WordCountController()controller.dispath()sc.stop()
}
2.代码抽取
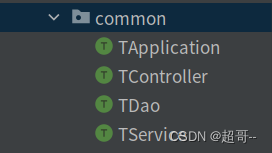
接下来我们把一些常用或者会重复实用的代码抽取出来。
创建四个Train,用来抽取四个文件
TApplication.scala
其中通用代码为环境创建
package com.atguigu.bigdata.spark.core.rdd.framework.commonimport com.atguigu.bigdata.spark.core.rdd.framework.util.EnvUtil
import org.apache.spark.{SparkConf, SparkContext}trait TApplication {def start(master: String="local[*]", app: String="Application")(op: =>Unit): Unit ={val sparkConf: SparkConf = new SparkConf().setMaster(master).setAppName(app)val sc : SparkContext = new SparkContext(sparkConf)EnvUtil.put(sc)try {op}catch {case ex=>println(ex.getMessage)}sc.stop()EnvUtil.clear()}
}TController.scala
定义调度Train之后由Controller进行重写
package com.atguigu.bigdata.spark.core.rdd.framework.commontrait TController {def dispatch():Unit
}
TDao.scala
WordCount通用读取,路径为参数
package com.atguigu.bigdata.spark.core.rdd.framework.commonimport com.atguigu.bigdata.spark.core.rdd.framework.util.EnvUtil
import org.apache.spark.rdd.RDDtrait TDao {def readFile(path:String): RDD[String] ={EnvUtil.take().textFile(path)}
}TService.scala
和Controller类似,由Service重写
package com.atguigu.bigdata.spark.core.rdd.framework.commontrait TService {def dataAnalysis():Any
}
定义环境,确保所有类都能访问sc线程
EnvUtil.scala
package com.atguigu.bigdata.spark.core.rdd.framework.utilimport org.apache.spark.SparkContextobject EnvUtil {private val scLocal =new ThreadLocal[SparkContext]()def put(sc:SparkContext): Unit ={scLocal.set(sc)}def take(): SparkContext = {scLocal.get()}def clear(): Unit ={scLocal.remove()}
}
修改三层架构
WordCountApplication.scala
package com.atguigu.bigdata.spark.core.rdd.framework.applicationimport com.atguigu.bigdata.spark.core.rdd.framework.common.TApplication
import com.atguigu.bigdata.spark.core.rdd.framework.controller.WordCountControllerobject WordCountApplication extends App with TApplication{start(){val controller = new WordCountController()controller.dispatch()}}WordCountController.scala
package com.atguigu.bigdata.spark.core.rdd.framework.controllerimport com.atguigu.bigdata.spark.core.rdd.framework.common.TController
import com.atguigu.bigdata.spark.core.rdd.framework.service.WordCountServiceclass WordCountController extends TController{private val WordCountService = new WordCountService()def dispatch(): Unit ={val array: Array[(String, Int)] = WordCountService.dataAnalysis()array.foreach(println)}
}
WordCountDao.scala
package com.atguigu.bigdata.spark.core.rdd.framework.daoimport com.atguigu.bigdata.spark.core.rdd.framework.common.TDaoclass WordCountDao extends TDao{}WordCountService.scala
package com.atguigu.bigdata.spark.core.rdd.framework.serviceimport com.atguigu.bigdata.spark.core.rdd.framework.common.TService
import com.atguigu.bigdata.spark.core.rdd.framework.dao.WordCountDao
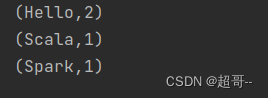
import org.apache.spark.rdd.RDDclass WordCountService extends TService{private val wordCountDao=new WordCountDao()def dataAnalysis(): Array[(String, Int)] = {val lines: RDD[String] = wordCountDao.readFile("datas/word.txt")val words: RDD[String] = lines.flatMap(_.split(" "))val wordToOne: RDD[(String, Int)] = words.map(word => (word, 1))val wordToSum: RDD[(String, Int)] = wordToOne.reduceByKey(_ + _)val array: Array[(String, Int)] = wordToSum.collect()array}}再次运行
总结
对spark项目代码的规范就到这里,确实有点复杂,我也不知道说清楚没有。