
EMS运行数据处理-pandas降采样、合并多表
创始人
2024-05-10 21:47:03
0次
文章目录
- read_csv读取出错。因为多余异常列数据
- 解决方法
- pd.to_datetime(df['time_key'])但time_key出现不能转换的序列
- 解决方法
- pandas 提取时间序列年、月、日
- 方法一:pandas.Series.dt.month() 方法提取月份
- 方法二:strftime() 方法提取年、月、日
- 方法三:pandas.DatetimeIndex.month提取月份
- pd.concat()多表合并
- 示例
- df.groupby()分组
read_csv读取出错。因为多余异常列数据
在读取数据集的时候出现报错。检查才发现是出现是

ParserError: Error tokenizing data. C error: Expected 16 fields in
line 14996, saw 29
解决方法
由于我这边数据集够多。选择直接这种数据就舍弃跳过
df = pd.read_csv(filePath, on_bad_lines='warn')
on_bad_lines 指定遇到错误行(字段太多的行)时要执行的操作。允许的值为:
- “error”,遇到错误行时引发异常。
- “warn”,遇到错误行时发出警告并跳过该行。
- “skip”,在遇到错误行时跳过错误行而不引发或警告。
pd.to_datetime(df[‘time_key’])但time_key出现不能转换的序列
dateutil.parser._parser.ParserError: Unknown string format: ‘202’2022-01-03 08:22:09.481’
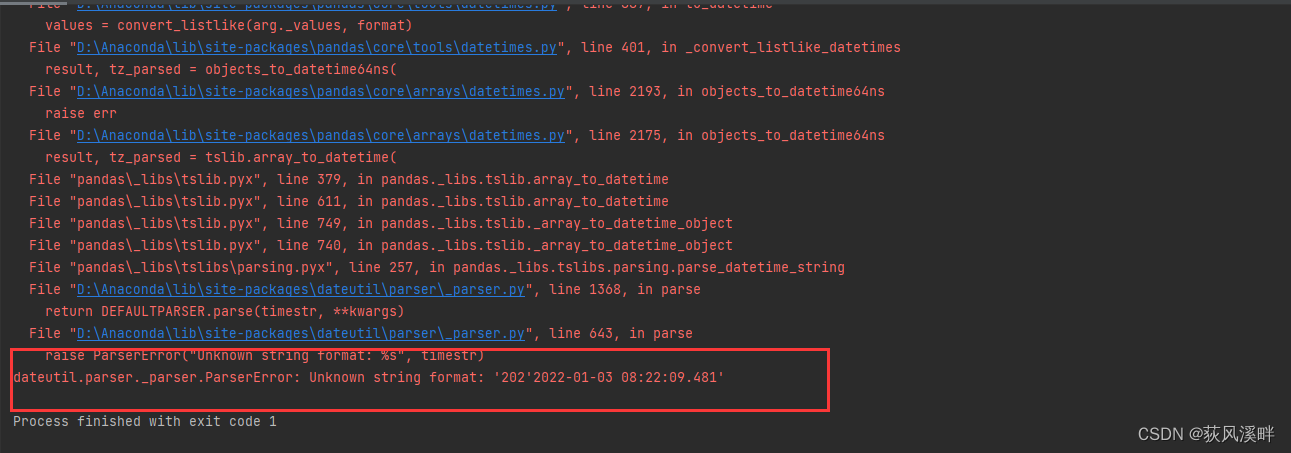
解决方法
把它挑出来剔除
df['time_key'] = pd.to_datetime(df['time_key'],errors='coerce') # 不加format也行,pandas自动推断日期格式,format='%Y-%m-%d %H:%M:%S'
df.dropna(inplace=True) #剔除
errors三种取值,‘ignore’, ‘raise’, ‘coerce’,默认为raise。
raise,则无效的解析将引发异常coerce,那么无效解析将被设置为NaT(not a time ,和NaN一样是空值)ignore,那么无效的解析将返回原值
to_datetime官网解释
pandas 提取时间序列年、月、日
方法一:pandas.Series.dt.month() 方法提取月份
应用于 Datetime 类型的pandas.Series.dt.month() 方法分别返回系列对象中Datetime条目的年和月的numpy数组。
注意:如果该列不是 Datetime 类型,则应首先使用 to_datetime() 方法将该列转换为 Datetime类型,pd.to_datetime()。
- 获取其他时间方法
dt.year、dt.month、dt.day:获取年、月、日;
dt.hour、dt.minute、dt.second、dt.microsecond:获取时、分、秒、微秒;
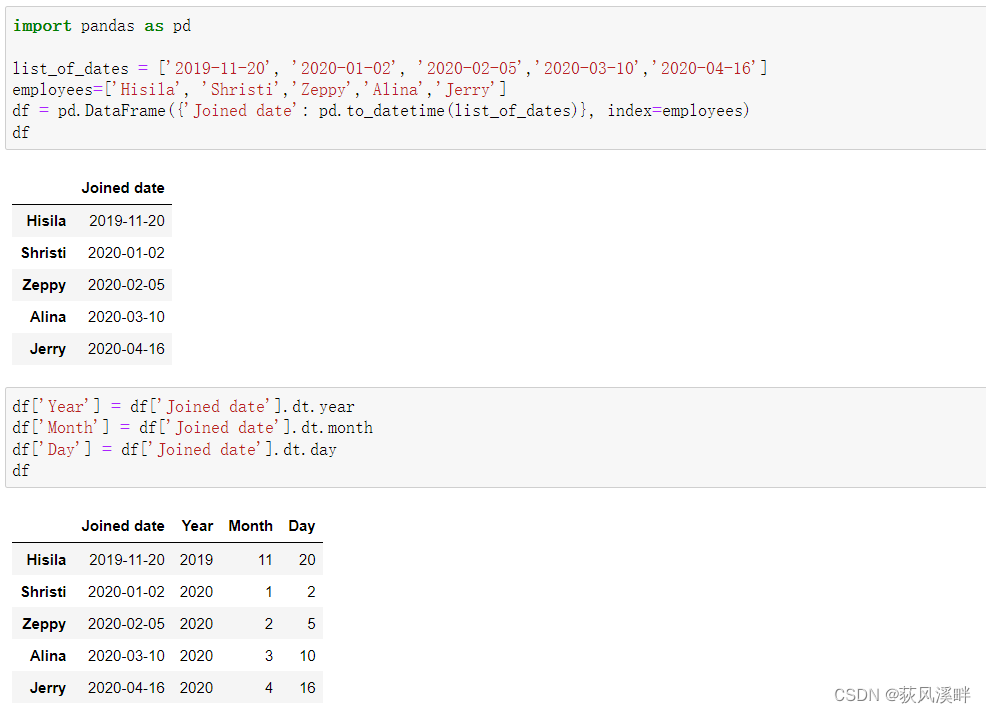
示例
import pandas as pdlist_of_dates = ['2019-11-20', '2020-01-02', '2020-02-05','2020-03-10','2020-04-16']
employees=['Hisila', 'Shristi','Zeppy','Alina','Jerry']
df = pd.DataFrame({'Joined date': pd.to_datetime(list_of_dates)}, index=employees)df['Year'] = df['Joined date'].dt.year
df['Month'] = df['Joined date'].dt.month
print(df)
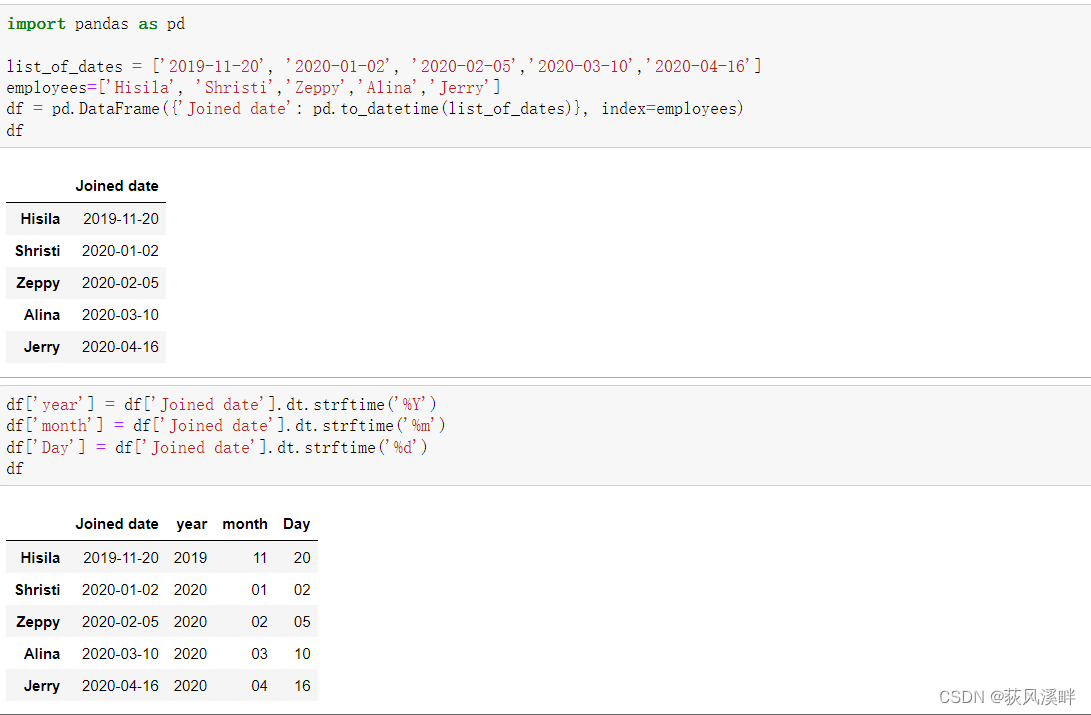
方法二:strftime() 方法提取年、月、日
strftime() 方法使用 Datetime,将格式代码作为输入,并返回表示输出中指定的特定格式的字符串。使用%Y 和%m 作为格式代码来提取年份和月份。
df['year'] = df['Joined date'].dt.strftime('%Y')
df['month'] = df['Joined date'].dt.strftime('%m')
df['Day'] = df['Joined date'].dt.strftime('%d')
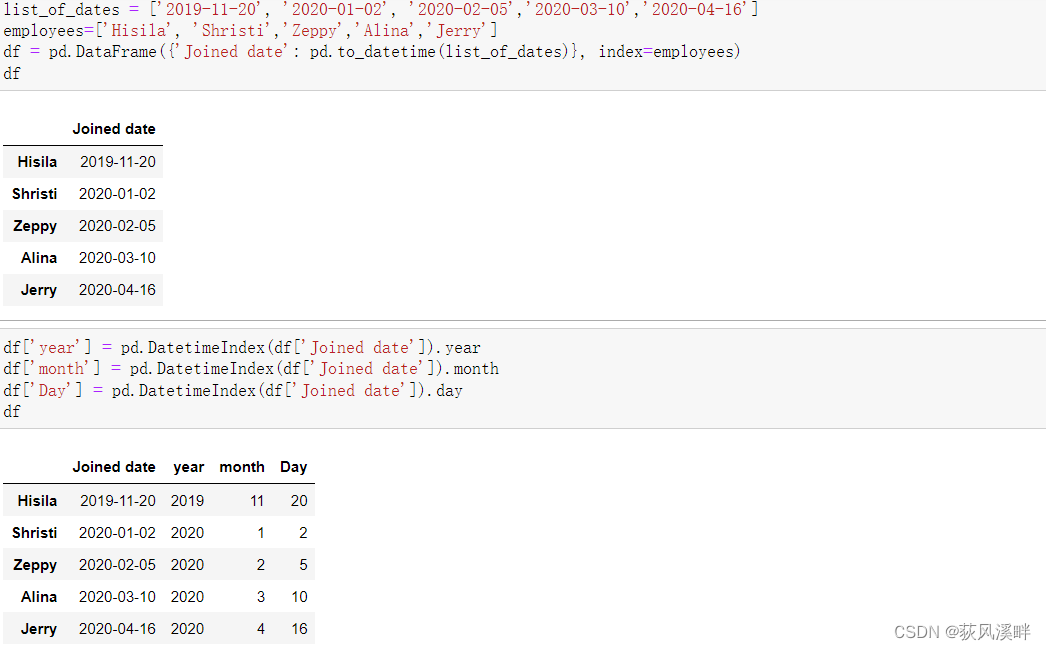
方法三:pandas.DatetimeIndex.month提取月份
通过检索 pandas.DatetimeIndex 对象的月份属性的值类,从 Datetime 列中提取月份。
此时,datatime是DataFrame的索引,时间类型的索引。比非时间索引类型的时间类型列,在抽取年月的时候,少个dt。
df['year'] = pd.DatetimeIndex(df['Joined date']).year
df['month'] = pd.DatetimeIndex(df['Joined date']).month
pd.concat()多表合并
参数:
concat(objs, *, axis=0, join='outer', ignore_index=False,
keys=None, levels=None, names=None, verify_integrity=False, sort=False, copy=True)
参数介绍:
- axis=0代表
index,匹配列名,往下拼接排列;axis=1代表columns,拼接生成新列,索引不变。( 默认axis=0) - objs:需要连接的对象集合,一般是列表或字典;
- join:参数为
outer(默认拼接方式,并集合并)或inner(交集合并); ignore_index=True:重建索引,默认是False
示例
import pandas as pdlist_of_dates = ['2019-11-20', '2020-01-02', '2020-02-05','2020-03-10','2020-04-16']
employees=['Hisila', 'Shristi','Zeppy','Alina','Jerry']
df = pd.DataFrame({'Joined date': pd.to_datetime(list_of_dates)}, index=employees)
pd.concat([df, df]) #根据列名匹配后,往下拼接排列)

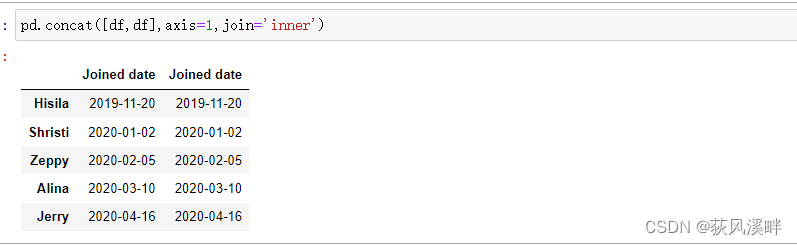
pd.concat([df,df],axis=1,join='inner')
df.groupby()分组
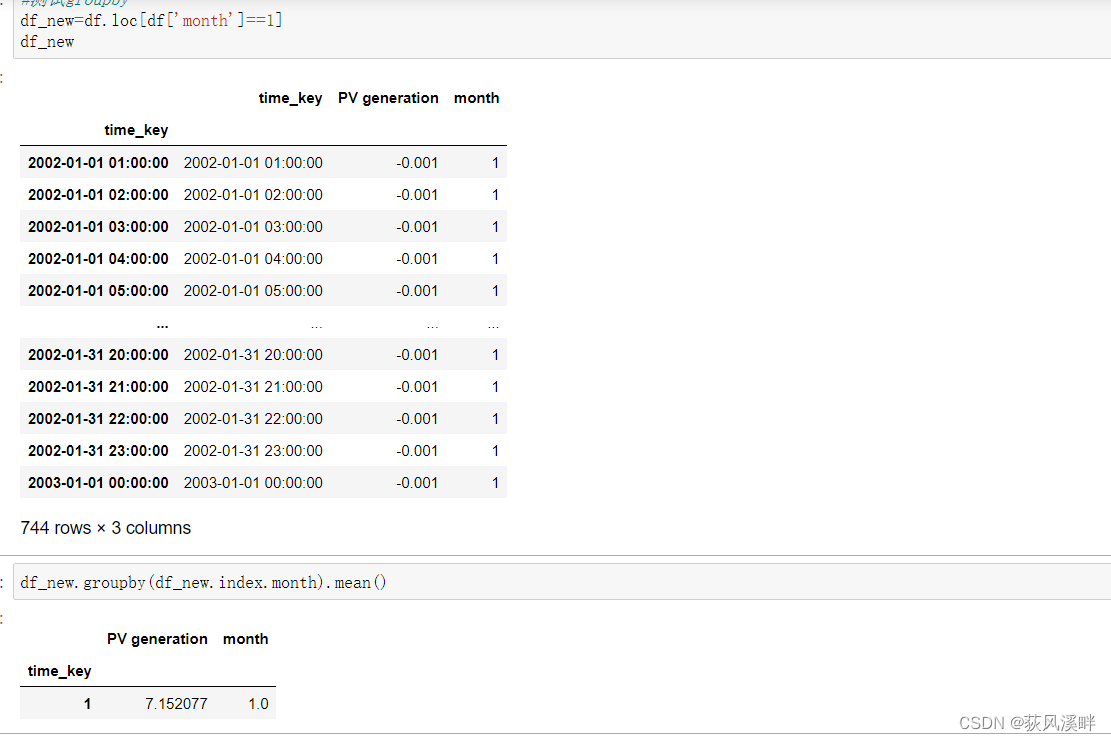
df_new=df.loc[df['month']==1]
df_new.groupby(df_new.index.month).mean() #按时间序列中的月份求各列的均值.hour,day同理
相关内容
热门资讯
findx耍原生安卓系统,深度...
亲爱的读者们,你是否厌倦了那些花里胡哨的定制系统,渴望回到那个纯净的安卓世界?今天,我要带你一起探索...
一加系统属于安卓系统吗,引领智...
你有没有想过,手机里的那个神奇的“一加系统”到底是不是安卓系统的一员呢?这可是个让人好奇不已的问题哦...
小米2刷安卓系统吗,探索安卓系...
亲爱的读者,你是否曾经对小米2这款手机刷安卓系统的事情感到好奇呢?今天,就让我带你一探究竟,揭开小米...
安卓7.0系统线刷包,深度解析...
你有没有发现,你的安卓手机最近有点儿“蔫儿”了?别急,别急,今天就来给你揭秘如何让你的安卓手机重焕生...
白菜系统和安卓拍照,开启智能生...
你知道吗?最近我在用手机拍照的时候,发现了一个超级酷的功能,简直让我爱不释手!那就是——白菜系统和安...
安卓系统查杀病毒,全方位守护您...
手机里的安卓系统是不是有时候会突然弹出一个查杀病毒的提示?别慌,这可不是什么大问题,今天就来给你详细...
iso系统与安卓各系统哪个好,...
你有没有想过,手机操作系统就像是我们生活中的不同交通工具,各有各的特色和优势。今天,咱们就来聊聊这个...
中柏怎么换安卓系统,解锁更多可...
你有没有发现,中柏的安卓系统有时候用起来还挺不顺手的?别急,今天就来手把手教你如何给中柏手机升级安卓...
安卓热点绕过系统验证,揭秘操作...
你是不是也遇到过这种情况?手机里的安卓热点突然不灵光了,系统验证总是跳出来,让人头疼不已。别急,今天...
安卓系统怎么关闭小艺,安卓系统...
亲爱的安卓用户们,你是否也和我一样,对手机里的小艺助手有些爱恨交加呢?有时候,它贴心得让人感动,有时...
安卓系统计划软件推荐,精选计划...
你有没有发现,手机里的安卓系统越来越智能了?这不,最近我可是挖到了一些超棒的安卓计划软件,它们不仅能...
收钱吧安卓系统插件,便捷支付新...
你有没有发现,现在的生活越来越离不开手机了?手机里装满了各种应用,而今天我要跟你聊聊一个特别实用的工...
鸿蒙系统是否还属于安卓,独立于...
你有没有想过,那个在我们手机上默默无闻的鸿蒙系统,它到底是不是安卓的“亲戚”呢?这个问题,估计不少手...
安卓系统手机用什么钱包,轻松管...
你有没有想过,你的安卓系统手机里装了那么多应用,但最离不开的,可能就是那个小小的钱包了。没错,就是那...
安卓系统能玩部落冲突吗,部落冲...
你有没有想过,安卓系统上的手机,是不是也能玩那款风靡全球的《部落冲突》呢?这款游戏自从推出以来,就吸...
智能机器人安卓系统,引领未来智...
你知道吗?在科技飞速发展的今天,智能机器人已经不再是科幻电影里的专属了。它们正悄悄地走进我们的生活,...
华为win10系统改装安卓系统...
你有没有想过,你的华为笔记本电脑里的Windows 10系统,能不能来个华丽变身,变成安卓系统呢?这...
旧电脑上安什么安卓系统,适配不...
你那台旧电脑是不是已经闲置好久了?别让它默默无闻地躺在角落里,给它来个华丽变身吧!今天,就让我来告诉...
安卓app语言跟随系统,随系统...
你知道吗?在手机世界里,有一个神奇的小功能,它就像你的贴身翻译官,无论你走到哪里,都能帮你轻松应对各...
惠城安卓系统降级在哪,揭秘降级...
你有没有遇到过手机系统升级后,发现新系统让你头疼不已,想回到那个熟悉的安卓系统呢?别急,今天就来告诉...