
批量下载文档有救了:Python下载某网站文档保存PDF
创始人
2025-05-31 14:36:02
0次
人生苦短,我用python
最近毕业季要做毕业设计的同学真的特别多
需要大量文献、文档、PDF但是不想因为这个花money的
举起你们的双手!!!
接下来就以某度某库为例,
下载我们想要的文档并保存为PDF!
源码资料电子书:点击此处跳转文末名片获取
基本开发环境💨
Python 3.6
Pycharm
相关模块的使用💨
import requests
import parsel
import re
import os
import pdfkit
安装Python并添加到环境变量,
pip安装需要的相关模块即可。
需要使用到一个软件
wkhtmltopdf
这个软件的作用就是把html文件转成PDF
想要把文档内容保存成PDF,
首先保存成html文件,
然后把html文件转PDF

💥需求数据来源分析

网站分类有比较多种,
也可以选择自己要爬取的。
这个网站如果你只是正常直接去复制文章内容的话,
会直接弹出需要money的窗口…

但是这个网站上面的数据内容又非常好找,
因为网站本身仅仅只是静态网页数据,
可以直接获取相关的内容。

通过上述内容,
如果想要批量下载文章内容,
获取每篇文章的url地址即可,
想要获取每篇文章的url地址,
这就需要去文章的列表页面找寻相关的数据内容了。


💥整体思路
- 发送请求,对于文章列表url地址发送请求
- 获取数据,获取网页源代码数据内容
- 解析数据,提取文章url地址
- 发送请求,对于文章url地址发送请求
- 获取数据,获取网页源代码数据内容
- 解析数据,提取文章标题以及文章内容
- 保存数据,把获取的数据内容保存成PDF
- 转成PDF文件
💥代码实现
import requests
import parsel
import re
import os
import pdfkithtml_filename = 'html\\'
if not os.path.exists(html_filename):os.mkdir(html_filename)pdf_filename = 'pdf\\'
if not os.path.exists(pdf_filename):os.mkdir(pdf_filename)html_str = """
Document
{article}
"""def change_title(name):pattern = re.compile(r"[\/\\\:\*\?\"\<\>\|]") # '/ \ : * ? " < > |'new_title = re.sub(pattern, "_", name) # 替换为下划线return new_titlefor page in range(1, 11):print(f'正在爬取第{page}页数据内容')url = f'https:/自己替换一下/zlist-55-{page}.html'headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36'}response = requests.get(url=url, headers=headers)href = re.findall('', response.text)for index in href:response_1 = requests.get(url=index, headers=headers)selector = parsel.Selector(response_1.text)title = selector.css('.content-page-header-div h1::text').get()title = change_title(title)content = selector.css('.content-page-main-content-div').get()article = html_str.format(article=content)html_path = html_filename + title + '.html'pdf_path = pdf_filename + title + '.pdf'try:with open(html_path, mode='w', encoding='utf-8') as f:f.write(article)# exe 文件存放的路径config = pdfkit.configuration(wkhtmltopdf='C:\\Program Files\\wkhtmltopdf\\bin\\wkhtmltopdf.exe')# 把 html 通过 pdfkit 变成 pdf 文件pdfkit.from_file(html_path, pdf_path, configuration=config)print(f'{title}保存成功...')except:pass
💥实现效果
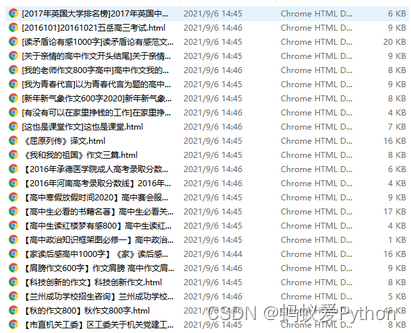



相关内容
热门资讯
电视安卓系统哪个品牌好,哪家品...
你有没有想过,家里的电视是不是该升级换代了呢?现在市面上电视品牌琳琅满目,各种操作系统也是让人眼花缭...
安卓会员管理系统怎么用,提升服...
你有没有想过,手机里那些你爱不释手的APP,背后其实有个强大的会员管理系统在默默支持呢?没错,就是那...
安卓系统软件使用技巧,解锁软件...
你有没有发现,用安卓手机的时候,总有一些小技巧能让你玩得更溜?别小看了这些小细节,它们可是能让你的手...
安卓系统提示音替换
你知道吗?手机里那个时不时响起的提示音,有时候真的能让人心情大好,有时候又让人抓狂不已。今天,就让我...
安卓开机不了系统更新
手机突然开不了机,系统更新还卡在那里,这可真是让人头疼的问题啊!你是不是也遇到了这种情况?别急,今天...
安卓系统中微信视频,安卓系统下...
你有没有发现,现在用手机聊天,视频通话简直成了标配!尤其是咱们安卓系统的小伙伴们,微信视频功能更是用...
安卓系统是服务器,服务器端的智...
你知道吗?在科技的世界里,安卓系统可是个超级明星呢!它不仅仅是个手机操作系统,竟然还能成为服务器的得...
pc电脑安卓系统下载软件,轻松...
你有没有想过,你的PC电脑上安装了安卓系统,是不是瞬间觉得世界都大不一样了呢?没错,就是那种“一机在...
电影院购票系统安卓,便捷观影新...
你有没有想过,在繁忙的生活中,一部好电影就像是一剂强心针,能瞬间让你放松心情?而我今天要和你分享的,...
安卓系统可以写程序?
你有没有想过,安卓系统竟然也能写程序呢?没错,你没听错!这个我们日常使用的智能手机操作系统,竟然有着...
安卓系统架构书籍推荐,权威书籍...
你有没有想过,想要深入了解安卓系统架构,却不知道从何下手?别急,今天我就要给你推荐几本超级实用的书籍...
安卓系统看到的炸弹,技术解析与...
安卓系统看到的炸弹——揭秘手机中的隐形威胁在数字化时代,智能手机已经成为我们生活中不可或缺的一部分。...
鸿蒙系统有安卓文件,畅享多平台...
你知道吗?最近在科技圈里,有个大新闻可是闹得沸沸扬扬的,那就是鸿蒙系统竟然有了安卓文件!是不是觉得有...
宝马安卓车机系统切换,驾驭未来...
你有没有发现,现在的汽车越来越智能了?尤其是那些豪华品牌,比如宝马,它们的内饰里那个大屏幕,简直就像...
p30退回安卓系统
你有没有听说最近P30的用户们都在忙活一件大事?没错,就是他们的手机要退回安卓系统啦!这可不是一个简...
oppoa57安卓原生系统,原...
你有没有发现,最近OPPO A57这款手机在安卓原生系统上的表现真是让人眼前一亮呢?今天,就让我带你...
安卓系统输入法联想,安卓系统输...
你有没有发现,手机上的输入法真的是个神奇的小助手呢?尤其是安卓系统的输入法,简直就是智能生活的点睛之...
怎么进入安卓刷机系统,安卓刷机...
亲爱的手机控们,你是否曾对安卓手机的刷机系统充满好奇?想要解锁手机潜能,体验全新的系统魅力?别急,今...
安卓系统程序有病毒
你知道吗?在这个数字化时代,手机已经成了我们生活中不可或缺的好伙伴。但是,你知道吗?即使是安卓系统,...
奥迪中控安卓系统下载,畅享智能...
你有没有发现,现在汽车的中控系统越来越智能了?尤其是奥迪这种豪华品牌,他们的中控系统简直就是科技与艺...