
智能优化算法:人工兔优化算法-附代码
智能优化算法:人工兔优化算法
摘要:人工兔优化算法( [Artificial rabbits optimization,RSO)是 Liying Wang等 于 2022 年提出的一种新型元启发式优化算法 。 该算法受来源于自然界中兔子的生存策略的启发,具有寻优能力强,收敛速度快的特点。
1.人工兔优化算法
人工兔优化算法利用真实兔子的觅食和隐藏策略,并通过能量收缩在两种策略之间进行转换。
1.1 绕道觅食(探索)
兔子觅食时,总是寻找远的,而忽略了近处的。它们只在其他区域随机吃草,而不是在自己的区域,把这种觅食行为称为绕道 时,兔子很可能会扰乱食物来源以获得足够的食物。因此,ARO的绕道㐍食行为表明,每个搜索个体倾向于向种群中随机选择的另一个 搜索个体更新自己的位置,并增加扰动。
v⃗i(t+1)=x⃗j(t)+R⋅(x⃗i(t)−x⃗j(t))+round(0.5⋅(0.05+r1))⋅n1i,j=1,⋯,nand j≠i(1)\begin{gathered} \vec{v}_i(t+1)=\vec{x}_j(t)+R \cdot\left(\vec{x}_i(t)-\vec{x}_j(t)\right)+\operatorname{round}\left(0.5 \cdot\left(0.05+r_1\right)\right) \cdot n_1 \\ i, j=1, \cdots, n \text { and } j \neq i \end{gathered} \tag{1} vi(t+1)=xj(t)+R⋅(xi(t)−xj(t))+round(0.5⋅(0.05+r1))⋅n1i,j=1,⋯,n and j=i(1)
R=L⋅c(2)R=L \cdot c \tag{2} R=L⋅c(2)
L=(e−e(t−1T)2)⋅sin(2πr2)(3)L=\left(e-e^{\left(\frac{t-1}{T}\right)^2}\right) \cdot \sin \left(2 \pi r_2\right) \tag{3} L=(e−e(Tt−1)2)⋅sin(2πr2)(3)
c(k)={1,if k==g(l)0,else k=1,⋯,dand l=1,⋯,⌈r3⋅d⌉(4)c(k)=\left\{\begin{array}{ll} 1, & \text { if } k==g(l) \\ 0, & \text { else } \end{array} k=1, \cdots, d \text { and } l=1, \cdots,\left\lceil r_3 \cdot d\right\rceil\right. \tag{4} c(k)={1,0, if k==g(l) else k=1,⋯,d and l=1,⋯,⌈r3⋅d⌉(4)
g=randperm(d)(5)g=\operatorname{randperm}(d) \tag{5} g=randperm(d)(5)
n1∼N(0,1)(6)n_1 \sim N(0,1) \tag{6} n1∼N(0,1)(6)
其中, v⃗i(t+1)\vec{v}_i(t+1)vi(t+1) 是第 t+1t+1t+1 次迭代时第 iii 只兔子的候选位置; x⃗i(t)\vec{x}_i(t)xi(t) 是第 ttt 次迭代时第 iii 只兔子的当前位置; nnn 是兔群的数量; ddd 是问题的维 度; TTT 是最大迭代次数; ⌈⋅⌉\lceil\cdot\rceil⌈⋅⌉ 是向上取整函数; round表示四舍五入; randperm(d)\operatorname{randperm}(d)randperm(d) 表示返回从1到 ddd 的整数的随机排列; r1,r2,r3r_1, r_2, r_3r1,r2,r3 均为 (0,1)(0,1)(0,1) 区间的随机数; LLL 为奔跑动长度,代表绕行豆食时的运动速度; n1n_1n1 为服从标准正态分布的随机数。
在式(1)中,扰动可以帮助ARO避免局部极值,进行全局搜索。由式(3)可知,奔跑长度 LLL 在初始迭代时可以产生更长的步长,而这个长度 可以在以后的迭代中生成更短的步骤。图1给出了 LLL 的动态变化,可以看出较长的步长有利于探索,较短的步长有利于开发。 CCC 是一个映 射向量,它可以帮助算法在㐍食行为中随机选择随机数量的搜索个体元素进行变异。 RRR 表示奔跑算子,用于模拟兔子的运行特性。
式(1)表示搜索个体根据彼此的位置进行随机的食物捭索。这种行为使一只兔子远离自己的区域,跑到其他兔子的区域。兔子这种不去自 己窝而去别人窝的特殊觅食行为极大地促进了探索,保证了ARO算法的全局搜索能力。
1.2 随机躲藏(开发)
为了躲避捕食者,兔子通常会在它的稞穴周围挖一些不同的洞穴来藏身。在ARO算法中,每一次迭代,一只兔子总是沿看搜索空间的每 一个维度在它周围产生 ddd 个洞,并且总是从所有的洞中随机选择一个隐臧起来,以降低被捕食的概率。第 iii 只兔子的第 jjj 个洞穴由以下公式 产生:
b⃗i,j(t)=x⃗i(t)+H⋅g⋅x⃗i(t),i=1,⋯,nand j=1,⋯,d(7)\vec{b}_{i, j}(t)=\vec{x}_i(t)+H \cdot g \cdot \vec{x}_i(t), \quad i=1, \cdots, n \text { and } j=1, \cdots, d \tag{7} bi,j(t)=xi(t)+H⋅g⋅xi(t),i=1,⋯,n and j=1,⋯,d(7)
H=T−t+1T⋅r4(8)H=\frac{T-t+1}{T} \cdot r_4 \tag{8} H=TT−t+1⋅r4(8)
n2∼N(0,1)(9)n_2 \sim N(0,1) \tag{9} n2∼N(0,1)(9)
g(k)={1,if k==j0,else k=1,⋯,d(10)g(k)=\left\{\begin{array}{ll} 1, & \text { if } k==j \\ 0, & \text { else } \end{array} \quad k=1, \cdots, d\right. \tag{10} g(k)={1,0, if k==j else k=1,⋯,d(10)
根据式(7),沿每个维度在兔子位置附近生成 ddd 个洞六。其中, HHH 是隐藏参数,在迭代过程中,随着随机扰动,隐藏参数从1线性減小到 1/T1 / T1/T 。根据这个参数,最初这些洞穴是在兔子的一个更大的邻域中产生的。随看迭代次数的增加,这个邻域也会減少。
如上所述,兔子经常受到捕食者的追逐和攻击。为了生存,兔子需要找一个安全的地方躲起来。因此,它们被拒绝从洞穴中随机选择一个 洞穴㧶避,以免被抓住。为了对这种随机隐藏策略进行数学建模,提出了以下公式:
v⃗i(t+1)=x⃗i(t)+R⋅(r4⋅b⃗i,r(t)−x⃗i(t)),i=1,⋯,n(11)\vec{v}_i(t+1)=\vec{x}_i(t)+R \cdot\left(r_4 \cdot \vec{b}_{i, r}(t)-\vec{x}_i(t)\right), i=1, \cdots, n \tag{11} vi(t+1)=xi(t)+R⋅(r4⋅bi,r(t)−xi(t)),i=1,⋯,n(11)
gr(k)={1,if k==⌈r5⋅d⌉0,else k=1,⋯,d(12)g_r(k)=\left\{\begin{array}{ll} 1, & \text { if } k==\left\lceil r_5 \cdot d\right\rceil \\ 0, & \text { else } \end{array} k=1, \cdots, d\right. \tag{12} gr(k)={1,0, if k==⌈r5⋅d⌉ else k=1,⋯,d(12)
b⃗i,r(t)=x⃗i(t)+H⋅fr⋅x⃗i(t)(13)\vec{b}_{i, r}(t)=\vec{x}_i(t)+H \cdot f_r \cdot \vec{x}_i(t) \tag{13} bi,r(t)=xi(t)+H⋅fr⋅xi(t)(13)
其中, b⃗i,r(t)\vec{b}_{i, r}(t)bi,r(t) 表示用于隐藏其 ddd 个洞穴而随机选择的洞穴; r4r_4r4 和 r5r_5r5 为两个 (0,1)(0,1)(0,1) 范围内的随机数。根据式(11),第 iii 只搜索个体将尝试从其ddd 个洞穴中向随机选择的洞穴更新其位置。
在实现绕道颃食和随机躯藏策略中的其中一个之后,兔子的位置更新为:
x⃗i(t+1)={x⃗i(t),f(x⃗i(t))≤f(v⃗i(t+1))v⃗i(t+1),f(x⃗i(t))>f(v⃗i(t+1))(14)\vec{x}_i(t+1)= \begin{cases}\vec{x}_i(t), & f\left(\vec{x}_i(t)\right) \leq f\left(\vec{v}_i(t+1)\right) \\ \vec{v}_i(t+1), & f\left(\vec{x}_i(t)\right)>f\left(\vec{v}_i(t+1)\right)\end{cases} \tag{14} xi(t+1)={xi(t),vi(t+1),f(xi(t))≤f(vi(t+1))f(xi(t))>f(vi(t+1))(14)
该式表示,若兔子的候选位置的适应度比当前位置的适应度好,则兔子将放弃当前位置并更新为由式(1)或式(11)生成的候选位置。
1.3 能量收缩(从探索转向开发)
在ARO算法中,兔子在迭代的初始阶段经常进行绕道觅食,而在迭代的后期则经常进行随机隐藏。这种搜索机制是由兔子的能量产生 的,随着时间的推移,兔子的能量会逐渐减少。因此,设计了一个能量因子来模拟从探索到开发的转换过程。ARO中的能量因子定义如 下:
A(t)=4(1−tT)ln1r(15)A(t)=4\left(1-\frac{t}{T}\right) \ln \frac{1}{r} \tag{15} A(t)=4(1−Tt)lnr1(15)
其中 rrr 为 (0,1)(0,1)(0,1) 中的随机数。因此,在ARO中,当能量因子 A(t)>1A(t)>1A(t)>1 时,一只 兔子在探索阶段容易随机探索不同兔子的区域采食,因此发生绕行采食;当能量因子 A(t)≤1A(t) \leq 1A(t)≤1 时,兔子在挖掘阶段倾向于随机挖掘自己 的洞六,从而发生随机隐藏。根据能量因子 AAA 的大小,ARO可以在绕道总食和随机躯藏之间切换。也就是说,当 A(t)>1A(t)>1A(t)>1 时进行探索, 当 A(t)≤1A(t) \leq 1A(t)≤1 时进行开发。

2.实验结果
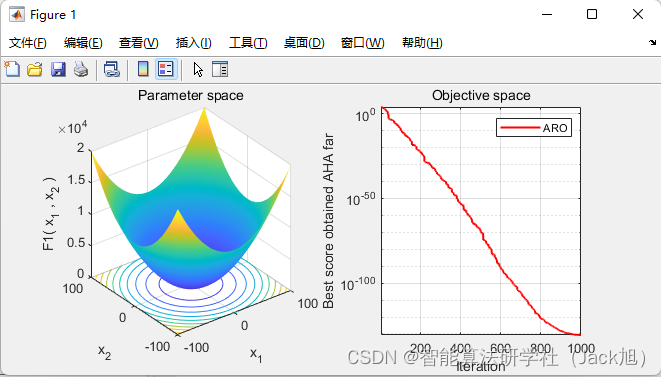
3.参考文献
[1] Liying Wang, Qingjiao Cao, Zhenxing Zhang, et al. Artificial rabbits optimization: A new bio-inspired meta-heuristic algorithm for solving engineering optimization problems[J]. Engineering Applications of Artificial Intelligence, 2022, 114: 105082.