
学不会的python之通过某几个关键字排序、分组一个字典列表(列表中嵌套字典)
创始人
2024-04-23 20:22:20
0次
通过某个关键字排序、分组一个字典列表
- 排序
- 问题描述
- 解决方案
- 1.operator 模块的 itemgetter 函数
- 2.lambda 表达式
- 引申
- 分组
- 问题描述
- 解决方案
- 1.itertools.groupby() 函数
- 2.defaultdict() 构建多值字典
排序
问题描述
- 现在你有一个字典列表(列表中嵌套字典),你想要根据某个或某几个字典的字段来排序整个列表,如下:
rows = [{'fname': 'Brian', 'lname': 'Jones', 'uid': 1003},{'fname': 'David', 'lname': 'Beazley', 'uid': 1002},{'fname': 'John', 'lname': 'Cleese', 'uid': 1001},{'fname': 'Big', 'lname': 'Jones', 'uid': 1004}
]
解决方案
1.operator 模块的 itemgetter 函数
- operator.itemgetter() 函数有一个被 rows 中的记录用来查找值的索引参数。可以是一个字典键的键,一个整形值或者任何能够传入一个对象的 getitem () 方法的值
- 如果你传入多个索引参数给 itemgetter() ,它生成的 callable 对象会返回一个包含所有元素值的元组,并且 sorted() 函数会根据这个元组中元素顺序去排序。但你想要同时在几个字段上面进行排序 (比如通过姓和名来排序,也就是例子中的那样) 的时候这种方法也是很有用的
如下举例:
- 通过uid排序
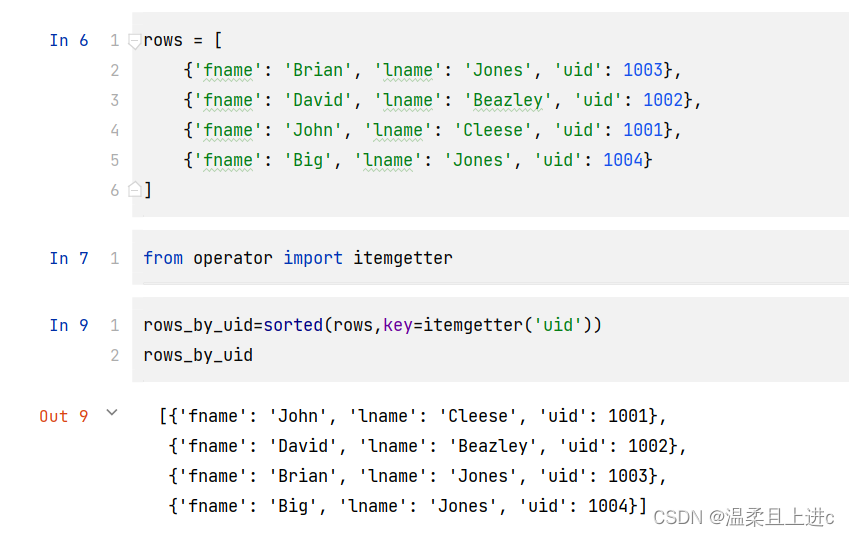
from operator import itemgetterrows_by_uid=sorted(rows,key=itemgetter('uid'))
- 通过姓、名进行排序
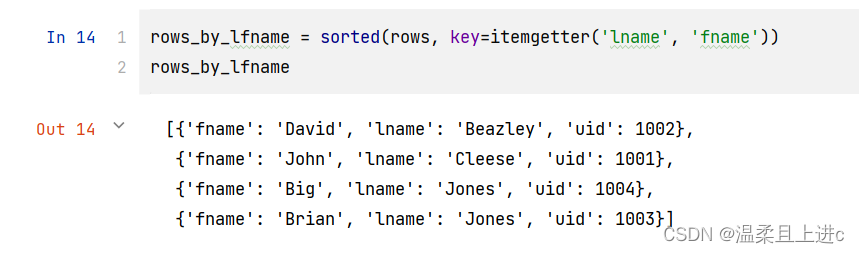
rows_by_lfname = sorted(rows, key=itemgetter('lname', 'fname'))
2.lambda 表达式
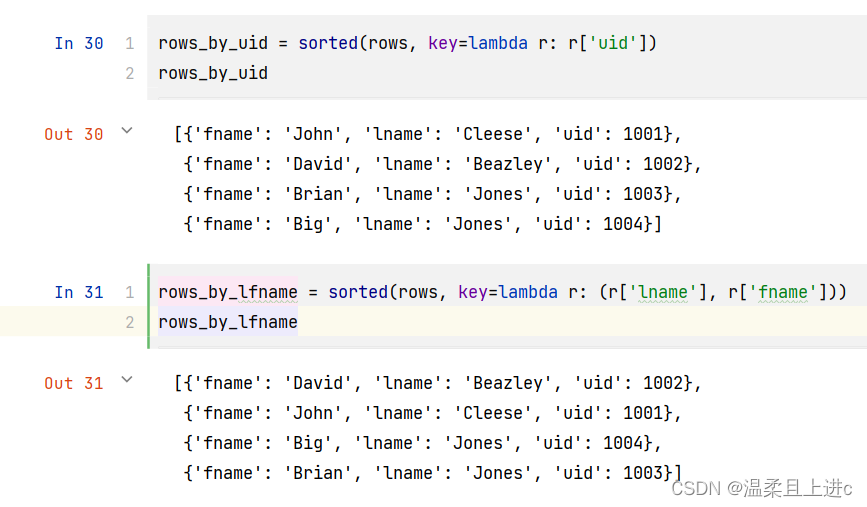
rows_by_uid = sorted(rows, key=lambda r: r['uid'])
rows_by_lfname = sorted(rows, key=lambda r: (r['lname'], r['fname']))
引申
- 上述所使用到的技巧也是适用于min()和max()等函数,如下举例:
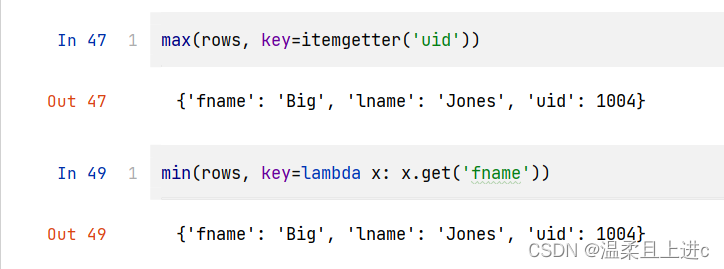
max(rows, key=itemgetter('uid'))
min(rows, key=lambda x: x.get('fname'))
分组
问题描述
- 现在你有一个字典列表(列表中嵌套字典),你想要根据某个或某几个字典的字段来将整个列表进行分组,如下:
rows = [{'address': '5412 N CLARK', 'date': '07/01/2012'},{'address': '5148 N CLARK', 'date': '07/04/2012'},{'address': '5800 E 58TH', 'date': '07/02/2012'},{'address': '2122 N CLARK', 'date': '07/03/2012'},{'address': '5645 N RAVENSWOOD', 'date': '07/02/2012'},{'address': '1060 W ADDISON', 'date': '07/02/2012'},{'address': '4801 N BROADWAY', 'date': '07/01/2012'},{'address': '1039 W GRANVILLE', 'date': '07/04/2012'},
]
解决方案
1.itertools.groupby() 函数
-
将上述的字典列表进行分组,首先需要将其进按照需要分组的字段进行排序,然后在使用itertools.groupby() 函数进行分组
-
groupby() 函数扫描整个序列并且查找连续相同值 (或者根据指定 key 函数返回值相同) 的元素序列。在每次迭代的时候,它会返回一个值和一个迭代器对象,这个迭代器对象可以生成元素值全部等于上面那个值的组中所有对象
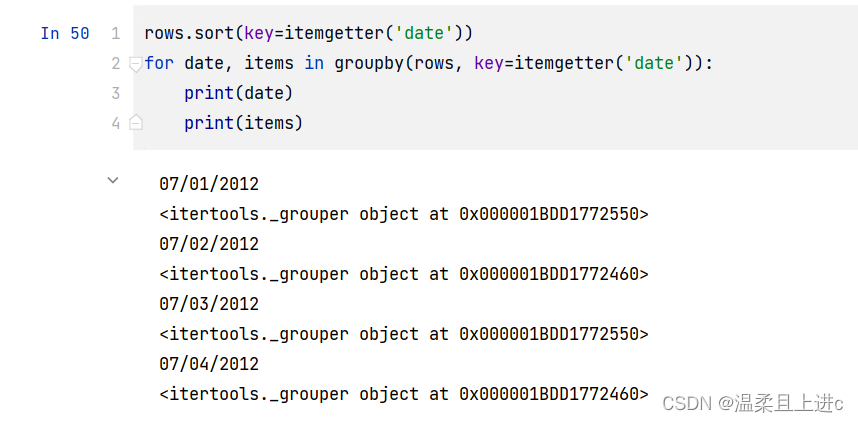
-
一个非常重要的准备步骤是要根据指定的字段将数据排序。因为 groupby() 仅仅检查连续的元素,如果事先并没有排序完成的话,分组函数将得不到想要的结果
如下举例:
- 按照日期date进行分组
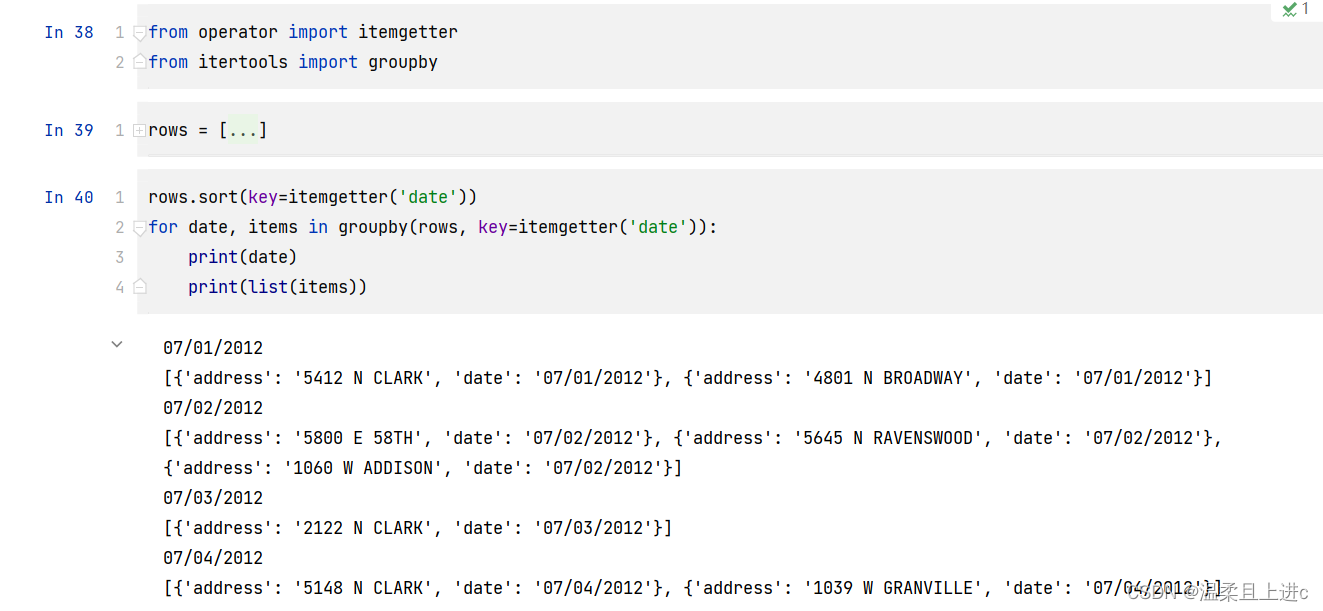
from operator import itemgetter
from itertools import groupbyrows = [{'address': '5412 N CLARK', 'date': '07/01/2012'},{'address': '5148 N CLARK', 'date': '07/04/2012'},{'address': '5800 E 58TH', 'date': '07/02/2012'},{'address': '2122 N CLARK', 'date': '07/03/2012'},{'address': '5645 N RAVENSWOOD', 'date': '07/02/2012'},{'address': '1060 W ADDISON', 'date': '07/02/2012'},{'address': '4801 N BROADWAY', 'date': '07/01/2012'},{'address': '1039 W GRANVILLE', 'date': '07/04/2012'},
]# 排序(上面已经讲过了)
rows.sort(key=itemgetter('date'))
# 分组
for date, items in groupby(rows, key=itemgetter('date')):print(date)print(list(items))
2.defaultdict() 构建多值字典
- 如果你仅仅只是想根据 date 字段将数据分组到一个大的数据结构中去,并且允许随机访问
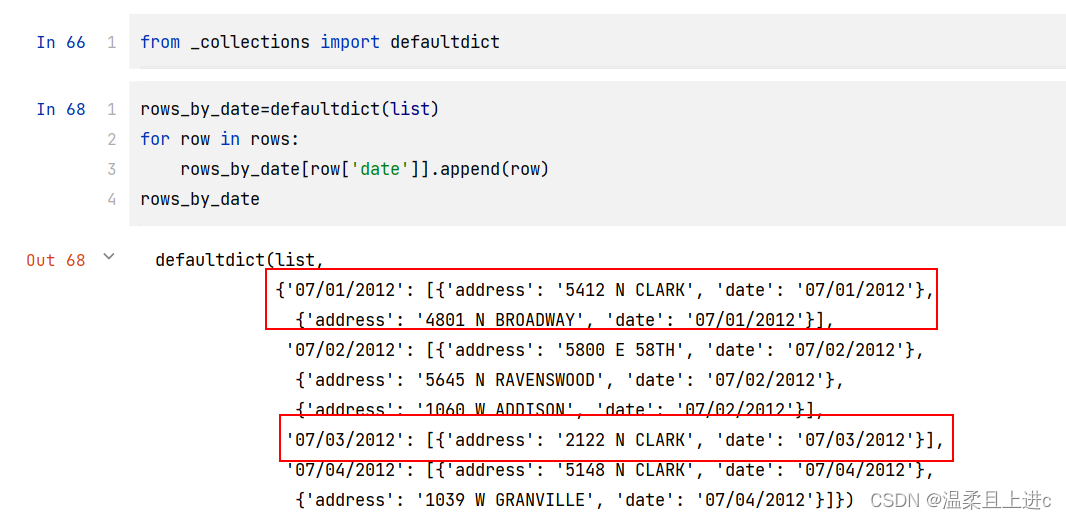
from _collections import defaultdictrows_by_date=defaultdict(list)
for row in rows:rows_by_date[row['date']].append(row)
print(rows_by_date)
- 在这个这个例子中,我们没有必要先将记录排序。因此,如果对内存占用不是很关心,这种方式会比先排序然后再通过 groupby() 函数迭代的方式运行得快一些
上一篇:Linux基本命令(3)
下一篇:有关Monaco的使用疑惑
相关内容
热门资讯
我来教大家“掼蛋大师辅助器ap...
亲,掼蛋大师这款游戏可以开挂的,确实是有挂的,。但是开挂要下载第三方辅助软件,掼蛋大师的开挂软件,名...
我来教大家“开心联盟辅助器ap...
您好,开心联盟这款游戏可以开挂的,确实是有挂的,需要了解加微{7198902}很多玩家在这款游戏中打...
我来教大家“友愉棋牌辅助器ap...
您好,友愉棋牌这款游戏可以开挂的,确实是有挂的,需要了解加微{7198902}很多玩家在这款游戏中打...
我来教大家“全盛棋牌辅助器ap...
亲,全盛棋牌这款游戏可以开挂的,确实是有挂的,。但是开挂要下载第三方辅助软件,全盛棋牌的开挂软件,名...
我来教大家“情怀三三麻将辅助器...
我来教大家“情怀三三麻将辅助器app官方下载最新版本更新”详细分享开挂一、情怀三三麻将AI软件牌型概...
我来教大家“无锡好运麻将辅助器...
亲,无锡好运麻将这款游戏可以开挂的,确实是有挂的,。但是开挂要下载第三方辅助软件,无锡好运麻将的开挂...
我来教大家“推筒子辅助器app...
您好,推筒子这款游戏可以开挂的,确实是有挂的,需要了解加微{7198902}很多玩家在这款游戏中打牌...
我来教大家“比奇堡辅助器app...
我来教大家“比奇堡辅助器app官方下载最新版本更新”详细分享开挂1、让任何用户在无需AI插件第三方神...
我来教大家“新兴茶苑辅助器ap...
我来教大家“新兴茶苑辅助器app官方下载最新版本更新”详细分享开挂1、让任何用户在无需AI插件第三方...
我来教大家“欢乐互动辅助器ap...
我来教大家“欢乐互动辅助器app官方下载最新版本更新”详细分享开挂1、让任何用户在无需AI插件第三方...
我来教大家“东方互娱辅助器ap...
亲,东方互娱这款游戏可以开挂的,确实是有挂的,。但是开挂要下载第三方辅助软件,东方互娱的开挂软件,名...
我来教大家“天天乐清麻将辅助器...
我来教大家“天天乐清麻将辅助器app官方下载最新版本更新”详细分享开挂一、天天乐清麻将AI软件牌型概...
我来教大家“唐三彩辅助器app...
我来教大家“唐三彩辅助器app官方下载最新版本更新”详细分享开挂一、唐三彩AI软件牌型概率发牌机制”...
我来教大家“Y0辅助器app官...
我来教大家“Y0辅助器app官方下载最新版本更新”详细分享开挂一、Y0AI软件牌型概率发牌机制”必胜...
我来教大家“天天互娱辅助器ap...
亲,天天互娱这款游戏可以开挂的,确实是有挂的,。但是开挂要下载第三方辅助软件,天天互娱的开挂软件,名...
我来教大家“悟空竞技麻将辅助器...
亲,悟空竞技麻将这款游戏可以开挂的,确实是有挂的,。但是开挂要下载第三方辅助软件,悟空竞技麻将的开挂...
我来教大家“情怀开化麻将辅助器...
我来教大家“情怀开化麻将辅助器app官方下载最新版本更新”详细分享开挂一、情怀开化麻将AI软件牌型概...
我来教大家“龙炎互娱辅助器ap...
我来教大家“龙炎互娱辅助器app官方下载最新版本更新”详细分享开挂一、龙炎互娱AI软件牌型概率发牌机...
我来教大家“闲逸碰胡辅助器ap...
亲,闲逸碰胡这款游戏可以开挂的,确实是有挂的,。但是开挂要下载第三方辅助软件,闲逸碰胡的开挂软件,名...
我来教大家“友聚麻将辅助器ap...
我来教大家“友聚麻将辅助器app官方下载最新版本更新”详细分享开挂一、友聚麻将AI软件牌型概率发牌机...