
特征工程资料整理,如何从数据中挖掘特征
特征工程资料整理,如何从数据中挖掘特征
- 一、特征工程是什么
- 二、探索性数据分析EDA
- 参考资料:
- 1. pandas_profiling【推荐】
- 2. Sweetviz
- 3. pandasgui
- 4.D-tale【推荐】
- 结论
- 三、特征处理
- 参考资料:
- 1. 数值特征
- ⭐️⭐️⭐️⭐️⭐️数值特征小结:
- 什么时候用归一化?什么时候用标准化?
- 2. 类别特征
- ⭐️⭐️⭐️⭐️⭐️类别特征小结:
- 3. 时间特征
- ⭐️⭐️⭐️⭐️⭐️时间特征小结:
- 4. 空间特征
- 5. 文本特征
- 6. 图像特征
- 7. 音频特征
- 8. 其他常见方法
一、特征工程是什么
数据和特征决定了机器学习算法的上限,而模型和算法只是不断逼近这个上限而已。
什么是特征工程?比如金融信贷申请反欺诈场景下,当一个新的用户来申请贷款,我们如何评估一个用户是欺诈用户还是正常用户,那么就需要找到这二者在哪些特征上表现存在差异,通过这些特征来进行区分。寻找基本特征、构建组合特征来有效地区分不同label的样本,这个就是特征工程。
特征工程往往是打开数据密码的钥匙,是数据科学中最有创造力的一部分。
建模就是从数据中学习到insights(洞见)过程,这个过程其实是很曲折的,他要经过数据的表达,模型的学习两步。
数据的表达就是原始数据经过clean and transformer得到features的过程,即为特征工程。
特征工程类似于炼丹术士的精炼过程。
他的作用就是把人的知识融入到数据表达中,减轻模型的负担,让模型更容易学习到本质的知识。
二、探索性数据分析EDA
EDA是数据分析必须的过程,用来查看变量统计特征,可以此为基础尝试做特征工程。
参考资料:
- https://mp.weixin.qq.com/s/CIZjJg1sEsbkToYjSlRaUQ
- https://zhuanlan.zhihu.com/p/347993858
- https://zhuanlan.zhihu.com/p/85967505
1. pandas_profiling【推荐】
这个属于三个中最轻便、简单的了。它可以快速生成报告,一览变量概况。
总共提供了六个部分内容:概述、变量、交互、相关性、缺失值、样本。
2. Sweetviz
Sweetviz是另一个Python的开源代码包,仅用一行代码即可生成漂亮的EDA报告。与Pandas Profiling的区别在于它输出的是一个完全独立的HTML应用程序。
Sweetviz优势:
- 分析有关目标值的数据集的能力
- 两个数据集之间的比较能力
Sweetviz缺点:
- 变量之间没有可视化,例如散点图
- 报告在另一个标签中打开
3. pandasgui
mac使用有报错
PandasGUI与前面的两个不同,PandasGUI不会生成报告,而是生成一个GUI(图形用户界面)的数据框,我们可以使用它来更详细地分析我们的Dataframe。
pandasGUI优势:
- 可以拖拽
- 快速过滤数据
- 快速绘图
pandasGUI缺点:
- 没有完整的统计信息
- 不能生成报告
4.D-tale【推荐】
面向Pandas 中的DataFrame,D-Tale库可以进行可视化。和其他可视化不太一样的,D-Tale生成交互式图形界面,支持在其中定义所需的数据外观,并根据需要对数据进行探索性分析。
d-tale优势:
- 功能强大,描述性分析,重复/缺失/相关/时序/异常值分析等
- 自定义可视化,集成折线/散点/柱状/词云等多种图表
- 一键导出代码,支持将操作转换为代码,可直接复制用于项目中
- 支持中文汉化
d-tale缺点:
- 没有完整的统计信息
- 不能生成报告
结论
Pandas Profiling、Sweetviz和PandasGUI都很不错,旨在简化我们的EDA处理。在不同的工作流程中,每个都有自己的优势和适用性,4个工具具体优势如下:
- Pandas Profiling 适用于快速生成单个变量的分析报告。
- Sweetviz 适用于数据集之间和目标变量之间的分析。
- PandasGUI适用于具有手动拖放功能的深度分析。
- D-tale适用于数据深入探索和快速分析的场景。
三、特征处理
具体采取哪一种处理方式不仅依赖于业务和数据本身,还依赖于所选取的模型。
参考资料:
- https://cloud.tencent.com/developer/article/1388206
- https://mp.weixin.qq.com/s/vKQcHT6LM1M2PfTKfHbGxQ
- https://mp.weixin.qq.com/s/W6o_U0pyd5K4mTqGVLl9sQ
- https://mp.weixin.qq.com/s/kt_rK-pM4FWGfR5E-OeJDg
- https://mp.weixin.qq.com/s/emw05TSwjd-szqgirbpk9A
- https://mp.weixin.qq.com/s/CWUFLMK0ZhDuqWXiveoBpg
- https://mp.weixin.qq.com/s/fdEK5ootbX9kZFdXmvkohA
- https://mp.weixin.qq.com/s/8LIj1_RG7ub8Cpg-OlYzfA
- https://mp.weixin.qq.com/s/hsB_KMn5zTKMq1Gpj0KOzQ
1. 数值特征
⭐️⭐️⭐️⭐️⭐️数值特征小结:
- 数据规范化
- 归一化
- 标准化
- Robust Scaler特征缩放
- 截断(降低精度以减少噪音)
- 缩放
- 标准化缩放(Z缩放)
- 最大最小值缩放/最大绝对值缩放
- 基于范数的归一化(L1/L2范数)
- 平方根缩放/对数缩放(处理长尾分布且取值为正数的数值非常有效,统计学中称为方差稳定的变换)
- 有异常点的健壮缩放(中位数代替均值,分位数代替方差)
- 二值化
- 分箱
- 有监督分箱
- 卡方分箱
- 最小熵法分箱
- 无监督分箱
- 等距分箱
- 等频分箱
- 聚类模型分箱
- 有监督分箱
- 聚合特征构造
- 中位数、平均值、最大最小、标准差、方差、频数等
- 特征交叉
- 转换特征构造
- 单调转换(幂变换、log对数变换、绝对值、倒数转换、平方根转换、Box Cox等)、线性组合、多项式组合、比例、排名编码、异或值
- 非线性编码(多项式核、高斯核等编码)
- 基于业务理解
- 单价、销售量、利润、增长额等
什么时候用归一化?什么时候用标准化?
来源:如何进行时间序列的特征工程
- 如果对输出结果范围有要求,用归一化。
- 如果数据较为稳定,不存在极端的最大最小值,用归一化。
- 如果数据存在异常值和较多噪音,用标准化,可以间接通过中心化避免异常值和极端值的影响。
2. 类别特征
⭐️⭐️⭐️⭐️⭐️类别特征小结:
- 标签编码(Label Encoder)
- 分层编码
- 散列编码(先散列后独热,避免特征矩阵过于稀疏)
- 哈希编码(Hash Encoder)
- 独热编码(One-hot Encoder)
- 计数编码(Count Encoder)
- 计数排名编码
- 直方图编码(Bin Encoder)
- WOE证据权重编码
- 目标编码(Target Encoder)
- 平均编码(Mean Encoder)
- 模型编码(Model Encoder)
- Ordinal Encoder顺序编码(类似Label Encoder)
- CatBoostEncoder
- 神经网络embedding
- lgb类别特征处理
- 特征交叉组合
- 类别特征之间交叉组合
- 类别特征和数值特征之间交叉组合
我这里总结了以上类别编码方法的区别:
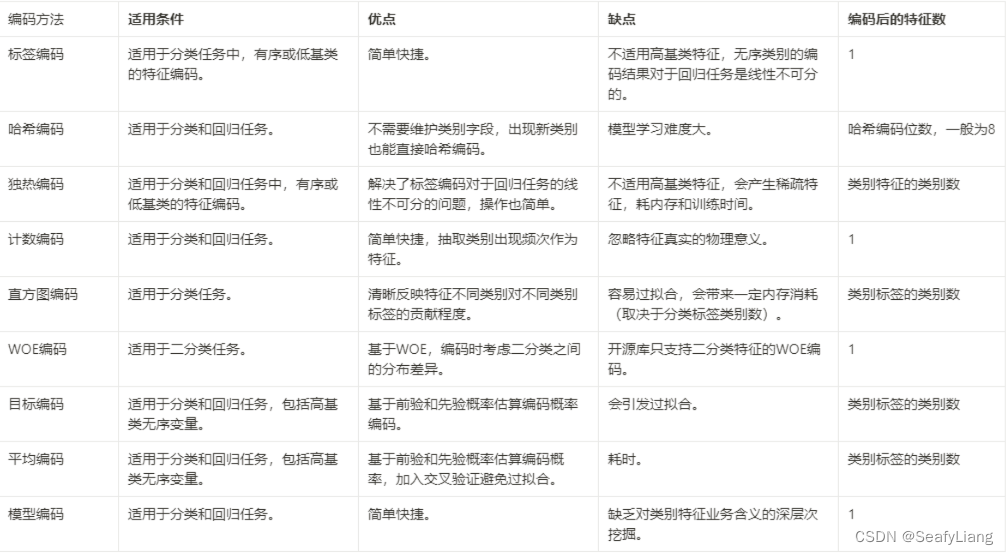
总结来说,关于类别特征,有以下心得:
(1) 统计类编码常常不适用于小样本,因为统计意义不明显。
(2) 当训练集和测试集分布不一致时,统计类编码往往会有预测偏移问题,所以一般会考虑结合交叉验证。
(3) 编码后特征数变多的编码方法,不适用于高基类的特征,会带来稀疏性和训练成本。
(4) 没有完美的编码方法,但感觉标签编码、平均编码、WOE编码和模型编码比较常用。
3. 时间特征
⭐️⭐️⭐️⭐️⭐️时间特征小结:
- 1、时间特征
- 连续值时间特征
- 持续时间(单页浏览时长)
- 间隔时间(上次购买距离现在的时长)
- 离散型时间特征
- 时间拆解
- 年;月;日;时;分;秒;一天中的第几分钟;星期几;一年中的第几天;一年中的第几个周;一年中的哪个季度;一天中哪个时间段:凌晨、早晨、上午、中午、下午、傍晚、晚上、深夜;
- 时间判断
- 是否闰年;是否月初;是否月末;是否季节初;是否季节末;是否年初;是否年尾;是否周末;是否节假日;是否工作日;两个时间间隔之间是否包含节假日/特殊日期;
- 时间拆解
- 连续值时间特征
- 2、时间序列特征
- 统计聚合
- 简单特征:极值、分位数、缺失数、重复值
- 集中趋势:平均值、最小/最大值
- 离散趋势:极差、扩散值(标准差,平均绝对偏差,四分位差等)、离散系数
- 分布:偏态系数、峰值个数、相邻峰差值、峰位置
- 时序复合特征
- 趋势特征:上升/下降趋势、某段时间对某段时间的变化情况
- 周期性:周周期性、月周期性、年周期性
- 窗口特征:同比、环比、滞后值(T-1作为T的变量)
- 滑动窗口(根据指定的单位长度来框住时间序列,每次滑动一个单位)
- 滚动窗口(根据指定的单位长度来框住时间序列,每次滑动窗口长度的多个单位)
- 自相关性特征:自相关系数,与自身左移N个时间空格的时间序列相关系数
- 其他:历史波动率、瞬间波动率、隐含波动率、偏度、峰度、瞬时相关性等
- 结合时间维度的聚合特征
- 特定日期聚合
- 特定日:注册首日页面访问时长
- 特定日期区间:国庆期间APP用户活跃数,每天下午平均客流量
- 最近时间聚合
- 近N天APP登录天数
- 特定日期聚合
- 统计聚合
4. 空间特征
位置特征:
经纬度、POI、AOI、附近建筑物、路径、出发点、终点、常去点、收藏点
经纬度做散列得到空间区域分块,坐标拾取街道ID、城市ID等,位置与位置之间的距离(欧氏距离、球面距离、曼哈顿距离、真实街道距离)
5. 文本特征
- 词袋模型
- 词嵌入模型
- 语料构建
- 文本清洗
- 分词
- 词性标注
- 词形还原和词干提取
- 文本统计特征
- N-Gram模型
- Skip-Gram模型
- 词集模型
- 词袋模型
- TF-IDF
- 余弦相似度
- Jaccard相似度
- Levenshtein(编辑距离)
- 隐性语义分析
- Word2Vec
6. 图像特征
- SIFT
- Gabor
- HOG
7. 音频特征
- 梅尔滤波
- Bark滤波
- FBank
- MFCC
8. 其他常见方法
降维方面:
- PCA
- ICA
- LDA