
声纹识别之说话人验证speaker verification
目录
一、speaker verification简介
二、主流方案和模型
1、Ecapa_TDNN模型
2、WavLm
三、代码实践
1、Ecapa_TDNN方案
a、模型结构
b、loss
c、数据处理
d、模型训练和评估
e、说话人验证推理
2、WavLm预训练方案
a、模型结构和loss
b、数据处理
c、模型训练
d、推理和评估
四、demo演示
五、总结
写在最前面,最近几个月并没有在写博客上投入时间,主要是其他事情比较多也比较忙。2022年8月以后就开始准备婚礼、看房、买房,举行婚礼和看车等等,工作上也在做项目和打一些比赛,并没有什么值得写的。由于工作需要接触到了语音领域的声纹识别,对语音识别进行了一些预研,因此在这里开一篇博客,聊一聊speaker verification学习历程。
一、speaker verification简介
Speaker Verification——说话人验证属于声纹识别领域范畴——给定两个音频,判定它们是不是同一个人所说。这里有两种不同的类型,一种是基于文本有关的,一种是基于文本无关的。基于文本有关的——每次检验的是否是同一个人说话,需要受检者说出限定范围的文本;而基于文本无关的则不需要,可以随意说话。前者相对容易一点,后者相对困难一点。Speaker Verification核心之处在于模型能够提炼出不同人声音的特征,且要有很好的区分度。
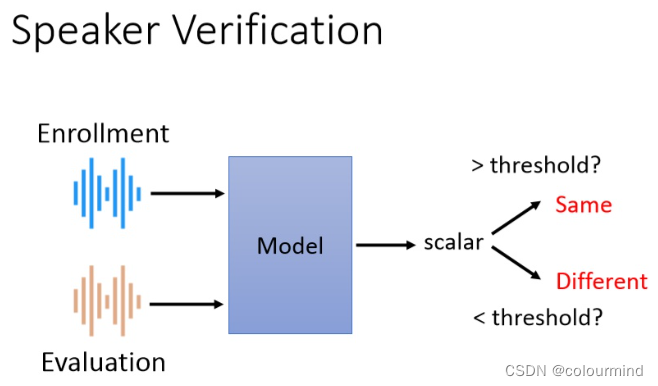
如上图所示,要判定Enrollment和Evaluation两个音频是不是同一个说话人,一般而言,可以把两个音频直接输入模型,训练一个分类模型,让模型来判定是不是同一个类别;也可以提前把Enrollment用训练好的模型提取出一个多维向量;等到Evaluation需要验证的时候,用模型同样提取响应特征向量,计算两个向量的向量度,根据阈值判定。在实际应用过程中,为了满足高效率,大多采用后者,提前把被检音频提取向量存储到对应的库中,然后检测音频实时抽取向量,计算向量,根据设定的阈值判定是否为同一个人。
在实际应用之前,需要对训练好的模型和整体的Speaker Verification系统进行评价。模型端评价根据建模的任务,一般采取F1值或者ACC、Recall等来评价。而评价实际的Speaker Verification系统,则有自己的一套评价体系和指标。主要是如下的评价指标:
FAR(False Accept Rate 错误接受率)
FRR(False Reject Rate错误拒绝率)
EER(Equal Error Rate 等错误率
FRR = Nfr/Ntarget 其中Nfr是指应该通过而被拒绝测试用例的数量,Ntarget 是指所有应该通过测试用例的总数
FAR = Nfa/Nnotarget 其中Nfa是指不应该通过也通过的测试用例的数量,Nnotarget 是指所有不应该通过测试用例的总数
EER 是指FAR==FRR时的错误率。它说话人确认系统中常用的性能评价指标
这个没有考虑错误接受以及错误拒绝不同的影响,因此为了把它们不同的影响也考虑起来,设计不同的权重,同时也把受检者是真是假的先验概率考虑进来,得到一个新的指标dcf。
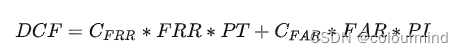
PT真实说话人出现的先验概率,PI假的说话人出现的先验概率;越严格的系统PI/PT的值越大。比较常见的比值是1:99、1:999。
通过不断的调整阈值,DCF是会变化的,取最小的dcf的时候对应的阈值,会使得整个系统有最佳的表现。
二、主流方案和模型
speaker verification发展了很多年,有许多的方案。传统的一些方案,主要是利用信号处理方式,把时序信号转换为频域信号,然后再通过一些手段进行区分。看一张计算方案的演进图(摘抄自知乎问答——声纹识别算法有哪几种):
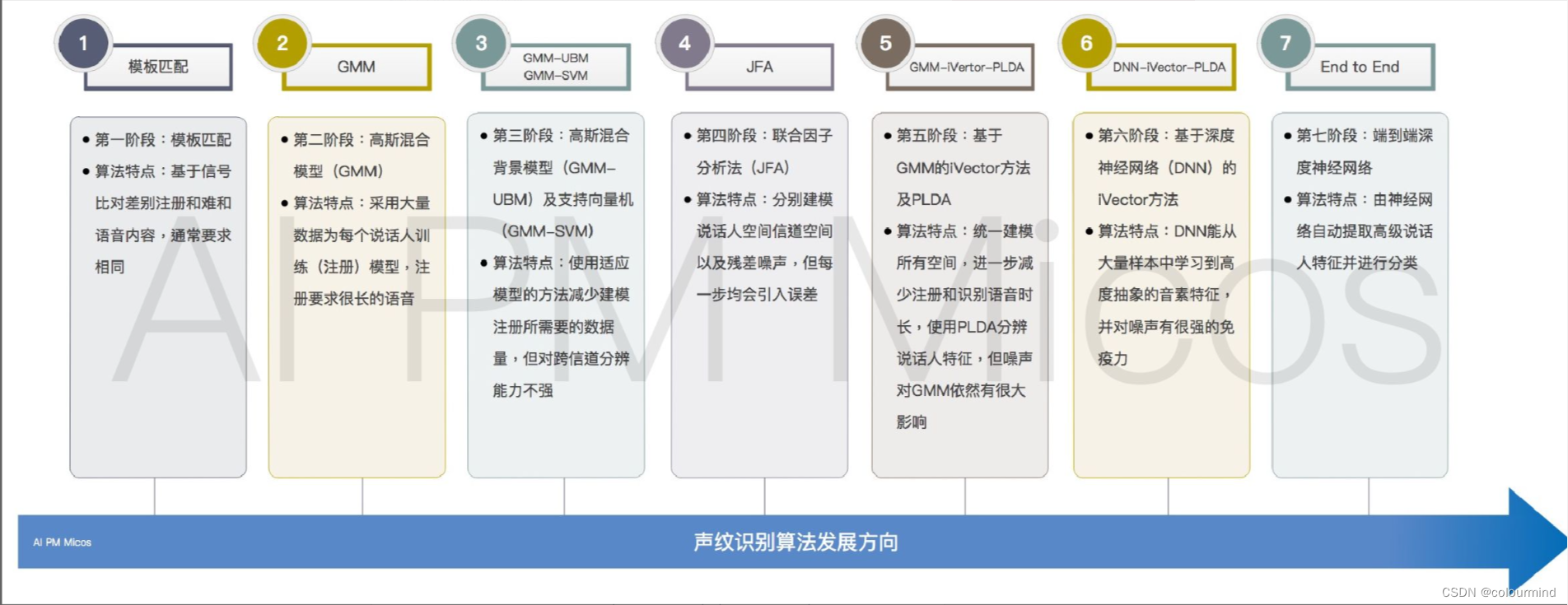
其中可能涉及到的声学特征有MFCC、FBank和Spectrogram等,以及对它的一些数据增强。时至2022年了,大家更加关注端到端的方案,使用神经网络自动提取声学特征。比较主流的是Ecapa_TDNN模型,它于2020年被提出,通过引入SE (squeeze-excitation)模块以及通道注意机制,该方案在国际声纹识别比赛(VoxSRC2020)中取得了第一名;同时在2022年的FFSVC说话人验证任务中,该模型也被作为baseline。另外就是预训练模型,在语音领域也有很多类似文本领域Bert的预训练模型,其中个人认为效果最好的就是WavLm模型。
1、Ecapa_TDNN模型
先看整体结构图:
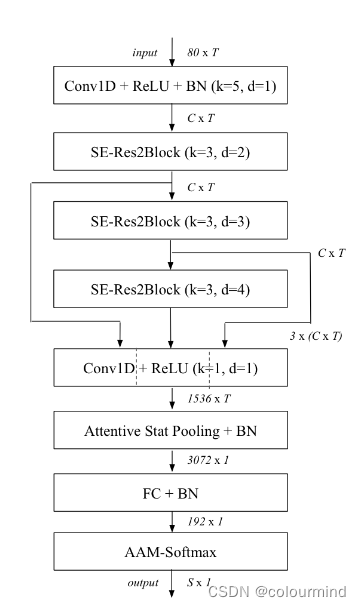
可以看到ecapa_tdnn由conv1D+BN、SE-Res2Block、ASP+BN、FC+BN以及AAM-softmax等模块构成。其中SE-Res2Block能是模型学习到音频数据中更多的全局信息,这个比之前的d-vector效果更好。
SE-Res2Block:
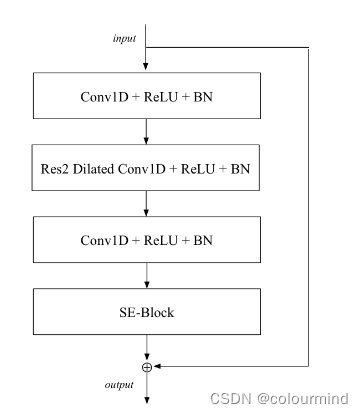
SE-Res2Block主要是Res2Block模块中引入了SE-Block模块——这是一个通道注意力模块,比较经典在各种网络中都表现的比较不错。
2、WavLm
它是微软亚洲研究院与微软 Azure 语音组使用Transformer模型架构和Denoising Masked Speech Modeling 框架直接对音频时序数据进行类似Bert的掩码预训练,使用了海量的音频数据进行了预训练,在语音任务上取得了很好的效果。
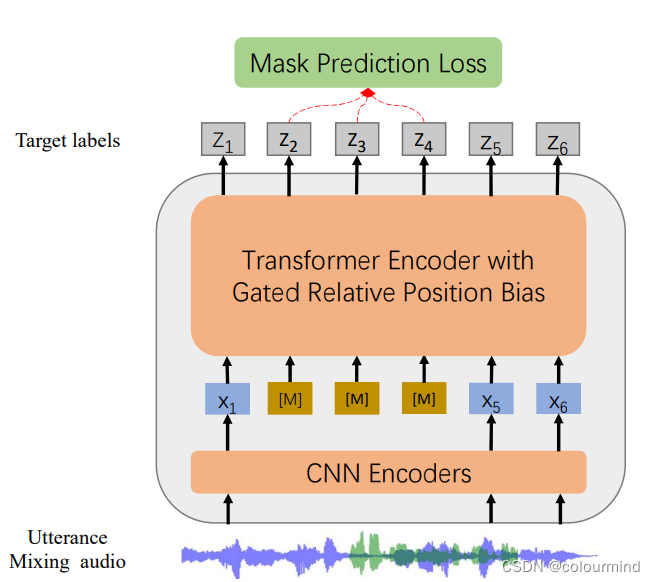
模型网络结构如图所示,特征抽取采用CNN网络层,然后特征编码采用transformer-block层,具体的模型细节这里就不分析了,可以把它看做为一个音频领域的bert,实现细节稍有不同,具体的实现可以去看huggingface的实现——WavLm和WavLmModel等。
三、代码实践
1、Ecapa_TDNN方案
a、模型结构
代码参考了百度的paddleSpeech中paddle版本和SpeechBrain中pytorch版本代码,并做了一些删减,同时也参考了一些个人的实现VoiceprintRecognition-Pytorch,对它们的代码进行了综合考量,得到下面的Ecapa_TDNN模型结构代码
import torch
import torch.nn as nn
import torch.nn.functional as F
from torch.nn import Parameterclass TDNNBlock(nn.Module):"""An implementation of TDNN."""def __init__(self, in_channels, out_channels, kernel_size, dilation, groups=1,padding=0):super(TDNNBlock, self).__init__()self.conv = nn.Conv1d(in_channels=in_channels,out_channels=out_channels,kernel_size=kernel_size, dilation=dilation,groups=groups,padding=padding)self.activation = nn.ReLU()self.bn = nn.BatchNorm1d(out_channels)def forward(self,x):x = self.conv(x)x = self.activation(x)x = self.bn(x)return xclass Res2NetBlock(torch.nn.Module):"""An implementation of Res2NetBlock w/ dilation.Example-------inp_tensor = torch.rand([8, 120, 64]).transpose(1, 2)layer = Res2NetBlock(64, 64, scale=4, dilation=3)out_tensor = layer(inp_tensor).transpose(1, 2)out_tensor.shapetorch.Size([8, 120, 64])"""def __init__(self, in_channels, out_channels, scale=8, kernel_size=3, dilation=1,padding =0):super(Res2NetBlock, self).__init__()assert in_channels % scale == 0assert out_channels % scale == 0in_channel = in_channels // scalehidden_channel = out_channels // scaleself.blocks = nn.ModuleList([TDNNBlock(in_channel,hidden_channel,kernel_size=kernel_size,dilation=dilation,padding = padding)for i in range(scale - 1)])self.scale = scaledef forward(self, x):y = []for i, x_i in enumerate(torch.chunk(x, self.scale, dim=1)):if i == 0:y_i = x_ielif i == 1:y_i = self.blocks[i - 1](x_i)else:y_i = self.blocks[i - 1](x_i + y_i)y.append(y_i)y = torch.cat(y, dim=1)return yclass SEBlock(nn.Module):"""省略了mask"""def __init__(self, in_channels, se_channels, out_channels):super(SEBlock,self).__init__()self.conv1 = nn.Conv1d(in_channels=in_channels, out_channels=se_channels, kernel_size=1)self.relu = nn.ReLU(inplace=True)self.conv2 = nn.Conv1d(in_channels=se_channels, out_channels=out_channels, kernel_size=1)self.sigmoid = nn.Sigmoid()def forward(self,x):s = x.mean(dim=2, keepdim=True)s = self.relu(self.conv1(s))s = self.sigmoid(self.conv2(s))out = s * xreturn outclass SERes2NetBlock(nn.Module):def __init__(self,in_channels,out_channels,res2net_scale=8,se_channels=128,kernel_size=1,dilation=1,groups=1,padding = 0):super(SERes2NetBlock, self).__init__()self.out_channels = out_channelsself.tdnn1 = TDNNBlock(in_channels,out_channels,kernel_size=1,dilation=1,groups=groups,)self.res2net_block = Res2NetBlock(out_channels, out_channels, res2net_scale, kernel_size,padding, dilation)self.tdnn2 = TDNNBlock(out_channels,out_channels,kernel_size=1,dilation=1,groups=groups,)self.se_block = SEBlock(out_channels, se_channels, out_channels)self.shortcut = Noneif in_channels != out_channels:self.shortcut = nn.Conv1d(in_channels=in_channels,out_channels=out_channels,kernel_size=1,)def forward(self, x):""" Processes the input tensor x and returns an output tensor."""residual = xif self.shortcut:residual = self.shortcut(x)x = self.tdnn1(x)x = self.res2net_block(x)x = self.tdnn2(x)x = self.se_block(x)return x + residualclass AttentiveStatsPool(nn.Module):def __init__(self, in_dim, bottleneck_dim):super(AttentiveStatsPool,self).__init__()# Use Conv1d with stride == 1 rather than Linear, then we don't need to transpose inputs.self.linear1 = nn.Conv1d(in_dim, bottleneck_dim, kernel_size=1) # equals W and b in the paperself.linear2 = nn.Conv1d(bottleneck_dim, in_dim, kernel_size=1) # equals V and k in the paperdef forward(self, x):# DON'T use ReLU here! In experiments, I find ReLU hard to converge.alpha = torch.tanh(self.linear1(x))alpha = torch.softmax(self.linear2(alpha), dim=2)mean = torch.sum(alpha * x, dim=2)residuals = torch.sum(alpha * x ** 2, dim=2) - mean ** 2std = torch.sqrt(residuals.clamp(min=1e-9))return torch.cat([mean, std], dim=1)class ECAPATDNN(nn.Module):def __init__(self,input_size,lin_neurons=192,channels=[512, 512, 512, 512, 1536],kernel_sizes=[5, 3, 3, 3, 1],dilations=[1, 2, 3, 4, 1],attention_channels=128,res2net_scale=8,se_channels=128,groups=[1, 1, 1, 1, 1],paddings = [0,2,3,4,0]):super(ECAPATDNN, self).__init__()assert len(channels) == len(kernel_sizes)assert len(channels) == len(dilations)self.emb_size = lin_neuronsself.channels = channelsself.blocks = nn.ModuleList()self.blocks.append(TDNNBlock(input_size,channels[0],kernel_sizes[0],dilations[0],groups[0]))for i in range(1,len(channels) -1):self.blocks.append(SERes2NetBlock(channels[i-1],channels[i],res2net_scale, se_channels, kernel_sizes[i],dilations[i],groups[i],paddings[i]))self.mfa = TDNNBlock(channels[-1],channels[-1],kernel_sizes[-1],dilations[-1],groups[-1])self.asp = AttentiveStatsPool(channels[-1],attention_channels)self.asp_bn = nn.BatchNorm1d(channels[-1] * 2)self.fc = nn.Conv1d(in_channels=channels[-1] * 2,out_channels=lin_neurons,kernel_size=1,)def forward(self,x):xl = []for layer in self.blocks:x = layer(x)xl.append(x)# Multi-layer feature aggregationx = torch.cat(xl[1:], dim=1)x = x.datax = self.mfa(x)# Attentive Statistical Poolingx = self.asp(x)x = self.asp_bn(x)x = x.unsqueeze(2)# Final linear transformationx = self.fc(x)return xclass SpeakerIdentificationModel(nn.Module):def __init__(self,backbone,num_class=1,dropout=0.1):super(SpeakerIdentificationModel, self).__init__()self.backbone = backboneif dropout > 0:self.dropout = nn.Dropout(dropout)else:self.dropout = Noneinput_size = self.backbone.emb_size# the final layer nn.Linear 采用不同的权重初始化self.weight = Parameter(torch.FloatTensor(num_class, input_size), requires_grad=True)nn.init.xavier_normal_(self.weight, gain=1)def forward(self,x):x = self.backbone(x)if self.dropout is not None:x = self.dropout(x)logits = F.linear(F.normalize(x.squeeze(2)),weight=F.normalize(self.weight,dim=-1))return logits
b、loss
这部分代码摘抄自VoiceprintRecognition-Pytorch
Additive Angular Margin Loss(加性角度间隔损失函数)结合KLDivLoss(KL散度loss)得到最后的AAMloss
import mathimport torch
import torch.nn as nn
import torch.nn.functional as Fclass AdditiveAngularMargin(nn.Module):def __init__(self, margin=0.0, scale=1.0, easy_margin=False):"""The Implementation of Additive Angular Margin (AAM) proposedin the following paper: '''Margin Matters: Towards More Discriminative Deep Neural Network Embeddings for Speaker Recognition'''(https://arxiv.org/abs/1906.07317)Args:margin (float, optional): margin factor. Defaults to 0.0.scale (float, optional): scale factor. Defaults to 1.0.easy_margin (bool, optional): easy_margin flag. Defaults to False."""super(AdditiveAngularMargin, self).__init__()self.margin = marginself.scale = scaleself.easy_margin = easy_marginself.cos_m = math.cos(self.margin)self.sin_m = math.sin(self.margin)self.th = math.cos(math.pi - self.margin)self.mm = math.sin(math.pi - self.margin) * self.margindef forward(self, outputs, targets):cosine = outputs.float()sine = torch.sqrt(1.0 - torch.pow(cosine, 2))phi = cosine * self.cos_m - sine * self.sin_mif self.easy_margin:phi = torch.where(cosine > 0, phi, cosine)else:phi = torch.where(cosine > self.th, phi, cosine - self.mm)outputs = (targets * phi) + ((1.0 - targets) * cosine)return self.scale * outputsclass AAMLoss(nn.Module):def __init__(self, margin=0.2, scale=30, easy_margin=False):super(AAMLoss, self).__init__()self.loss_fn = AdditiveAngularMargin(margin=margin, scale=scale, easy_margin=easy_margin)self.criterion = torch.nn.KLDivLoss(reduction="sum")def forward(self, outputs, targets):targets = F.one_hot(targets, outputs.shape[1]).float()predictions = self.loss_fn(outputs, targets)predictions = F.log_softmax(predictions, dim=1)loss = self.criterion(predictions, targets) / targets.sum()return lossc、数据处理
这部分代码功能是对wav或者mp3数据进行语音特征处理,比如fbank(melspectrogram)、spectrogram以及梅尔倒谱系数mffcc等等
import random
import torch
from torch.utils.data import Dataset
import torchaudio
from tqdm import tqdmclass AudioDataReader(Dataset):def __init__(self, data_list_path,feature_method='melspectrogram',mode='train',sr=16000,chunk_duration=3,min_duration=0.5,label2ids = {},augmentors=None):super(AudioDataReader, self).__init__()assert data_list_path is not Nonewith open(data_list_path,'r',encoding='utf-8') as f:self.lines = f.readlines()[0:]self.feature_method = feature_methodself.mode = modeself.sr = srself.chunk_duration = chunk_durationself.min_duration = min_durationself.augmentors = augmentorsself.label2ids = label2idsself.audiofeatures = self.getaudiofeatures()def load_audio(self, audio_path,feature_method='melspectrogram',mode='train',sr=16000,chunk_duration=3,min_duration=0.5,augmentors=None):"""加载并预处理音频:param audio_path: 音频路径:param feature_method: 预处理方法melspectrogram(Fbank)梅尔频谱/MFCC梅尔倒谱系数/spectrogram声谱图:param mode: 对数据处理的方式,包括train,eval,infer:param sr: 采样率:param chunk_duration: 训练或者评估使用的音频长度:param min_duration: 最小训练或者评估的音频长度:param augmentors: 数据增强方法:return:"""wav, sample_rate = torchaudio.load(audio_path) # 加载音频返回的是张量num_wav_samples = wav.shape[1]# 数据太短不利于训练if mode == 'train':if num_wav_samples < int(min_duration * sr):raise Exception(f'音频长度小于{min_duration}s,实际长度为:{(num_wav_samples / sr):.2f}s')# print(f'音频长度小于{min_duration}s,实际长度为:{(num_wav_samples / sr):.2f}s')# return None# 对小于训练长度的复制补充num_chunk_samples = int(chunk_duration * sr)if num_wav_samples < num_chunk_samples:times = int(num_chunk_samples / num_wav_samples) - 1shortages = []temp_num_wav_samples = num_wav_samplesshortages.append(wav)if times >= 1:for _ in range(times):shortages.append(wav)temp_num_wav_samples += num_wav_samplesshortages.append(wav[:,0:(num_chunk_samples - temp_num_wav_samples)])else:shortages.append(wav[:,0:(num_chunk_samples - num_wav_samples)])wav = torch.cat(shortages, dim=1)# 裁剪需要的数据if mode == 'train':# 随机裁剪num_wav_samples = wav.shape[1]num_chunk_samples = int(chunk_duration * sr)if num_wav_samples > num_chunk_samples + 1:start = random.randint(0, num_wav_samples - num_chunk_samples - 1)end = start + num_chunk_sampleswav = wav[:,start:end]# # 对每次都满长度的再次裁剪# if random.random() > 0.5:# wav[:random.randint(1, sr // 4)] = 0 #加入了静音数据# wav = wav[:-random.randint(1, sr // 4)]# 数据增强if augmentors is not None:for key, augmentor in augmentors.items():if key == 'specaug':continuewav = wav.numpy()#转换为numpy,然后做增强wav = augmentor(wav)wav = torch.from_numpy(wav)elif mode == 'eval':# 为避免显存溢出,只裁剪指定长度num_wav_samples = wav.shape[1]num_chunk_samples = int(chunk_duration * sr)if num_wav_samples > num_chunk_samples + 1:wav = wav[:,0:num_chunk_samples]if feature_method == "melspectrogram":# 梅尔频谱 Fbankfeatures = torchaudio.transforms.MelSpectrogram(sample_rate=sr, n_fft=400, n_mels=80, hop_length=160, win_length=400)(wav)elif feature_method == "spectrogram":# 声谱图features = torchaudio.transforms.Spectrogram( n_fft=400, win_length=400, hop_length=160)(wav)elif feature_method == "MFCC":features = torchaudio.transforms.MFCC(sample_rate=sr, n_fft=400, n_mels=80, hop_length=160, win_length=400)(wav)else:raise Exception(f'预处理方法 {feature_method} 不存在!')# 数据增强if mode == 'train' and augmentors is not None:for key, augmentor in augmentors.items():if key == 'specaug':features = augmentor(features)# 需要归一化features = torch.nn.LayerNorm(features.shape[-1])(features).squeeze(0)return featuresdef getaudiofeatures(self):res = []for line in tqdm(self.lines,desc= self.mode + ' load all audios',ncols=100):temp = []try:audio_path, label = line.replace('\n', '').split('\t')label = self.label2ids[label]features = self.load_audio(audio_path=audio_path, feature_method=self.feature_method, mode=self.mode,sr=self.sr, chunk_duration=self.chunk_duration,min_duration=self.min_duration,augmentors=self.augmentors)label = torch.as_tensor(label, dtype=torch.long)temp.append(features)temp.append(label)res.append(temp)except Exception as e:print(e+',load audio data exception')return res@propertydef input_size(self):if self.feature_method == 'melspectrogram':return 80elif self.feature_method == 'spectrogram':return 201else:raise Exception(f'预处理方法 {self.feature_method} 不存在!')def __getitem__(self, item):return self.audiofeatures[item][0], self.audiofeatures[item][1]def __len__(self):return len(self.audiofeatures)值得注意的是没有在__getitem__()函数中读取音频加载数据,而是直接全部加载到内存中,如果数据量过大还是要在_getitem__()函数中读取音频加载数据,减小内存消耗,当然训练速度会减慢。
d、模型训练和评估
数据集采用公共数据集:zhvoice: Chinese voice corpus中的zhstcmds数据
"zhstcmds": {"character_W": 111.9317,"duration_H": 74.53628,"n_audio_per_speaker": 120.0,"n_character_per_sentence": 10.909522417153998,"n_minute_per_speaker": 5.230616140350877,"n_second_per_audio": 2.6153080701754385,"n_speaker": 855,"sentence_W": 10.26,"size_MB": 767.7000274658203}总计104963条数据,随机切分,验证集10000条,训练集94963条数据。
训练代码如下
from models.loss import AAMLoss
from models.ecapa_tdnn import SpeakerIdentificationModel,ECAPATDNN
# from models.ecapa_tdnn import SpeakerIdetification,EcapaTdnn
from tools.log import Logger
from tools.progressbar import ProgressBar
from data_utils.reader import AudioDataReader
from data_utils.noise_perturb import NoisePerturbAugmentor
from data_utils.speed_perturb import SpeedPerturbAugmentor
from data_utils.volum_perturb import VolumePerturbAugmentor
from data_utils.spec_augment import SpecAugmentorfrom torch.utils.data import DataLoader
import torch
import os
from torch.optim import AdamW
from torch.optim.lr_scheduler import CosineAnnealingLR
import argparseimport random
import numpy as np
from torch.utils.tensorboard import SummaryWriter
from datetime import datetime
import yaml
import torch.nn as nndef parse_args():parser = argparse.ArgumentParser()parser.add_argument("--train_datas_path", type=str, default='./data/train_audio_paths.txt', help="train text file")parser.add_argument("--val_datas_path", type=str, default='./data/val_audio_paths.txt', help="val text file")# parser.add_argument("--train_datas_path", type=str, default='./data/train_audio_paths_small.txt', help="train text file")# parser.add_argument("--val_datas_path", type=str, default='./data/val_audio_paths_small.txt', help="val text file")parser.add_argument("--log_file", type=str, default="./log_output/speaker_identification.log", help="log_file")parser.add_argument("--model_out", type=str, default="./output/", help="model output path")parser.add_argument("--batch_size", type=int, default=64, help="batch size")parser.add_argument("--epochs", type=int, default=30, help="epochs")parser.add_argument("--lr", type=float, default=1e-3, help="epochs")parser.add_argument("--random_seed", type=int, default=100, help="random_seed")parser.add_argument("--device", type=str, default='1', help="device")args = parser.parse_args()return argsdef training(args):os.environ['CUDA_VISIBLE_DEVICES'] = args.devicelogger = Logger(log_name='SI',log_level=10,log_file=args.log_file).loggerlogger.info(args)label2ids = {}id = 0with open(args.train_datas_path,'r',encoding='utf-8') as f:lines = f.readlines()for line in lines:line = line.strip('\n')if line.split('\t')[-1] not in label2ids:label2ids[line.split('\t')[-1]] = idid += 1with open(args.val_datas_path,'r',encoding='utf-8') as f:lines = f.readlines()for line in lines:line = line.strip('\n')if line.split('\t')[-1] not in label2ids:label2ids[line.split('\t')[-1]] = idid += 1augmentors = {}with open("augment.ymal",'r', encoding="utf-8") as fp:configs = yaml.load(fp, Loader=yaml.FullLoader)augmentors['noise'] = NoisePerturbAugmentor(**configs['noise'])augmentors['speed'] = SpeedPerturbAugmentor(**configs['speed'])augmentors['volume'] = VolumePerturbAugmentor(**configs['volume'])augmentors['specaug'] = SpecAugmentor(**configs['specaug'])augmentors = Nonetime_srt = datetime.now().strftime('%Y-%m-%d')save_path = os.path.join(args.model_out,time_srt)if not os.path.exists(save_path):os.makedirs(save_path)logger.info(save_path)device = "cuda:0" if torch.cuda.is_available() else "cpu"train_dataset = AudioDataReader(feature_method='melspectrogram',data_list_path=args.train_datas_path,mode='train', label2ids=label2ids, augmentors=augmentors)train_dataloader = DataLoader(train_dataset,shuffle=True,batch_size=args.batch_size )val_dataset = AudioDataReader(feature_method='melspectrogram', data_list_path=args.val_datas_path, mode='eval', label2ids = label2ids,augmentors=augmentors)val_dataloader = DataLoader(val_dataset, shuffle=True, batch_size=args.batch_size)num_class = len(label2ids)logger.info('num_class:%d'%num_class)ecapa_tdnn = ECAPATDNN(input_size=train_dataset.input_size)model = SpeakerIdentificationModel(backbone=ecapa_tdnn, num_class=num_class).to(device)# ecapa_tdnn = EcapaTdnn(input_size=train_dataset.input_size)# model = SpeakerIdetification(backbone=ecapa_tdnn, num_class=num_class).to(device)# logger.info(model)loss_function = AAMLoss()optimizer = AdamW(lr=args.lr,params=model.parameters())scheduler = CosineAnnealingLR(optimizer,T_max=args.epochs)logger.info("***** Running training *****")logger.info(" Num examples = %d" % len(train_dataloader))logger.info(" Num Epochs = %d" % args.epochs)writer = SummaryWriter('./runs/' + time_srt + '/')best_acc = 0total_step = 0unimproving_count = 0for epoch in range(args.epochs):pbar = ProgressBar(n_total=len(train_dataloader), desc='Training')model.train()total_loss = 0for step, batch in enumerate(train_dataloader):batch = [t.to(device) for t in batch]audio = batch[0]speakers = batch[1]output = model(audio)loss = loss_function(output, speakers)optimizer.zero_grad()# loss.backward(retain_graph=True)loss.backward()optimizer.step()total_step += 1writer.add_scalar('Train/Learning loss', loss.item(), total_step)total_loss += loss.item()pbar(step, {'loss': loss.item()})val_acc = evaluate(model, val_dataloader, device)if best_acc < val_acc:best_acc = val_accsave_path = os.path.join(save_path,"ecapa_tdnn.bin")torch.save(model.state_dict(),save_path)is_improving = Trueunimproving_count = 0else:is_improving = Falseunimproving_count += 1if is_improving:logger.info(f"Train epoch [{epoch+1}/{args.epochs}],batch [{step+1}],Best_acc: {best_acc},Val_acc:{val_acc}, lr:{scheduler.get_lr()[0]}, total_loss:{round(total_loss,4)}. Save model!")else:logger.info(f"Train epoch [{epoch+1}/{args.epochs}],batch [{step+1}],Best_acc: {best_acc},Val_acc:{val_acc}, lr:{scheduler.get_lr()[0]}, total_loss:{round(total_loss,4)}.")writer.add_scalar('Val/val_acc', val_acc, total_step)writer.add_scalar('Val/best_acc', best_acc, total_step)writer.add_scalar('Train/Learning rate', scheduler.get_lr()[0], total_step)scheduler.step()if unimproving_count >= 5:logger.info('unimproving %d epochs, early stop!'%unimproving_count)breakdef evaluate(model,val_dataloader,device):total = 0correct_total = 0model.eval()with torch.no_grad():pbar = ProgressBar(n_total=len(val_dataloader), desc='evaluate')for step, batch in enumerate(val_dataloader):batch = [t.to(device) for t in batch]audio = batch[0]speakers = batch[1]output = model(audio)total += speakers.shape[0]preds = torch.argmax(output,dim=-1)correct = (speakers==preds).sum().item()pbar(step, {})correct_total += correctacc = correct_total/totalmodel.train()return accdef set_seed(seed):torch.manual_seed(seed)torch.cuda.manual_seed(seed)np.random.seed(seed)random.seed(seed)torch.backends.cudnn.deterministic = Truedef collate_fn(batch):features,labels = zip(*batch)return featuresif __name__ == '__main__':args = parse_args()set_seed(args.random_seed)training(args)训练过程中采用的评估指标直接是分类准确率,日志如下:

验证集分类准确率是0.9503
e、说话人验证推理
使用上述训练好的Ecapa_TDNN模型对经过数据处理后的音频数据抽取向量特征,计算相似度,通过设定的阈值来判定是否为同一个说话人,当然这里的阈值就需要经过构建的验证数据集进行搜索得到最佳阈值。
from models.ecapa_tdnn import SpeakerIdentificationModel,ECAPATDNN
from tools.log import Logger
from tools.progressbar import ProgressBar
from data_utils.reader import AudioDataReader
from data_utils.noise_perturb import NoisePerturbAugmentor
from data_utils.speed_perturb import SpeedPerturbAugmentor
from data_utils.volum_perturb import VolumePerturbAugmentor
from data_utils.spec_augment import SpecAugmentor
from torch.utils.data import DataLoader
import torch
import os
import argparse
import numpy as np
import yaml
from tqdm import tqdm
import matplotlib.pyplot as plt
import time
import random
random.seed(100)def parse_args():parser = argparse.ArgumentParser()parser.add_argument("--train_datas_path", type=str, default='./data/train_audio_paths.txt', help="train text file")parser.add_argument("--val_datas_path", type=str, default='./data/val_audio_paths.txt', help="val text file")parser.add_argument("--log_file", type=str, default="./log_output/speaker_identification_evaluate.log", help="log_file")parser.add_argument("--batch_size", type=int, default=64, help="batch size")parser.add_argument("--random_seed", type=int, default=100, help="random_seed")parser.add_argument("--device", type=str, default='0', help="device")args = parser.parse_args()return argsdef evaluate(args):os.environ['CUDA_VISIBLE_DEVICES'] = args.devicelogger = Logger(log_name='SI',log_level=10,log_file=args.log_file).loggerlogger.info(args)label2ids = {}id = 0with open(args.train_datas_path,'r',encoding='utf-8') as f:lines = f.readlines()for line in lines:line = line.strip('\n')if line.split('\t')[-1] not in label2ids:label2ids[line.split('\t')[-1]] = idid += 1with open(args.val_datas_path,'r',encoding='utf-8') as f:lines = f.readlines()for line in lines:line = line.strip('\n')if line.split('\t')[-1] not in label2ids:label2ids[line.split('\t')[-1]] = idid += 1augmentors = {}with open("augment.ymal",'r', encoding="utf-8") as fp:configs = yaml.load(fp, Loader=yaml.FullLoader)augmentors['noise'] = NoisePerturbAugmentor(**configs['noise'])augmentors['speed'] = SpeedPerturbAugmentor(**configs['speed'])augmentors['volume'] = VolumePerturbAugmentor(**configs['volume'])augmentors['specaug'] = SpecAugmentor(**configs['specaug'])augmentors = Nonedevice = "cuda:0" if torch.cuda.is_available() else "cpu"val_dataset = AudioDataReader(feature_method='melspectrogram', data_list_path=args.val_datas_path, mode='eval', label2ids = label2ids,augmentors=augmentors)val_dataloader = DataLoader(val_dataset, shuffle=True, batch_size=args.batch_size)num_class = 875logger.info('num_class:%d'%num_class)ecapa_tdnn = ECAPATDNN(input_size=val_dataset.input_size)model = SpeakerIdentificationModel(backbone=ecapa_tdnn, num_class=num_class).to(device)weights = torch.load('./output/2022-11-07/ecapa_tdnn.bin')model.load_state_dict(weights)model.eval()logger.info("***** Running evaluate *****")logger.info(" Num examples = %d" % len(val_dataset))pbar = ProgressBar(n_total=len(val_dataloader), desc='extract features')model.eval()labels = []features = []with torch.no_grad():for step, batch in enumerate(val_dataloader):batch = [t.to(device) for t in batch]audio = batch[0]speakers = batch[1]output = model.backbone(audio)labels.append(speakers)features.append(output.squeeze(2))pbar(step,info={'step':step})labels = torch.cat(labels)features = torch.cat(features)scores_pos = []scores_neg = []y_true_pos = []y_true_neg = []for i in tqdm(range(features.shape[0]),desc='两两计算相似度',ncols=100):query = features[i]inside = features[i:,:]temp = (labels[i] == labels[i:]).detach().long()pos_index = torch.nonzero(temp==1)neg_index = torch.nonzero(temp==0)pos_label = torch.take(temp,pos_index).squeeze(1).detach().cpu().tolist()neg_label = torch.take(temp, neg_index).squeeze(1).detach().cpu().tolist()cos = torch.cosine_similarity(query, inside, dim=-1)pos_score = torch.take(cos,pos_index).squeeze(1).detach().cpu().tolist()neg_score = torch.take(cos,neg_index).squeeze(1).detach().cpu().tolist()y_true_pos.extend(pos_label)y_true_neg.extend(neg_label)scores_pos.extend(pos_score)scores_neg.extend(neg_score)print('len(y_true_neg)',len(y_true_neg))print('len(y_true_pos)',len(y_true_pos))print('len(scores_pos)', len(scores_pos))print('len(scores_neg)', len(scores_neg))if len(y_true_pos) * 99 < len(y_true_neg):indexs = random.choices(list(range(len(y_true_neg))),k=len(y_true_pos)*99)scores = scores_posy_true = y_true_posfor index in indexs:scores.append(scores_neg[index])y_true.append(y_true_neg[index])else:scores = scores_pos + scores_negy_true = y_true_pos + y_true_negprint('len(scores)', len(scores))print('len(y_true)', len(y_true))scores = torch.tensor(scores,dtype=torch.float32)y_true = torch.tensor(y_true,dtype=torch.long)# choice_best_threshold(scores, y_true)choice_best_threshold_dcf(scores, y_true)def choice_best_threshold_dcf(scores, y_true):thresholds = []fars = []frrs = []dcfs = []precisions = []recalls = []f1s = []max_precision = 0max_recall = 0max_f1 = 0f1_threshold = 0min_dcf = 1d_threshold = 0cfr = 1cfa =1err = 0.0err_threshold = 0diff = 1for i in tqdm(range(100), desc='choice_best_threshold', ncols=100):threshold = 0.01 * ithresholds.append(threshold)y_preds = (scores > threshold).long()tp = ((y_true == 1) * (y_preds == 1)).sum().item()fp = ((y_true == 0) * (y_preds == 1)).sum().item()tn = ((y_true == 0) * (y_preds == 0)).sum().item()fn = ((y_true == 1) * (y_preds == 0)).sum().item()pos = tp + fnneg = tn + fpprecision = tp / (tp + fp+1e-13)recall = tp / (tp + fn+1e-13)f1 = 2 * precision * recall / (precision + recall + 1e-13)far = fp / (fp + tn + 1e-13)frr = fn / (tp + fn + 1e-13)dcf = cfa* far *(neg/(neg+pos)) + cfr* frr *(pos/(pos+neg))precisions.append(precision)recalls.append(recall)f1s.append(f1)fars.append(far)frrs.append(frr)dcfs.append(dcf)if max_precision < precision:max_precision = precisionif max_recall < recall:max_recall = recallif max_f1 < f1:max_f1 = f1f1_threshold = thresholdif min_dcf > dcf:min_dcf = dcfd_threshold = thresholdif abs(far-frr) < diff:err = (far+frr)/2diff = abs(far-frr)err_threshold = thresholdprint(pos + neg)print('threshold:%.4f err:%.4f'%(err_threshold, err))print("d_threshold:%.4f, min_dcf%.4f"%(d_threshold, min_dcf))print("f1_threshold:%.4f, max_f1%.4f" % (f1_threshold, max_f1))start = time.time()plt.figure(figsize=(30,30),dpi=80)plt.title('2D curve ')plt.plot(thresholds, frrs, label='frr')plt.plot(thresholds, fars, label='far')plt.plot(thresholds, dcfs, label='dcf')plt.plot(thresholds, precisions, label='pre')plt.plot(thresholds, recalls, label='recall')plt.plot(thresholds, f1s, label='f1')plt.legend(loc=0)plt.scatter(d_threshold, min_dcf, c='red', s=100)plt.text(d_threshold, min_dcf, " min_dcf(%.4f,%.4f)"%(d_threshold, min_dcf))plt.scatter(err_threshold,err,c='blue',s=100)plt.text(err_threshold,err," err(%.4f,%.4f)"%(err_threshold,err))plt.scatter(f1_threshold, max_f1, c='yellow', s=100)plt.text(f1_threshold, max_f1, " f1(%.4f,%.4f)"%(f1_threshold, max_f1))plt.xlabel('threshold')plt.ylabel('frr f dcf recall or precision')plt.xticks(thresholds[::2])plt.yticks(thresholds[::2])end = time.time()print('plot time is', end - start)plt.savefig('ecapatdnn_2d_curve_voiceprint_dcf.png')plt.show()print("finish")def choice_best_threshold(scores,y_true):best_precision_threshold = 0precision_best = 0precision_recall = 0precision_f1 = 0tp_1 = 0fp_1 = 0fn_1 = 0tn_1 = 0best_recall_threshold = 0recall_best = 0recall_precision = 0recall_f1 = 0tp_2 = 0fp_2 = 0fn_2 = 0tn_2 = 0best_f1_threshold = 0f1_best = 0f1_precision = 0f1_recall = 0tp_3 = 0fp_3 = 0fn_3 = 0tn_3 = 0fars = []#误接受率frrs = []#误拒识率far_min = 1frr_min = 1thresholds = []err = Nonetp_4 = 0fp_4 = 0fn_4 = 0tn_4 = 0diff = 1for i in tqdm( range(100),desc='choice_best_threshold',ncols=100):threshold = 0.01 * ithresholds.append(threshold)y_preds = (scores > threshold).long()tp = ((y_true == 1)*(y_preds==1)).sum().item()fp = ((y_true == 0)*(y_preds==1)).sum().item()tn = ((y_true==0)*(y_preds==0)).sum().item()fn = ((y_true==1)*(y_preds==0)).sum().item()precision = tp /(tp+fp)recall = tp/(tp+fn)f1 = 2*precision*recall/(precision+recall + 1e-13)far = fp/(fp+tn)frr = fn/(tp+fn)fars.append(far)frrs.append(frr)if precision > precision_best:precision_best = precisionbest_precision_threshold = thresholdprecision_recall = recallprecision_f1 = f1tp_1 = tpfp_1 = fpfn_1 = fntn_1 = tnif recall > recall_best:recall_best = recallbest_recall_threshold = thresholdrecall_precision = precisionrecall_f1 = f1tp_2 = tpfp_2 = fpfn_2 = fntn_2 = tnif f1 > f1_best:f1_best = f1f1_precision = precisionf1_recall = recallbest_f1_threshold = thresholdtp_3 = tpfp_3 = fpfn_3 = fntn_3 = tnif abs(far-frr) < diff:diff = abs(far-frr)err = (far+frr)/2far_min = farfrr_min = frrtp_4 = tpfp_4 = fpfn_4 = fntn_4 = tnprint(f"tp:{tp_4} fp{fp_4} tn{tn_4} fn{fn_4}")print("frr_min:%.4f,far_min:%.4f,err:%.4f"%(frr_min,far_min,err))print("precision:%.4f recall:%.4f"%(tp_4 /(tp_4+fp_4), tp_4/(tp_4+fn_4)))print('*'*50)print(f"tp:{tp_1} fp{fp_1} tn{tn_1} fn{fn_1}")print('best_precision_threshold:%.4f, precision_best:%.4f precision_recall:%.4f precision_f1:%.4f'%(best_precision_threshold,precision_best,precision_recall, precision_f1))print('*' * 50)print(f"tp:{tp_2} fp{fp_2} tn{tn_2} fn{fn_2}")print('best_recall_threshold:%.4f, recall_best:%.4f recall_precision:%.4f recall_f1:%.4f' % (best_recall_threshold, recall_best, recall_precision, recall_f1))print('*' * 50)print(f"tp:{tp_3} fp{fp_3} tn{tn_3} fn{fn_3}")print("frr:%.4f,far:%.4f"%(fn_3/(fn_3+tp_3),fp_3/(fp_3+tn_3)))print('best_f1_threshold:%.4f, f1_best:%.4f f1_precision:%.4f f1_recall:%.4f' % (best_f1_threshold, f1_best, f1_precision, f1_recall))print('*' * 50)# print(fars[0],"--",frrs[0])# print(fars[-1], "--", frrs[-1])## plt.figure(figsize=(20,20),dpi=80)# plt.title('2D curve ')# plt.plot(fars, frrs)# plt.plot(thresholds,thresholds)# plt.scatter(err,err,c='red',s=100)# plt.text(err,err,(err,err))## plt.xlabel('far')# plt.ylabel('frr')# plt.xticks(thresholds[::2])# plt.yticks(thresholds[::2])# plt.show()# plt.savefig('2d_curve_voiceprint_det.png')def set_seed(seed):torch.manual_seed(seed)torch.cuda.manual_seed(seed)np.random.seed(seed)random.seed(seed)torch.backends.cudnn.deterministic = Truedef collate_fn(batch):features,labels = zip(*batch)return featuresif __name__ == '__main__':args = parse_args()set_seed(args.random_seed)evaluate(args)采用far和frr以及errdct等评价指标来获取最佳threshold:
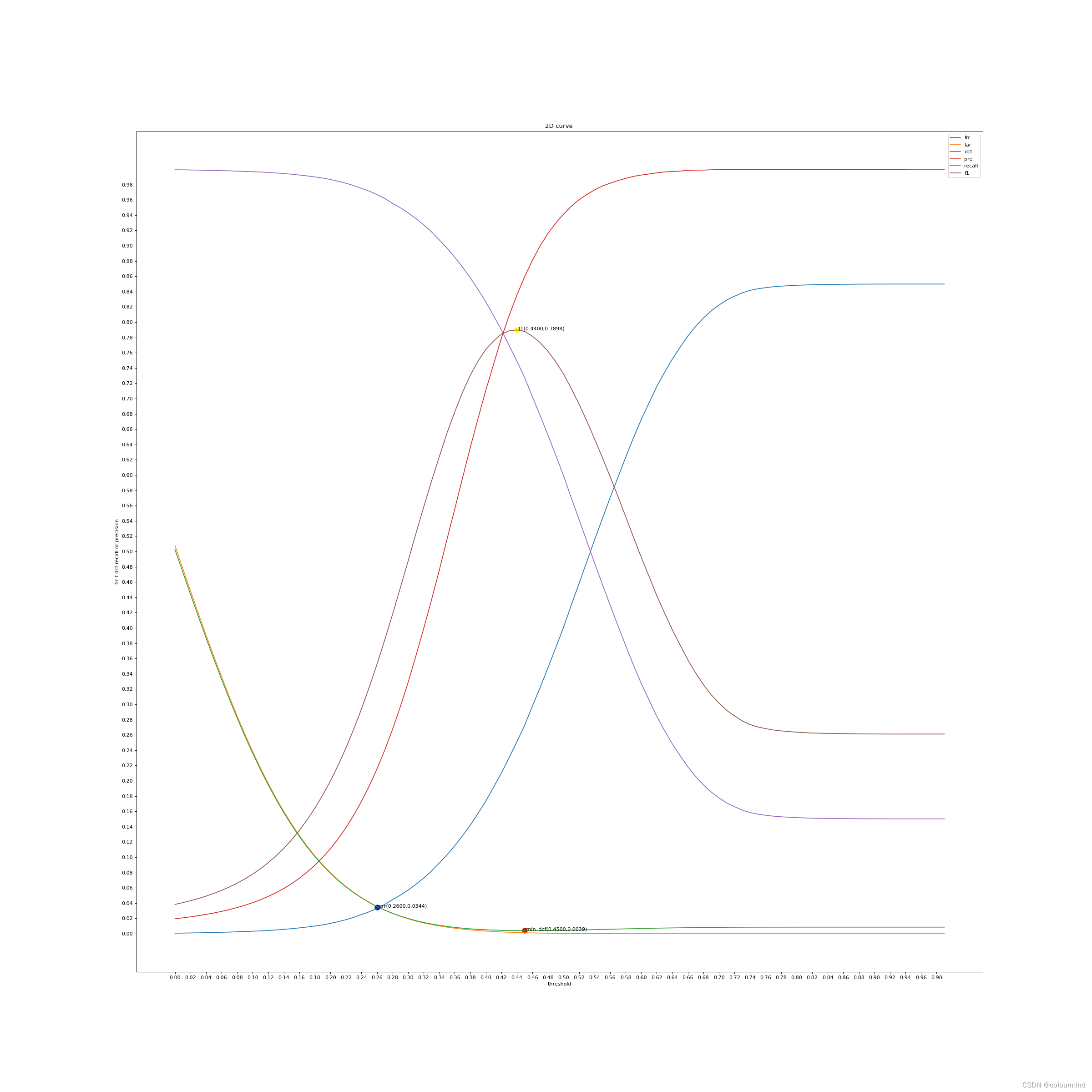
可以看到最小dcf对应的相似度阈值是0.4500。
2、WavLm预训练方案
a、模型结构和loss
from transformers import WavLMModel, WavLMPreTrainedModel
from transformers.modeling_outputs import XVectorOutput
from transformers.pytorch_utils import torch_int_div
import torch.nn as nn
import torch
from typing import Optional, Tuple, Union_HIDDEN_STATES_START_POSITION = 2class TDNNLayer(nn.Module):def __init__(self, config, layer_id=0):super().__init__()self.in_conv_dim = config.tdnn_dim[layer_id - 1] if layer_id > 0 else config.tdnn_dim[layer_id]self.out_conv_dim = config.tdnn_dim[layer_id]self.kernel_size = config.tdnn_kernel[layer_id]self.dilation = config.tdnn_dilation[layer_id]self.kernel = nn.Linear(self.in_conv_dim * self.kernel_size, self.out_conv_dim)self.activation = nn.ReLU()def forward(self, hidden_states):hidden_states = hidden_states.unsqueeze(1)hidden_states = nn.functional.unfold(hidden_states,(self.kernel_size, self.in_conv_dim),stride=(1, self.in_conv_dim),dilation=(self.dilation, 1),)hidden_states = hidden_states.transpose(1, 2)hidden_states = self.kernel(hidden_states)hidden_states = self.activation(hidden_states)return hidden_statesclass AMSoftmaxLoss(nn.Module):def __init__(self, input_dim, num_labels, scale=30.0, margin=0.4):super(AMSoftmaxLoss, self).__init__()self.scale = scaleself.margin = marginself.num_labels = num_labelsself.weight = nn.Parameter(torch.randn(input_dim, num_labels), requires_grad=True)self.loss = nn.CrossEntropyLoss()def forward(self, hidden_states, labels = None):weight = nn.functional.normalize(self.weight, dim=0)hidden_states = nn.functional.normalize(hidden_states, dim=1)cos_theta = torch.mm(hidden_states, weight)if labels is not None:psi = cos_theta - self.marginlabels = labels.flatten()onehot = nn.functional.one_hot(labels, self.num_labels)logits = self.scale * torch.where(onehot.bool(), psi, cos_theta)loss = self.loss(logits, labels)return loss,cos_thetaelse:return cos_thetaclass WavLm(WavLMPreTrainedModel):def __init__(self,config):super(WavLm, self).__init__(config)self.wavlm = WavLMModel(config)num_layers = config.num_hidden_layers + 1 # transformer layers + input embeddingsif config.use_weighted_layer_sum:self.layer_weights = nn.Parameter(torch.ones(num_layers) / num_layers)self.projector = nn.Linear(config.hidden_size, config.tdnn_dim[0])tdnn_layers = [TDNNLayer(config, i) for i in range(len(config.tdnn_dim))]self.tdnn = nn.ModuleList(tdnn_layers)self.feature_extractor = nn.Linear(config.tdnn_dim[-1] * 2, config.xvector_output_dim)self.classifier = nn.Linear(config.xvector_output_dim, config.xvector_output_dim)self.objective = AMSoftmaxLoss(config.xvector_output_dim, config.num_labels)self.init_weights()def forward(self,input_values: Optional[torch.Tensor],attention_mask: Optional[torch.Tensor] = None,output_attentions: Optional[bool] = None,output_hidden_states: Optional[bool] = None,return_dict: Optional[bool] = None,labels: Optional[torch.Tensor] = None,):return_dict = return_dict if return_dict is not None else self.config.use_return_dictoutput_hidden_states = True if self.config.use_weighted_layer_sum else output_hidden_statesoutputs = self.wavlm(input_values,attention_mask=attention_mask,output_attentions=output_attentions,output_hidden_states=output_hidden_states,return_dict=return_dict,)if self.config.use_weighted_layer_sum:hidden_states = outputs[_HIDDEN_STATES_START_POSITION]hidden_states = torch.stack(hidden_states, dim=1)norm_weights = nn.functional.softmax(self.layer_weights, dim=-1)hidden_states = (hidden_states * norm_weights.view(-1, 1, 1)).sum(dim=1)else:hidden_states = outputs[0]hidden_states = self.projector(hidden_states)for tdnn_layer in self.tdnn:hidden_states = tdnn_layer(hidden_states)# Statistic Poolingif attention_mask is None:mean_features = hidden_states.mean(dim=1)std_features = hidden_states.std(dim=1)else:feat_extract_output_lengths = self._get_feat_extract_output_lengths(attention_mask.sum(dim=1))tdnn_output_lengths = self._get_tdnn_output_lengths(feat_extract_output_lengths)mean_features = []std_features = []for i, length in enumerate(tdnn_output_lengths):mean_features.append(hidden_states[i, :length].mean(dim=0))std_features.append(hidden_states[i, :length].std(dim=0))mean_features = torch.stack(mean_features)std_features = torch.stack(std_features)statistic_pooling = torch.cat([mean_features, std_features], dim=-1)output_embeddings = self.feature_extractor(statistic_pooling)logits = self.classifier(output_embeddings)loss = Noneif labels is not None:loss, cos_theta = self.objective(logits, labels)else:cos_theta = self.objective(logits, labels)logits = cos_thetaif not return_dict:output = (logits, output_embeddings) + outputs[_HIDDEN_STATES_START_POSITION:]return ((loss,) + output) if loss is not None else outputreturn XVectorOutput(loss=loss,logits=logits,embeddings=output_embeddings,hidden_states=outputs.hidden_states,attentions=outputs.attentions,)def _get_tdnn_output_lengths(self, input_lengths: Union[torch.LongTensor, int]):"""Computes the output length of the TDNN layers"""def _conv_out_length(input_length, kernel_size, stride):# 1D convolutional layer output length formula taken# from https://pytorch.org/docs/stable/generated/torch.nn.Conv1d.htmlreturn (input_length - kernel_size) // stride + 1for kernel_size in self.config.tdnn_kernel:input_lengths = _conv_out_length(input_lengths, kernel_size, 1)return input_lengthsdef _get_feat_extract_output_lengths(self, input_lengths: Union[torch.LongTensor, int], add_adapter: Optional[bool] = None):"""Computes the output length of the convolutional layers"""add_adapter = self.config.add_adapter if add_adapter is None else add_adapterdef _conv_out_length(input_length, kernel_size, stride):# 1D convolutional layer output length formula taken# from https://pytorch.org/docs/stable/generated/torch.nn.Conv1d.htmlreturn torch_int_div(input_length - kernel_size, stride) + 1for kernel_size, stride in zip(self.config.conv_kernel, self.config.conv_stride):input_lengths = _conv_out_length(input_lengths, kernel_size, stride)if add_adapter:for _ in range(self.config.num_adapter_layers):input_lengths = _conv_out_length(input_lengths, 1, self.config.adapter_stride)return input_lengthsb、数据处理
import random
import torch
from torch.utils.data import Dataset
import torchaudio
from tqdm import tqdmclass AudioDataReader(Dataset):def __init__(self, data_list_path,mode='train',sr=16000,chunk_duration=3,min_duration=0.5,label2ids = {},augmentors=None):super(AudioDataReader, self).__init__()assert data_list_path is not Nonewith open(data_list_path,'r',encoding='utf-8') as f:self.lines = f.readlines()[0:]self.mode = modeself.sr = srself.chunk_duration = chunk_durationself.min_duration = min_durationself.augmentors = augmentorsself.label2ids = label2idsself.audiofeatures = self.getaudiofeatures()def handle_features(self,wav,sr,mode,chunk_duration,min_duration):num_wav_samples = wav.shape[1]# 数据太短不利于训练if mode == 'train':if num_wav_samples < int(min_duration * sr):raise Exception(f'音频长度小于{min_duration}s,实际长度为:{(num_wav_samples / sr):.2f}s')# print(f'音频长度小于{min_duration}s,实际长度为:{(num_wav_samples / sr):.2f}s')# return None# 对小于训练长度的复制补充num_chunk_samples = int(chunk_duration * sr)if num_wav_samples < num_chunk_samples:times = int(num_chunk_samples / num_wav_samples) - 1shortages = []temp_num_wav_samples = num_wav_samplesshortages.append(wav)if times >= 1:for _ in range(times):shortages.append(wav)temp_num_wav_samples += num_wav_samplesshortages.append(wav[:, 0:(num_chunk_samples - temp_num_wav_samples)])else:shortages.append(wav[:, 0:(num_chunk_samples - num_wav_samples)])wav = torch.cat(shortages, dim=1)# 裁剪需要的数据if mode == 'train':# 随机裁剪num_wav_samples = wav.shape[1]num_chunk_samples = int(chunk_duration * sr)if num_wav_samples > num_chunk_samples + 1:start = random.randint(0, num_wav_samples - num_chunk_samples - 1)end = start + num_chunk_sampleswav = wav[:, start:end]# # 对每次都满长度的再次裁剪# if random.random() > 0.5:# wav[:random.randint(1, sr // 4)] = 0 #加入了静音数据# wav = wav[:-random.randint(1, sr // 4)]elif mode == 'eval':# 为避免显存溢出,只裁剪指定长度num_wav_samples = wav.shape[1]num_chunk_samples = int(chunk_duration * sr)if num_wav_samples > num_chunk_samples + 1:wav = wav[:, 0:num_chunk_samples]return wavdef getaudiofeatures(self):res = []for line in tqdm(self.lines,desc= self.mode + ' load all audios',ncols=100):temp = []try:audio_path, label = line.replace('\n', '').split('\t')label = self.label2ids[label]wav, sample_rate = torchaudio.load(audio_path) # 加载音频返回的是张量wav = self.handle_features(wav,sr=self.sr,mode=self.mode,chunk_duration=self.chunk_duration,min_duration=self.min_duration)features = wav[:,0:self.sr*self.chunk_duration].squeeze(0)attention_mask = torch.ones_like(features,dtype=torch.long)label = torch.as_tensor(label, dtype=torch.long)temp.append(features)temp.append(attention_mask)temp.append(label)res.append(temp)except Exception as e:print(e+',load audio data exception')return resdef __getitem__(self, item):return self.audiofeatures[item][0], self.audiofeatures[item][1], self.audiofeatures[item][2]def __len__(self):return len(self.audiofeatures)和Ecapa_TDNN的不同就是直接采用时域数据而不是采用语音特征分析后的频域信息,代码就是训练和验证样本的长度进行了控制,比较简单。
c、模型训练
from transformers import Wav2Vec2Config
from models.wavlm import WavLm
from tools.log import Logger
from tools.progressbar import ProgressBar
from data_utils.wavlm_reader import AudioDataReaderfrom torch.utils.data import DataLoader
import torch
import os
from torch.optim import AdamW
from torch.optim.lr_scheduler import CosineAnnealingLR
import argparseimport random
import numpy as np
from torch.utils.tensorboard import SummaryWriter
from datetime import datetime
from torch.nn.utils.rnn import pad_sequencedef parse_args():parser = argparse.ArgumentParser()parser.add_argument("--train_datas_path", type=str, default='./data/train_audio_paths.txt', help="train text file")parser.add_argument("--val_datas_path", type=str, default='./data/val_audio_paths.txt', help="val text file")# parser.add_argument("--train_datas_path", type=str, default='./data/train_audio_paths_small.txt', help="train text file")# parser.add_argument("--val_datas_path", type=str, default='./data/val_audio_paths_small.txt', help="val text file")parser.add_argument("--log_file", type=str, default="./log_output/speaker_identification_wavlm.log", help="log_file")parser.add_argument("--model_out", type=str, default="./output/wavlm/", help="model output path")parser.add_argument("--batch_size", type=int, default=32, help="batch size")parser.add_argument("--epochs", type=int, default=30, help="epochs")parser.add_argument("--lr", type=float, default=1e-5, help="epochs")parser.add_argument("--random_seed", type=int, default=100, help="random_seed")parser.add_argument("--device", type=str, default='0', help="device")args = parser.parse_args()return argsdef training(args):os.environ['CUDA_VISIBLE_DEVICES'] = args.devicelogger = Logger(log_name='SI',log_level=10,log_file=args.log_file).loggerlogger.info(args)label2ids = {}config = Wav2Vec2Config.from_pretrained('./pretrained_models/torch/wavlm-base-plus-sv/')id = 0with open(args.train_datas_path,'r',encoding='utf-8') as f:lines = f.readlines()for line in lines:line = line.strip('\n')if line.split('\t')[-1] not in label2ids:label2ids[line.split('\t')[-1]] = idid += 1with open(args.val_datas_path,'r',encoding='utf-8') as f:lines = f.readlines()for line in lines:line = line.strip('\n')if line.split('\t')[-1] not in label2ids:label2ids[line.split('\t')[-1]] = idid += 1time_srt = datetime.now().strftime('%Y-%m-%d')save_path = os.path.join(args.model_out,time_srt)if not os.path.exists(save_path):os.makedirs(save_path)logger.info(save_path)device = "cuda:0" if torch.cuda.is_available() else "cpu"train_dataset = AudioDataReader(data_list_path=args.train_datas_path,mode='train', label2ids=label2ids)train_dataloader = DataLoader(train_dataset,shuffle=True,batch_size=args.batch_size, collate_fn=collate_fn)val_dataset = AudioDataReader(data_list_path=args.val_datas_path, mode='eval', label2ids = label2ids)val_dataloader = DataLoader(val_dataset, shuffle=True, batch_size=args.batch_size, collate_fn=collate_fn)num_class = len(label2ids)logger.info('num_class:%d'%num_class)config.num_labels = num_classmodel = WavLm.from_pretrained('./pretrained_models/torch/wavlm-base-plus-sv/', config=config, ignore_mismatched_sizes=True).to(device)model.eval()# ecapa_tdnn = EcapaTdnn(input_size=train_dataset.input_size)# model = SpeakerIdetification(backbone=ecapa_tdnn, num_class=num_class).to(device)# logger.info(model)optimizer = AdamW(lr=args.lr,params=model.parameters())scheduler = CosineAnnealingLR(optimizer,T_max=args.epochs)logger.info("***** Running training *****")logger.info(" Num examples = %d" % len(train_dataloader))logger.info(" Num Epochs = %d" % args.epochs)writer = SummaryWriter('./runs/' + time_srt + '/')best_acc = 0total_step = 0unimproving_count = 0for epoch in range(args.epochs):pbar = ProgressBar(n_total=len(train_dataloader), desc='Training')model.train()total_loss = 0for step, batch in enumerate(train_dataloader):batch = [t.to(device) for t in batch]wav = batch[0]mask = batch[1]speakers = batch[2]inputs = {"input_values": wav,"attention_mask": mask}output = model(**inputs,labels=speakers)loss = output.lossoptimizer.zero_grad()# loss.backward(retain_graph=True)loss.backward()optimizer.step()total_step += 1writer.add_scalar('Train/Learning loss', loss.item(), total_step)total_loss += loss.item()pbar(step, {'loss': loss.item()})val_acc = evaluate(model, val_dataloader, device)if best_acc < val_acc:best_acc = val_accmodel.save_pretrained(save_path)is_improving = Trueunimproving_count = 0else:is_improving = Falseunimproving_count += 1if is_improving:logger.info(f"Train epoch [{epoch+1}/{args.epochs}],batch [{step+1}],Best_acc: {best_acc},Val_acc:{val_acc}, lr:{scheduler.get_last_lr()[0]}, total_loss:{round(total_loss,4)}. Save model!")else:logger.info(f"Train epoch [{epoch+1}/{args.epochs}],batch [{step+1}],Best_acc: {best_acc},Val_acc:{val_acc}, lr:{scheduler.get_last_lr()[0]}, total_loss:{round(total_loss,4)}.")writer.add_scalar('Val/val_acc', val_acc, total_step)writer.add_scalar('Val/best_acc', best_acc, total_step)# writer.add_scalar('Train/Learning rate', scheduler.get_lr()[0], total_step)writer.add_scalar('Train/Learning rate', scheduler.get_last_lr()[0], total_step)scheduler.step()if unimproving_count >= 5:logger.info('unimproving %d epochs, early stop!'%unimproving_count)breakdef evaluate(model,val_dataloader,device):total = 0correct_total = 0model.eval()with torch.no_grad():pbar = ProgressBar(n_total=len(val_dataloader), desc='evaluate')for step, batch in enumerate(val_dataloader):batch = [t.to(device) for t in batch]wav = batch[0]mask = batch[1]speakers = batch[2]inputs = {"input_values": wav,"attention_mask": mask}output = model(**inputs)logits = output.logitstotal += speakers.shape[0]preds = torch.argmax(logits,dim=-1)correct = (speakers==preds).sum().item()pbar(step, {})correct_total += correctacc = correct_total/totalreturn accdef set_seed(seed):torch.manual_seed(seed)torch.cuda.manual_seed(seed)np.random.seed(seed)random.seed(seed)torch.backends.cudnn.deterministic = Truedef collate_fn(batch):features, attention_mask, labels = zip(*batch)features = pad_sequence(features, batch_first=True, padding_value=0.0)attention_mask = pad_sequence(attention_mask, batch_first=True, padding_value=0)labels = torch.stack(labels, dim=-1)return features, attention_mask, labelsif __name__ == '__main__':args = parse_args()set_seed(args.random_seed)training(args)结果如下:
分类准确率:0.9684
d、推理和评估
同样采用far frr err dcf 以及f1 recall和precision等指标来评估
from transformers import WavLMForXVector
from tools.log import Logger
from tools.progressbar import ProgressBar
from data_utils.wavlm_reader import AudioDataReader
from torch.utils.data import DataLoader
import torch
import os
import argparse
import random
import numpy as np
from tqdm import tqdm
import matplotlib.pyplot as plt
from torch.nn.utils.rnn import pad_sequence
import timedef parse_args():parser = argparse.ArgumentParser()parser.add_argument("--train_datas_path", type=str, default='./data/train_audio_paths.txt', help="train text file")parser.add_argument("--val_datas_path", type=str, default='./data/val_audio_paths.txt', help="val text file")# parser.add_argument("--train_datas_path", type=str, default='./data/train_audio_paths_small.txt', help="train text file")# parser.add_argument("--val_datas_path", type=str, default='./data/val_audio_paths_small.txt', help="val text file")parser.add_argument("--log_file", type=str, default="./log_output/speaker_identification_evaluate.log", help="log_file")parser.add_argument("--batch_size", type=int, default=64, help="batch size")parser.add_argument("--random_seed", type=int, default=100, help="random_seed")parser.add_argument("--device", type=str, default='0', help="device")args = parser.parse_args()return argsdef evaluate(args):os.environ['CUDA_VISIBLE_DEVICES'] = args.devicelogger = Logger(log_name='SI',log_level=10,log_file=args.log_file).loggerlogger.info(args)label2ids = {}id = 0with open(args.train_datas_path,'r',encoding='utf-8') as f:lines = f.readlines()for line in lines:line = line.strip('\n')if line.split('\t')[-1] not in label2ids:label2ids[line.split('\t')[-1]] = idid += 1with open(args.val_datas_path,'r',encoding='utf-8') as f:lines = f.readlines()for line in lines:line = line.strip('\n')if line.split('\t')[-1] not in label2ids:label2ids[line.split('\t')[-1]] = idid += 1device = "cuda:0" if torch.cuda.is_available() else "cpu"val_dataset = AudioDataReader( data_list_path=args.val_datas_path, mode='eval', label2ids = label2ids)val_dataloader = DataLoader(val_dataset, shuffle=True, batch_size=args.batch_size,collate_fn=collate_fn)num_class = 875logger.info('num_class:%d'%num_class)model = WavLMForXVector.from_pretrained('./output/wavlm/2022-11-11/').to(device)model.eval()logger.info("***** Running evaluate *****")logger.info(" Num examples = %d" % len(val_dataset))pbar = ProgressBar(n_total=len(val_dataloader), desc='extract features')model.eval()labels = []features = []with torch.no_grad():for step, batch in enumerate(val_dataloader):batch = [t.to(device) for t in batch]wav = batch[0]mask = batch[1]speakers = batch[2]inputs = {"input_values": wav,"attention_mask": mask}output = model(**inputs)labels.append(speakers)features.append(output.embeddings)pbar(step,info={'step':step})labels = torch.cat(labels)features = torch.cat(features)scores_pos = []scores_neg = []y_true_pos = []y_true_neg = []for i in tqdm(range(features.shape[0]), desc='两两计算相似度', ncols=100):query = features[i]inside = features[i:, :]temp = (labels[i] == labels[i:]).detach().long()pos_index = torch.nonzero(temp == 1)neg_index = torch.nonzero(temp == 0)pos_label = torch.take(temp, pos_index).squeeze(1).detach().cpu().tolist()neg_label = torch.take(temp, neg_index).squeeze(1).detach().cpu().tolist()cos = torch.cosine_similarity(query, inside, dim=-1)pos_score = torch.take(cos, pos_index).squeeze(1).detach().cpu().tolist()neg_score = torch.take(cos, neg_index).squeeze(1).detach().cpu().tolist()y_true_pos.extend(pos_label)y_true_neg.extend(neg_label)scores_pos.extend(pos_score)scores_neg.extend(neg_score)print('len(y_true_neg)', len(y_true_neg))print('len(y_true_pos)', len(y_true_pos))print('len(scores_pos)', len(scores_pos))print('len(scores_neg)', len(scores_neg))if len(y_true_pos) * 99 < len(y_true_neg):indexs = random.choices(list(range(len(y_true_neg))), k=len(y_true_pos) * 99)scores = scores_posy_true = y_true_posfor index in indexs:scores.append(scores_neg[index])y_true.append(y_true_neg[index])else:scores = scores_pos + scores_negy_true = y_true_pos + y_true_negprint('len(scores)', len(scores))print('len(y_true)', len(y_true))scores = torch.tensor(scores,dtype=torch.float32)y_true = torch.tensor(y_true,dtype=torch.long)choice_best_threshold_dcf(scores, y_true)def choice_best_threshold_dcf(scores, y_true):thresholds = []fars = []frrs = []dcfs = []precisions = []recalls = []f1s = []max_precision = 0max_recall = 0max_f1 = 0f1_threshold = 0min_dcf = 1d_threshold = 0cfr = 1cfa =1err = 0.0err_threshold = 0diff = 1for i in tqdm(range(100), desc='choice_best_threshold', ncols=100):threshold = 0.01 * ithresholds.append(threshold)y_preds = (scores > threshold).long()tp = ((y_true == 1) * (y_preds == 1)).sum().item()fp = ((y_true == 0) * (y_preds == 1)).sum().item()tn = ((y_true == 0) * (y_preds == 0)).sum().item()fn = ((y_true == 1) * (y_preds == 0)).sum().item()pos = tp + fnneg = tn + fpprecision = tp / (tp + fp+1e-13)recall = tp / (tp + fn+1e-13)f1 = 2 * precision * recall / (precision + recall + 1e-13)far = fp / (fp + tn + 1e-13)frr = fn / (tp + fn + 1e-13)dcf = cfa* far *(neg/(neg+pos)) + cfr* frr *(pos/(pos+neg))precisions.append(precision)recalls.append(recall)f1s.append(f1)fars.append(far)frrs.append(frr)dcfs.append(dcf)if max_precision < precision:max_precision = precisionif max_recall < recall:max_recall = recallif max_f1 < f1:max_f1 = f1f1_threshold = thresholdif min_dcf > dcf:min_dcf = dcfd_threshold = thresholdif abs(far-frr) < diff:err = (far+frr)/2diff = abs(far-frr)err_threshold = thresholdprint(pos + neg)print('threshold:%.4f err:%.4f'%(err_threshold, err))print("d_threshold:%.4f, min_dcf%.4f"%(d_threshold, min_dcf))print("f1_threshold:%.4f, max_f1%.4f" % (f1_threshold, max_f1))start = time.time()plt.figure(figsize=(30,30),dpi=80)plt.title('2D curve ')plt.plot(thresholds, frrs, label='frr')plt.plot(thresholds, fars, label='far')plt.plot(thresholds, dcfs, label='dcf')plt.plot(thresholds, precisions, label='pre')plt.plot(thresholds, recalls, label='recall')plt.plot(thresholds, f1s, label='f1')plt.legend(loc=0)plt.scatter(d_threshold, min_dcf, c='red', s=100)plt.text(d_threshold, min_dcf, " min_dcf(%.4f,%.4f)"%(d_threshold, min_dcf))plt.scatter(err_threshold,err,c='blue',s=100)plt.text(err_threshold,err," err(%.4f,%.4f)"%(err_threshold,err))plt.scatter(f1_threshold, max_f1, c='yellow', s=100)plt.text(f1_threshold, max_f1, " f1(%.4f,%.4f)"%(f1_threshold, max_f1))plt.xlabel('threshold')plt.ylabel('frr f dcf recall or precision')plt.xticks(thresholds[::2])plt.yticks(thresholds[::2])end = time.time()print('plot time is', end - start)plt.savefig('wavlm_2d_curve_voiceprint_dcf.png')plt.show()print("finish")def set_seed(seed):torch.manual_seed(seed)torch.cuda.manual_seed(seed)np.random.seed(seed)random.seed(seed)torch.backends.cudnn.deterministic = Truedef collate_fn(batch):features,attention_mask,labels = zip(*batch)features = pad_sequence(features,batch_first=True,padding_value=0.0)attention_mask = pad_sequence(attention_mask, batch_first=True, padding_value=0)labels = torch.stack(labels,dim=-1)return features, attention_mask, labelsif __name__ == '__main__':args = parse_args()set_seed(args.random_seed)evaluate(args)结果如下
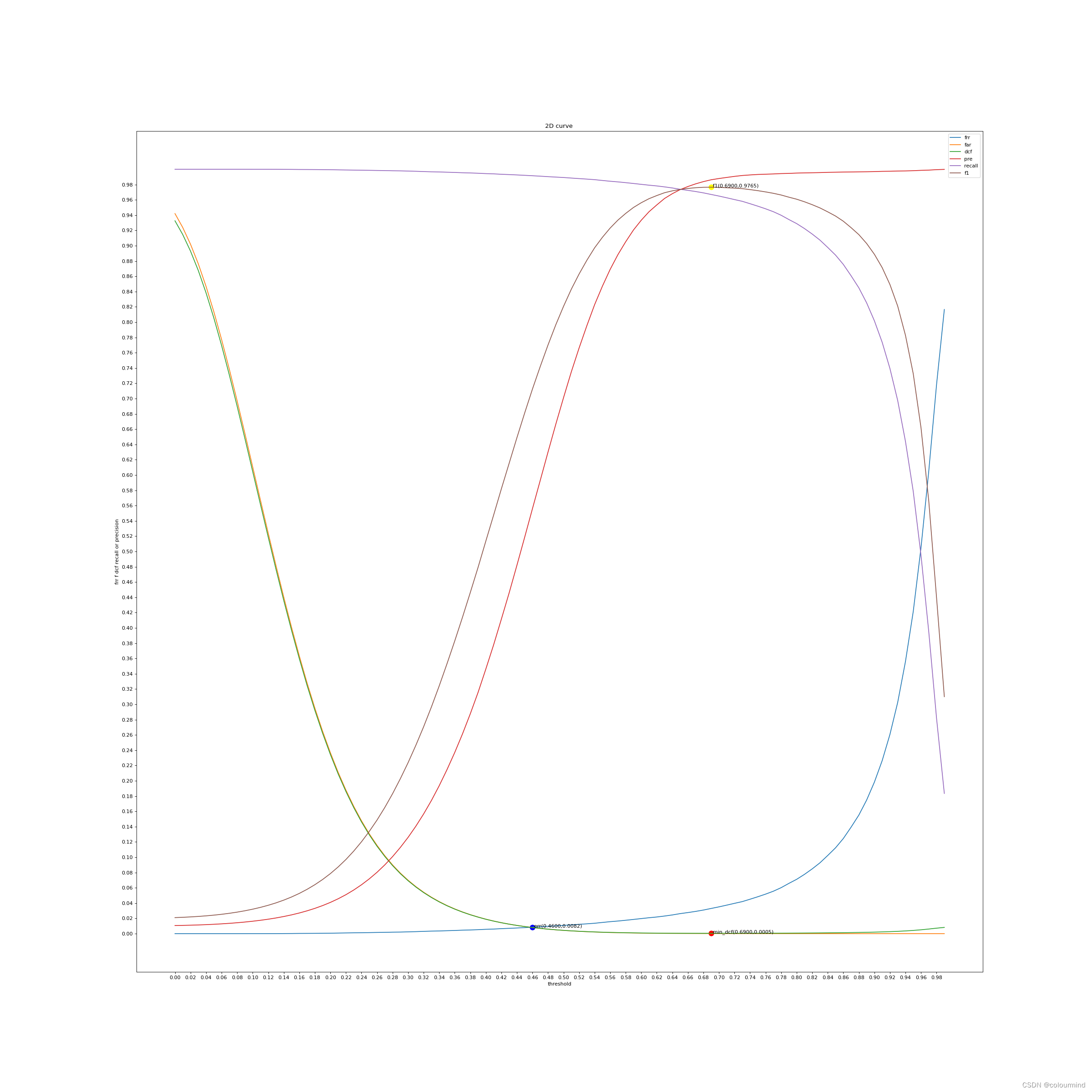
threshold=0.69 dcf 和f1值都处于最佳状态 而且f1=0.9765 err和dcf值都非常低,明显wavLm模型在该数据集上的效果要优于Ecapa_TDNN。
四、demo演示
花了接近两周下班后的时间以及周末可以去学习了一下vue2.0和vue3.0,看的是b站尚硅谷的视频,做了一个speaker verification的前端demo(vue3.0)。先看看整体页面效果:
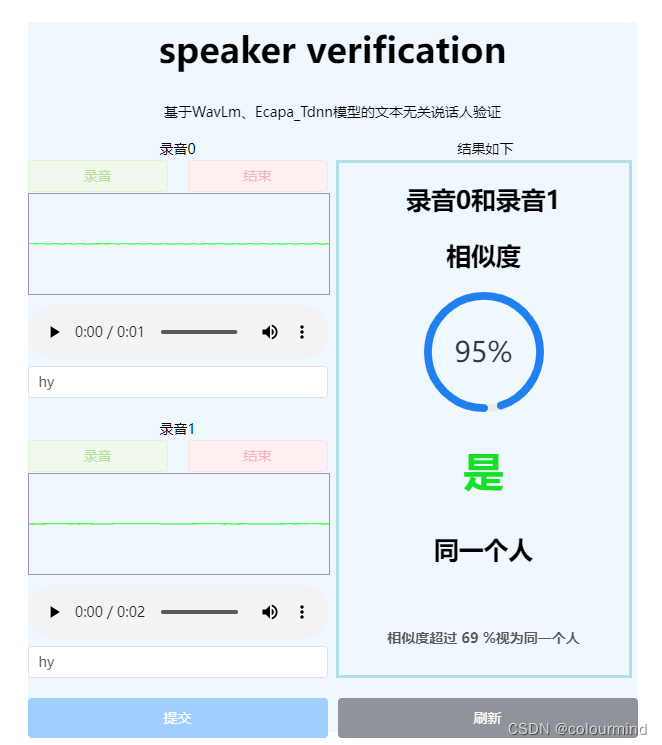
大体上说说demo的实现方案:
1、后端直接使用python+flask非常简单。
2、前端采用vue3.0+html+css做一些简单的页面也非常容易(不过完全不懂前端的话学习起来还是需要一点时间的)。
3、算法端python+torch,模型使用了WavLm和Ecapa_TdNN模型。
五、总结
关于这个声纹识别,本文章只是简单的做了一个尝试和验证一下主流的模型方案的效果。并没有考虑实际业务场景,比方说音频的背景是否有噪声、跨设备、跨距离、录音代替真人实时说话问题、以及如何优化、上线需要注意那些问题都没有讨论。这里面还有很多值得学习的地方,本人水平有限,后续再来学习。
关于预训练模型WavLM和CNN组网模型,个人认为WavLm应该是更加主流,个人更看好WavLm,如果有相应的音频数据,继续预训练+微调应该能解决一些特定领域的问题,前提是要有大规模的数据。
参考文章:
Speaker Verification——学习笔记
说话人确认系统性能评价指标EER和minDCF
ECAPA-TDNN: Emphasized Channel Attention, Propagation and Aggregation in TDNN Based Speaker Verification
通用模型、全新框架,WavLM语音预训练模型全解
WavLM: Large-Scale Self-Supervised Pre-Training for Full Stack Speech Processing