手把手教你用springboot实现jdk文档搜索引擎
目录
项目背景
项目描述
项目整体架构
项目流程
构建索引
项目背景
搜索引擎是我们经常会用到的工具,例如我们熟知的百度,谷歌等搜索引擎。除了网络搜索引擎,还有很多地方也有搜索引擎的身影,例如视频网站的搜索框,手机的应用搜索功能。搜索引擎是一个很有用的工具,在数据量很大的时候,使用搜索引擎搜索能极大的提高效率,因此我想到了 JAVA 开发者们经常会用到的 JDK 文档。文档的内容很多,数量高达上万篇,因此当我们想查找一个东西的时候想找到对应的文档很难,因此我们可以写一个搜索引擎来快速的查找到我们想要的文档。
项目描述
打开浏览器,在搜索框中输入我们想要查找的关键词,点击搜索就能查找到 JDK 文档中所有与关键词有关的文档。但是我们无法搜索到 JDK 文档以外的信息,因为我们只针对 JDK 文档建立的搜索功能。
项目整体架构

项目流程
构建索引
1.首先创建一个 springboot 项目
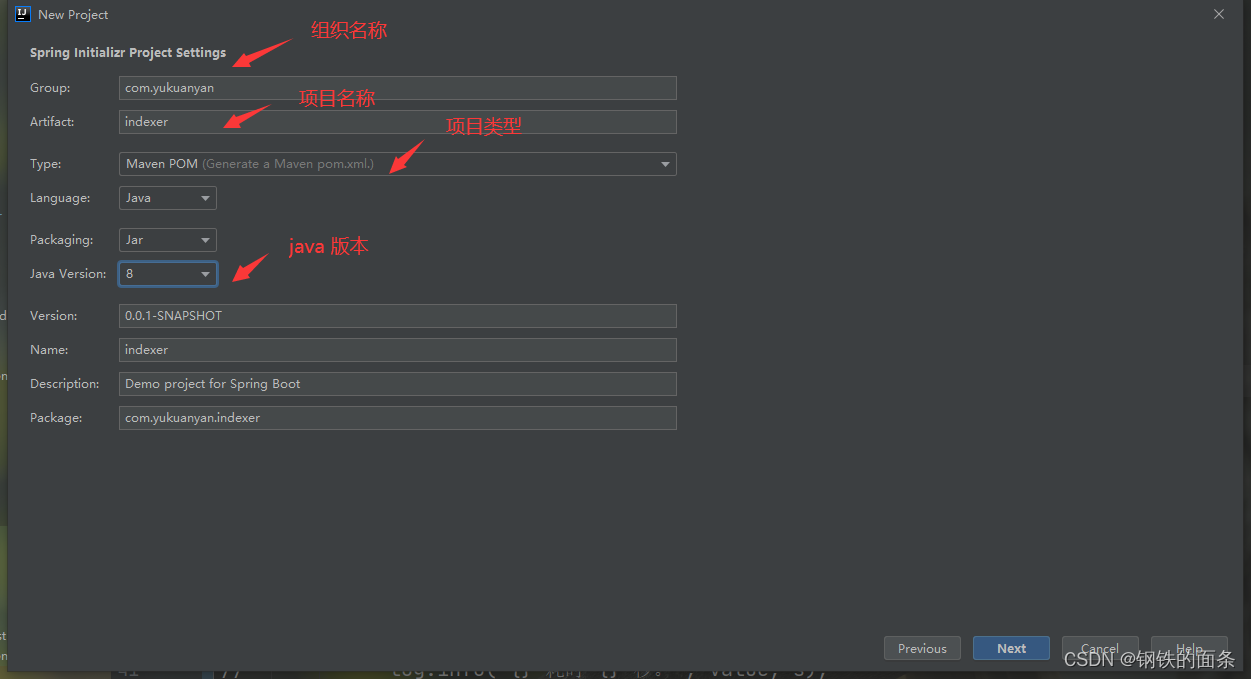
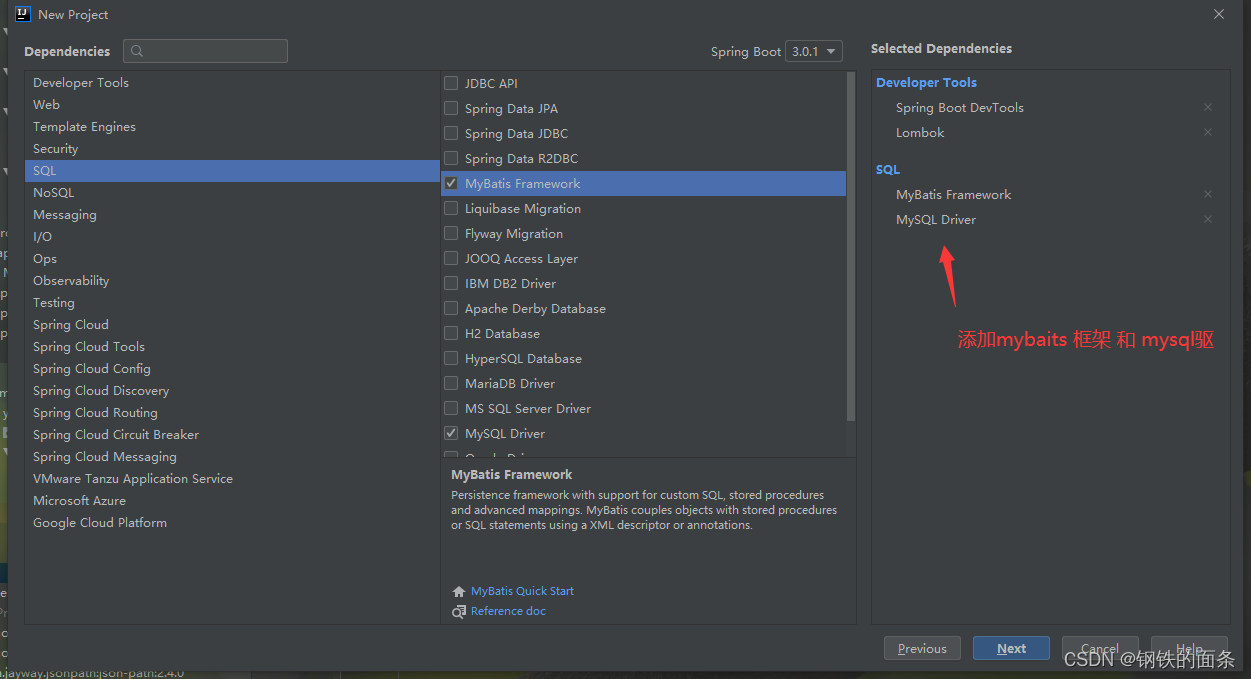
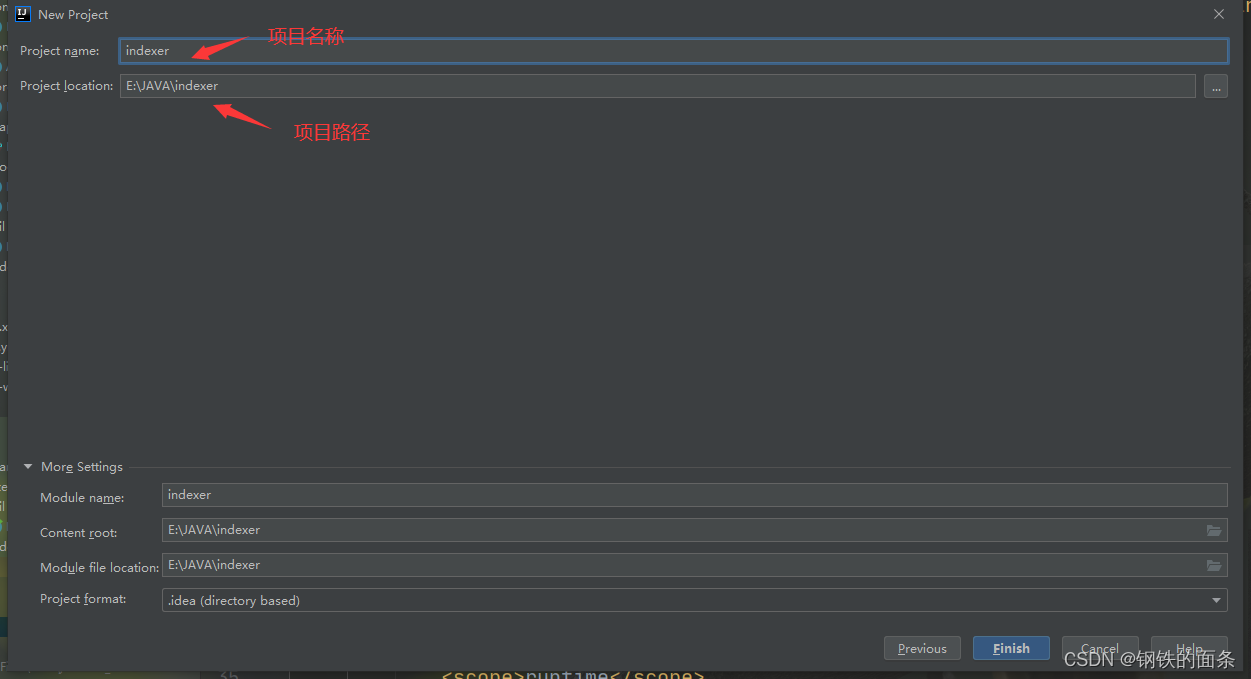
2.配置数据库
找到 resource 下的 application.application (也可以改成 application.yml) 配置文件配置数据库
3.扫描所有的jdk文档
在 indexer 下新建 util 包用来存放工具类,再在 util 包下新建 FileScanner 类,实现扫描 JDK 文档的功能。我们需要在配置文件中定义文档的根目录,FileScanner 就能扫描出根目录中的所有 html 文档。
package com.yukuanyan.indexer.util;import lombok.extern.slf4j.Slf4j;
import org.springframework.stereotype.Service;import java.io.File;
import java.util.ArrayList;
import java.util.List;@Service
@Slf4j
public class FileScanner {public List scanFile(String rootPath){List finalFileList = new ArrayList<>();File rootFile = new File(rootPath);//说明对应路径的的文件不存在if (rootFile == null) {return finalFileList;}//进行遍历traversal(rootFile,finalFileList);return finalFileList;}private void traversal(File rootFile,List fileList) {// 获取所有的文件和文件夹,得到一个 FileListFile[] files = rootFile.listFiles();// 一般是权限问题,一般不会碰到if (files == null) {return ;}// 遍历 FileList,如果是 html 文件就保存到list中,如果是文件夹就继续递归遍历for (File file : files) {if (file.isFile() && file.getName().endsWith(".html")) {fileList.add(file);} else {traversal(file,fileList);}}}
}
4.生成正排索引和倒排索引
正排索引的结构:key-value key是文档id,value是标题,url和内容。
倒排索引的结构:key-value key 是一个单词,value是一个list,list里面是一个 倒排记录对象,对象中有 单词,文档id和权重,表示在id为……的文档中,某某单词的权重是多少。
因此,我只要们拿到所有的 files 就能获得正排索引,docId就是数据库自增id。
而倒排索引是一个自定义对象(及在id为……的文档中,某某单词的权重是多少)的集合,在这里一条倒排索引称之为InvertedRecord(倒排记录)
创建Document类:在indexer 包下新建 model 包,在model 包下新建 Document 类。当前类是我们对 html 文档的抽象,用于将磁盘中的文件加载到内存中并且提取出构建索引需要的内容。
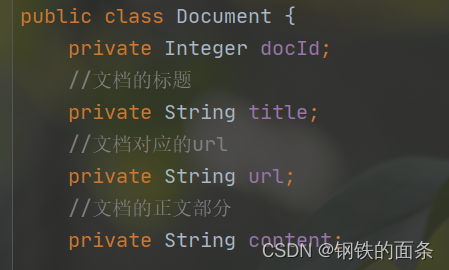
因为每个文档对象都需要被分词和计算权重,所以每一个 Document 对象都需要有分词和计算权重的方法(segWordsAndCalcWeight)。我们先分别分词和统计标题单词的出现次数和正文单词的出现次数。
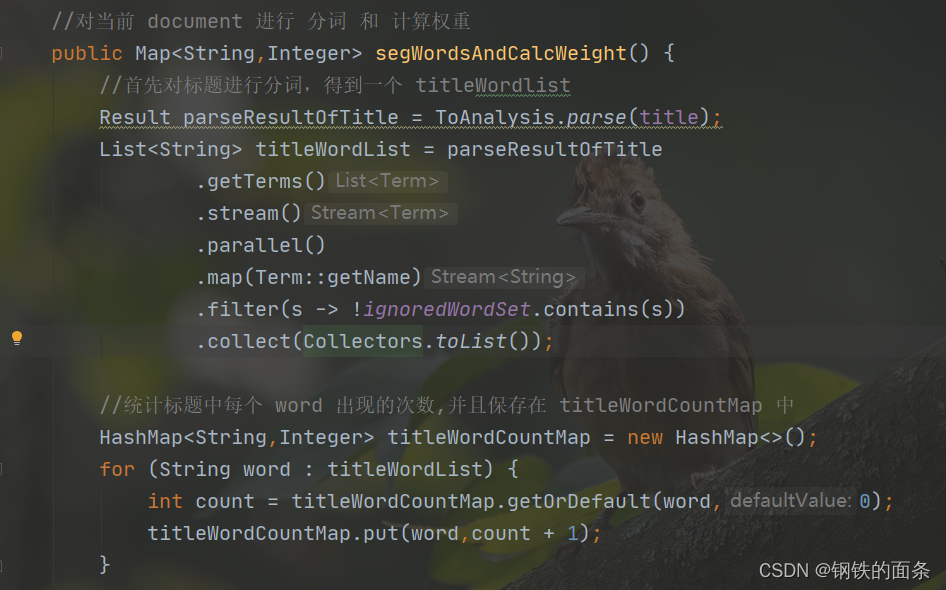
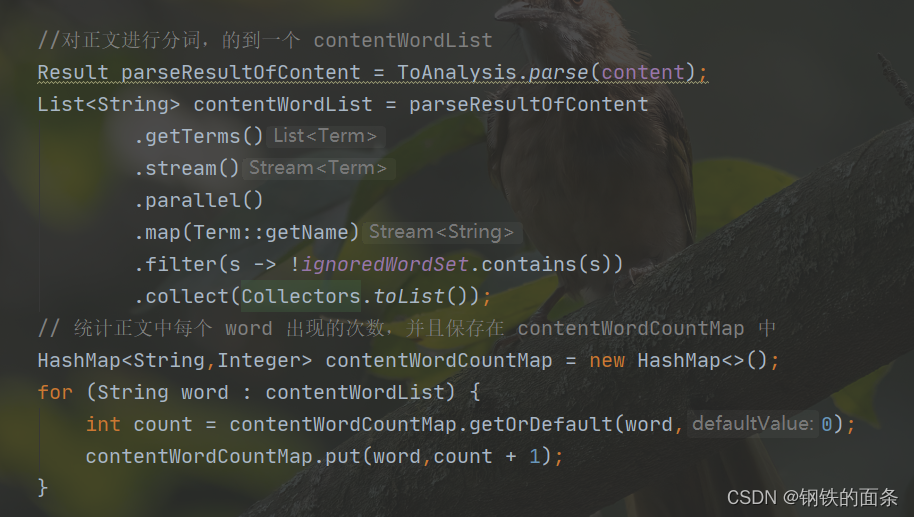
再根据权重计算公式计算出当前 document 每个单词对应的权重(权重 = 标题权重 + 正文权重),至此当前 document 的所有单词的权重已经生成好了,将他们保存在 map 中。
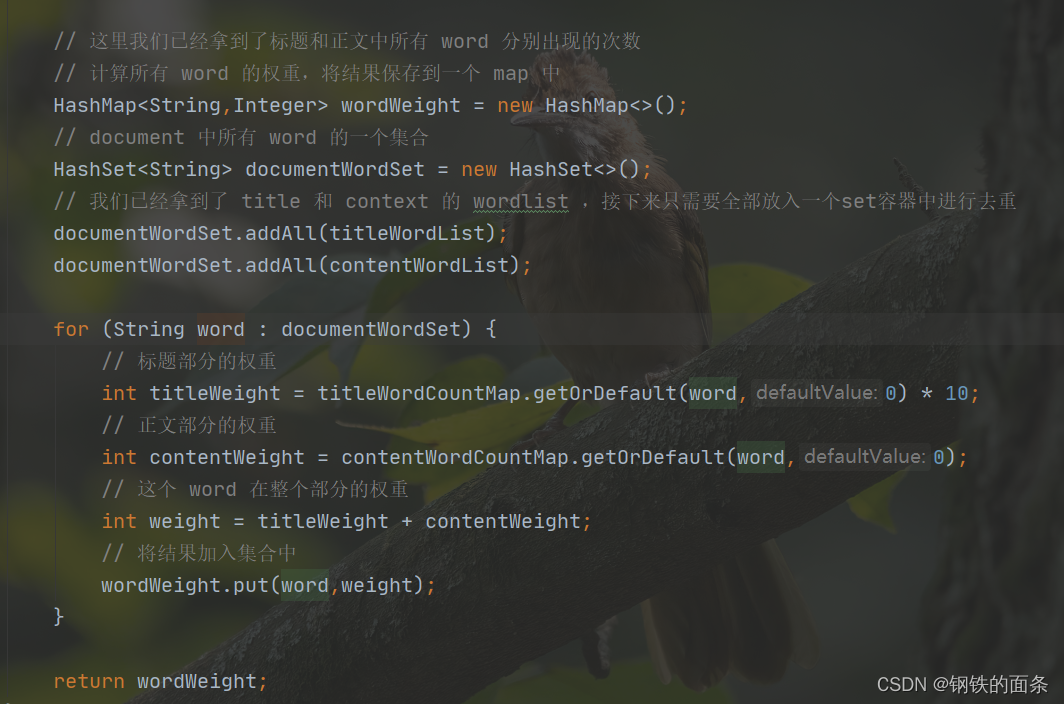
完整代码:
Document类:
package com.yukuanyan.indexer.model;import lombok.Data;
import lombok.SneakyThrows;
import lombok.extern.slf4j.Slf4j;
import org.ansj.domain.Result;
import org.ansj.domain.Term;
import org.ansj.splitWord.analysis.ToAnalysis;import java.io.*;
import java.util.*;
import java.util.stream.Collectors;@Slf4j
@Data
public class Document {private Integer docId;//文档的标题private String title;//文档对应的urlprivate String url;//文档的正文部分private String content;//由于分词结果中会出现这些没有意义的字符,忽略分词结果中的这些字符private final static HashSet ignoredWordSet = new HashSet<>();static {ignoredWordSet.add(" ");ignoredWordSet.add("\t");ignoredWordSet.add("。");ignoredWordSet.add(".");ignoredWordSet.add(",");ignoredWordSet.add("(");ignoredWordSet.add(")");ignoredWordSet.add("/");ignoredWordSet.add("-");ignoredWordSet.add(";");}public Document(File file,String urlPrefix,File rootFile){this.title = parseTitle(file);this.url = parseUrl(file,urlPrefix,rootFile);this.content = parseContent(file);}// 解析正文@SneakyThrowsprivate String parseContent(File file) {StringBuilder contentBuilder = new StringBuilder();try (InputStream is = new FileInputStream(file)) {try (Scanner scanner = new Scanner(is, "ISO-8859-1")) {while (scanner.hasNextLine()) {String line = scanner.nextLine();contentBuilder.append(line).append(" ");}// 利用正则表达式去除正文中的 html 标签return contentBuilder.toString().replaceAll(".*?", " ").replaceAll("<.*?>", " ").replaceAll("\\s+", " ").trim();}}}@SneakyThrowsprivate String parseUrl(File file, String urlPrefix, File rootFile) {// 需要得到一个相对路径,file 相对于 rootFile 的相对路径// 比如:rootFile 是 C:\Users\秋叶雨\Downloads\docs\api\// file 是 C:\Users\秋叶雨\Downloads\docs\api\java\ util\TreeSet.html// 则相对路径就是:java\ util\TreeSet.html// 把所有反斜杠(\) 变成正斜杠(/)// 最终得到 java/sql/DataSource.htmlString rootPath = rootFile.getCanonicalPath();rootPath = rootPath.replace("/", "\\");if (!rootPath.endsWith("\\")) {rootPath = rootPath + "\\";}String filePath = file.getCanonicalPath();String relativePath = filePath.substring(rootPath.length());relativePath = relativePath.replace("\\", "/");return urlPrefix + relativePath;}private String parseTitle(File file) {// 从文件名中,将 .html 后缀去掉,剩余的看作标题String name = file.getName();String suffix = ".html";return name.substring(0, name.length() - suffix.length());}//对当前 document 进行 分词 和 计算权重public Map segWordsAndCalcWeight() {//首先对标题进行分词,得到一个 titleWordlistResult parseResultOfTitle = ToAnalysis.parse(title);List titleWordList = parseResultOfTitle.getTerms().stream().parallel().map(Term::getName).filter(s -> !ignoredWordSet.contains(s)).collect(Collectors.toList());//统计标题中每个 word 出现的次数,并且保存在 titleWordCountMap 中HashMap titleWordCountMap = new HashMap<>();for (String word : titleWordList) {int count = titleWordCountMap.getOrDefault(word,0);titleWordCountMap.put(word,count + 1);}//对正文进行分词,的到一个 contentWordListResult parseResultOfContent = ToAnalysis.parse(content);List contentWordList = parseResultOfContent.getTerms().stream().parallel().map(Term::getName).filter(s -> !ignoredWordSet.contains(s)).collect(Collectors.toList());// 统计正文中每个 word 出现的次数,并且保存在 contentWordCountMap 中HashMap contentWordCountMap = new HashMap<>();for (String word : contentWordList) {int count = contentWordCountMap.getOrDefault(word,0);contentWordCountMap.put(word,count + 1);}// 这里我们已经拿到了标题和正文中所有 word 分别出现的次数// 计算所有 word 的权重,将结果保存到一个 map 中HashMap wordWeight = new HashMap<>();// document 中所有 word 的一个集合HashSet documentWordSet = new HashSet<>();// 我们已经拿到了 title 和 context 的 wordlist ,接下来只需要全部放入一个set容器中进行去重documentWordSet.addAll(titleWordList);documentWordSet.addAll(contentWordList);for (String word : documentWordSet) {// 标题部分的权重int titleWeight = titleWordCountMap.getOrDefault(word,0) * 10;// 正文部分的权重int contentWeight = contentWordCountMap.getOrDefault(word,0);// 这个 word 在整个部分的权重int weight = titleWeight + contentWeight;// 将结果加入集合中wordWeight.put(word,weight);}return wordWeight;}
}
InvertedRecord类:
package com.yukuanyan.indexer.model;import lombok.Data;@Data
public class InvertedRecord {//表示 word 在文章号为 docId 的文章中权重为 weightprivate String word;private Integer docId;private Integer weight;public InvertedRecord(String word,Integer docId,Integer weight) {this.word = word;this.docId = docId;this.weight = weight;}
}
5.保存正排索引和倒排索引
由于文档的数量较多,正排索引的数量 在1w左右,倒排索引的数量在百万级比,因此在插入数据库的时候不加任何优化会很慢,因此采用了多线程+批量插入数据库的优化。
我们首先需要创建一个线程池,在indexer 包下新建config 包,在config 包下创建 AppConfig 类。AppConfig 类是 spring 容器中的 生产者,因此我们给类加上 @Configuration ,给方法加上@Bean,我们需要线程池,因此返回类型是 ExecutorService
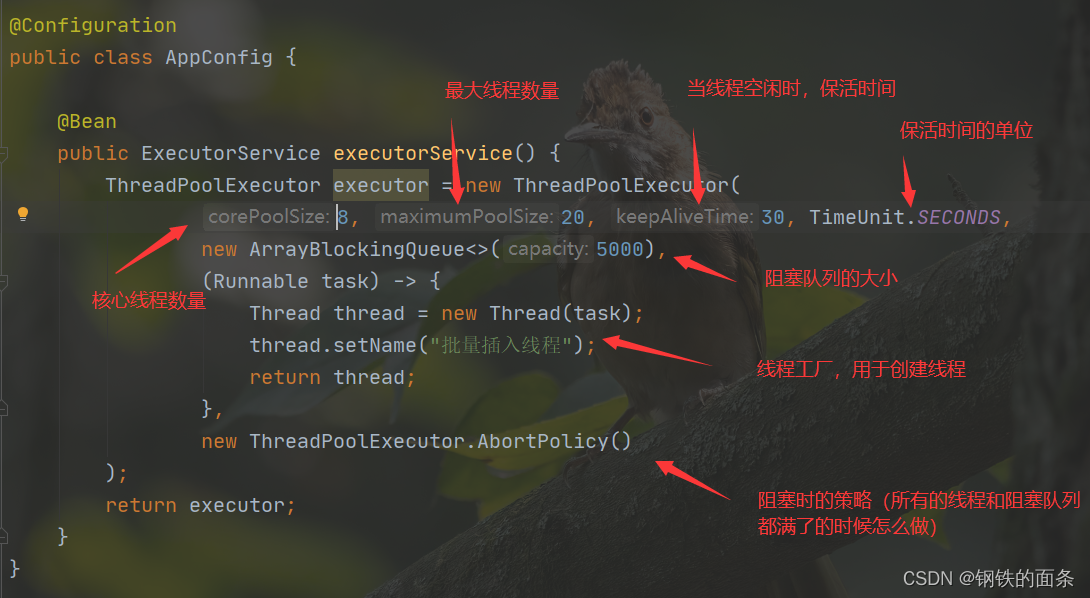
我们还需要将索引保存到数据库中。使用mybatis框架进行数据库操作需要 Mapper 接口和 对应的 Mapper.xml,因此在 indexer 包下新建 mapper 包,在mapper 包下新建 IndexerMapper 接口,在接口内定义插入正排索引和倒排索引的方法
package com.yukuanyan.indexer.mapper;import com.yukuanyan.indexer.model.Document;
import com.yukuanyan.indexer.model.InvertedRecord;
import org.apache.ibatis.annotations.Mapper;
import org.apache.ibatis.annotations.Param;
import org.springframework.stereotype.Repository;import java.util.List;@Mapper
@Repository
public interface IndexMapper {//批量插入正排索引public void batchInsertForwardIndexes(@Param("list") List documentList);//批量插入倒排索引public void batchInsertInvertedIndexes(@Param("list") List recordsList);
}
在 resource 下新建 mapper ,在mapper 下新建Mapper.xml。同时在application.yml 中配置 Mapper.xml 的 路径

之后我们就可以在Mapper.xml 内写 sql 语句了
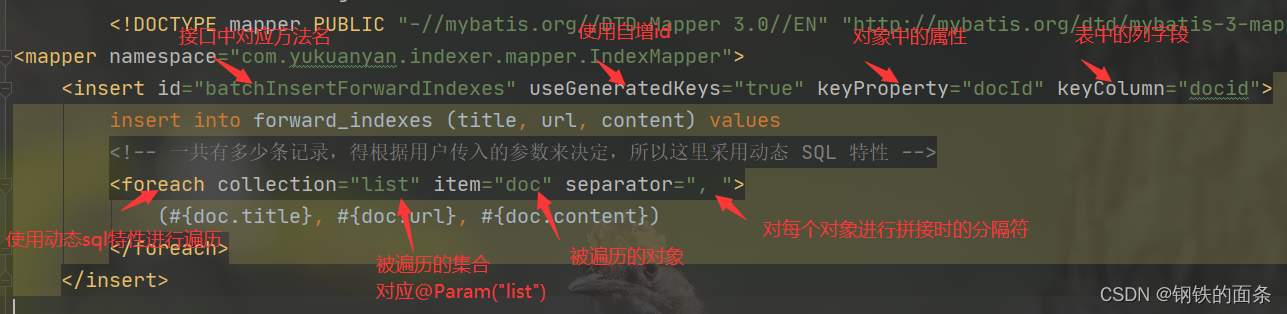
一个 mapper.xml 对应一个 接口,因此需要在 mapper.xml 中配置对应接口

批量插入正排索引的标签。由于需要获取docid因此我们需要自增id。
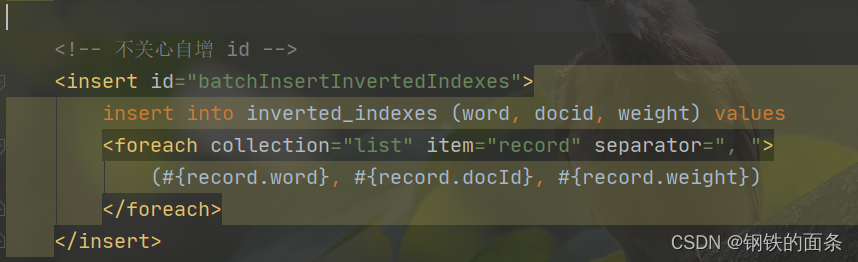
批量插入倒排索引的标签,和正排索引类似
在indexer 包下 新建 core 包,在core包下新建 IndexerManager 类,这个类用来批量保存索引,会用到线程池 和 数据库。
主要功能:保存正排索引和倒排索引。由于插入数据库不需要返回值,所以我们 继承 Runnable 接口 再提交到线程池中执行。