
C++引用
目录
一. 引用的基本概念
二.引用的特性
1.一个变量可以有多个引用,并且引用可以嵌套定义。
2. 引用一旦引用一个实体,再不能引用其他实体
3.常引用(被const 修饰的引用)
三.引用的一些应用场景
1.引用作为函数的形参(引用传参)
2.引用作函数返回值
3.引用作为函数形参或作为函数返回值的好处
附:引用的定义和指针的定义的汇编代码
一. 引用的基本概念
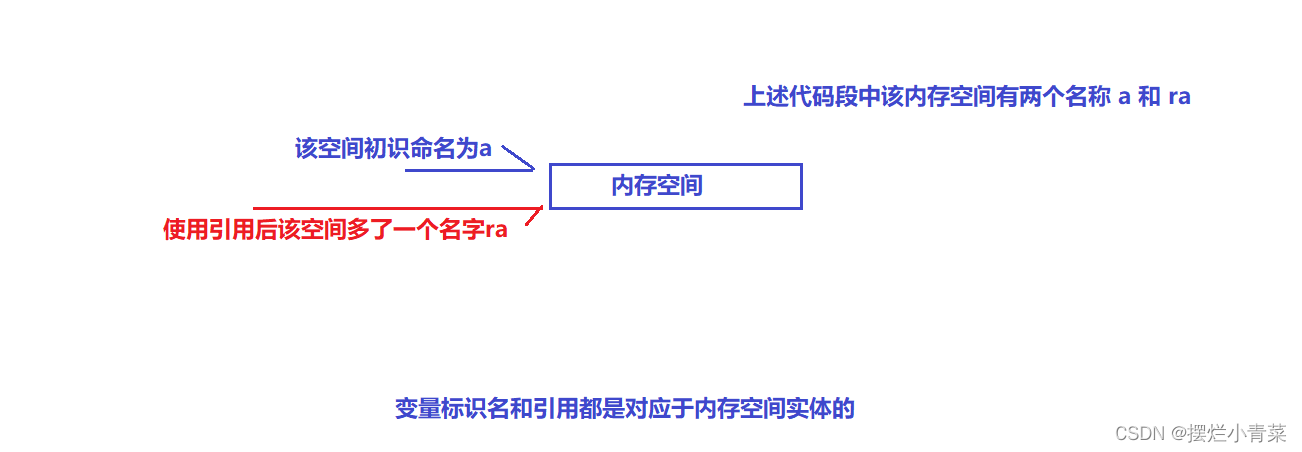
在语法层面上,引用就是给已存在变量取了一个别名,引用并没有新定义一个变量(即语法概念上没有独立的空间)
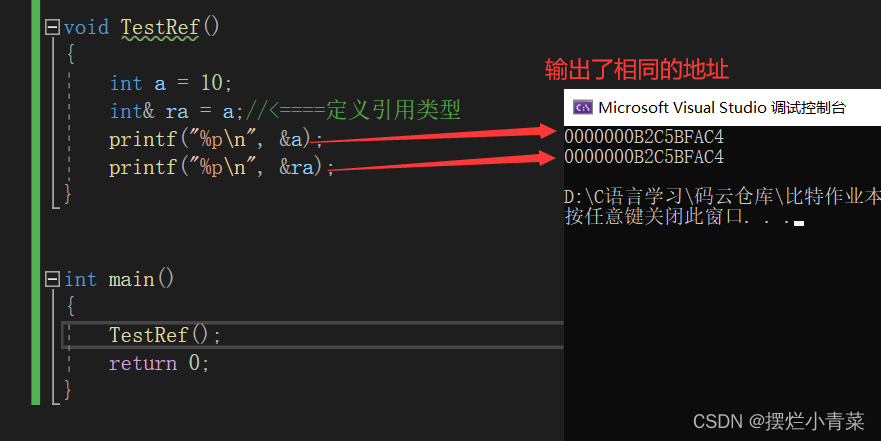
void TestRef() {int a = 10;int& ra = a; <====定义引用类型 内存中不存在一个叫ra的变量printf("%p\n", &a);printf("%p\n", &ra); }定义引用的操作符是&,代码段中相当于给变量a另取了一个标识名ra,通过标识名ra可以在其被定义的作用域中访问变量a.
注意引用在定义时必须初始化。
(在不考虑const修饰的情况下)引用类型必须和引用实体是同种类型的
二.引用的特性
1.一个变量可以有多个引用,并且引用可以嵌套定义。
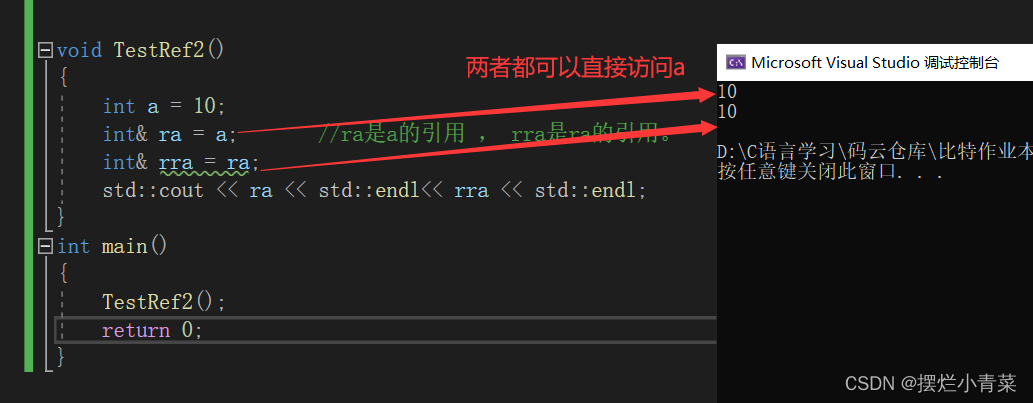
void TestRef1() {int a = 10;int& ra1 = a;int& ra2 = a; ra1和ra2都可以用于访问变量astd:: cout << &ra1 << &ra2 << &a << std::endl; }void TestRef2() {int a = 10;int& ra = a; ra是a的引用 , rra是ra的引用。int& rra = ra;std::cout << ra << rra << std::endl; }上面代码段中的TestRef2函数中,ra和rra都可以直接访问变量a,不需要像多级指针一样要多次解引用。
基于引用这种可以嵌套定义并且无需多次解引用就可以直接访问被引用变量的这种特性,很多时候使用引用可以避免多级指针的出现。
下面举个例子:现在简单地实现一个无头单链表
typedef struct Node {int data;struct Node* Next; }Node;void AddNode(Node** headptr,int Nodenums) //建表函数 {assert(headptr);if (NULL == *headptr) //检查链表头指针是否为空,若为空则接入头结点{if (NULL == (*headptr = new Node)) //检查内存申请是否成功{std::cout << "new failed" << std::endl;}(* headptr)->Next = NULL;std::cin >> (*headptr)->data;Nodenums--;}Node* pend = *headptr;for (pend = *headptr; NULL != pend->Next; pend = pend->Next); //利用该循环找到链表的尾 //结点int i = 0;for (i = 0; i < Nodenums; i++) //在尾结点后接入Nodenums //个新节点{if (NULL == (pend->Next = new Node)) //检查内存申请是否成功{std::cout << "new failed" << std::endl;}pend->Next->Next = NULL; //尾结点指针域赋空std::cin >> pend->Next->data; //尾结点数据域赋值pend = pend->Next; //令pend指向} } void PrinList(Node* headptr); void Destroy(Node** headptr);int main() {Node* headptr = NULL; //headptr作为链表的头指针int nums = 0;std::cin >> nums;AddNode(&headptr, nums); //nums是要建立的节点个数PrinList(headptr); //打印链表函数Destroy(&headptr); //销毁链表函数return 0; }可以看到,为了建表我们需要在建表函数AddNode中修改头指针headptr的值,因此传参时需要向AddNode函数中传入二级地址,然而如果我们将AddNode函数的形参设计成引用,级就可以避免二级指针的出现。
利用引用修改AddNode函数:
typedef struct Node {int data;struct Node* Next; }Node;void AddNode(Node*& headptr,int Nodenums) //建表函数,参数设计成引用 {if (NULL == headptr){if (NULL == (headptr = new Node)){std::cout << "new failed" << std::endl;}(headptr)->Next = NULL;std::cin >> (headptr)->data;Nodenums--;}Node* pend = headptr;for (pend = headptr; NULL != pend->Next; pend = pend->Next); //利用该循环找到链表的尾 //结点int i = 0;for (i = 0; i < Nodenums; i++) //在尾结点后接入Nodenums //个新节点{if (NULL == (pend->Next = new Node)){std::cout << "new failed" << std::endl;}pend->Next->Next = NULL;std::cin >> pend->Next->data;pend = pend->Next;} } void PrinList(Node* &headptr); void Destroy(Node* &headptr);int main() {Node* headptr = NULL; //headptr作为链表的头指针int nums = 0;std::cin >> nums;AddNode(headptr, nums); //直接传入标识名即可PrinList(headptr); //打印链表函数Destroy(headptr); //销毁链表函数return 0; }
使用引用可以避免多级指针的出现,从而增强代码的可读性和可维护性(多级指针代码的可读性差而且维护修改的时候很麻烦),这是引用这个语法的一个设计初衷之一。
2. 引用一旦引用一个实体,再不能引用其他实体
由于这个特性,引用无法完全代替指针(比如链表中结构体的Next指针无法用引用来代替,因为引用一旦引用一个实体,再不能引用其他实体),灵活性也不如指针,但是引用也因此比指针更安全,这也是引用这个语法的设计初衷之一(使用指针很容易出现野指针,非法访问内存空间的情况)。
3.常引用(被const 修饰的引用)
这是一个关于引用的语法小细节:
int main() {double a = 0;int& b = a; }上面的代码段中由于类型不匹配,无法通过编译,但是如果用const去修饰引用,则可以通过编译。(加上const是将b的读写权限限制为只读)
int main() {double a = 0;const int& b = a; }背后涉及更深层次的原理,暂不深究。
三.引用的一些应用场景
1.引用作为函数的形参(引用传参)
引用作为函数形参接受到实参后,在函数中,通过引用就可以直接访问到相应实参的内存空间,并修改或读取其中的内容(类似于函数的传址调用)。
结合引用和函数重载可以设计出用于交换各种类型数据的交换函数:
typedef struct Node {int data; }Node;void swap(int& a, int& b) {a = a ^ b;b = a ^ b;a = a ^ b; } void swap(double& a, double& b) {double tem = a;a = b;b = tem; } void swap(Node &a, Node& b) {Node tem = a;a = b;b = tem; } void swap(char& a, char& b) {a = a ^ b;b = a ^ b;a = a ^ b; }using std::cout; using std::endl;int main() {Node a = { 0 };Node b = { 1 };cout << "before exchange" << " a =" << a.data<< " b=" << b.data << endl;swap(a, b);cout << "after exchange" << " a =" << a.data << " b=" << b.data << endl;return 0; }
不得不说C++的新增语法确实能够让它创造比C语言更多的可能性。
可以将上述的swap函数封装到一个命名空间中,使用起来会非常方便。

2.引用作函数返回值
引用做函数的返回值:
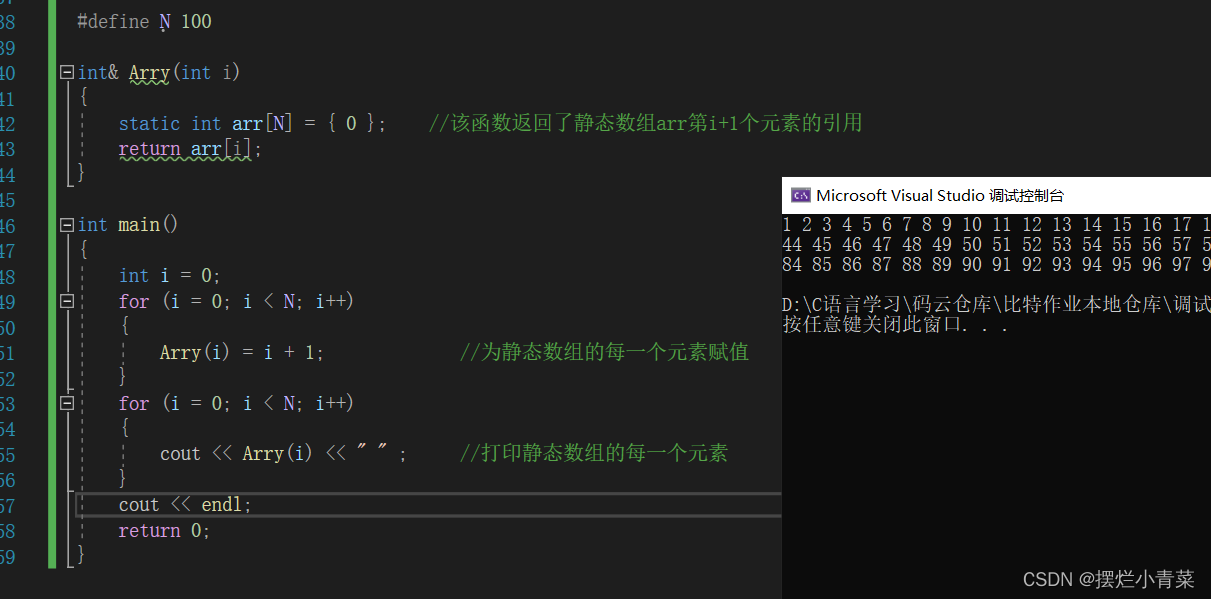
#define N 100int& Arry(int i) {static int arr[N] = { 0 }; //该函数返回了静态数组arr第i+1个元素的引用return arr[i]; }int main() {int i = 0;for (i = 0; i < N; i++){Arry(i) = i + 1; //为静态数组的每一个元素赋值}for (i = 0; i < N; i++) {cout << Arry(i) << " " ; //打印静态数组的每一个元素}cout << endl;return 0; }
引用做函数返回值时可能遇到的陷阱:
int& Add(int a, int b) {int c = a + b;return c; } int main() {int& ret = Add(1, 2); Add返回引用 则返回值用引用来接收Add(3, 4);cout << "Add(1, 2) is :" << ret << endl;return 0; }上面代码段中,Add调用完后,Add函数在栈区上申请的栈帧空间会归还给操作系统,所以原本函数中的标识名为c的空间不再属于程序,这时用ret去接收c的引用,如果再通过ret访问原来c变量所在的空间,就会造成非法访问(即使编译器不报错也很可能会访问到随机值)。
Add调用过程开辟栈帧空间的图解:
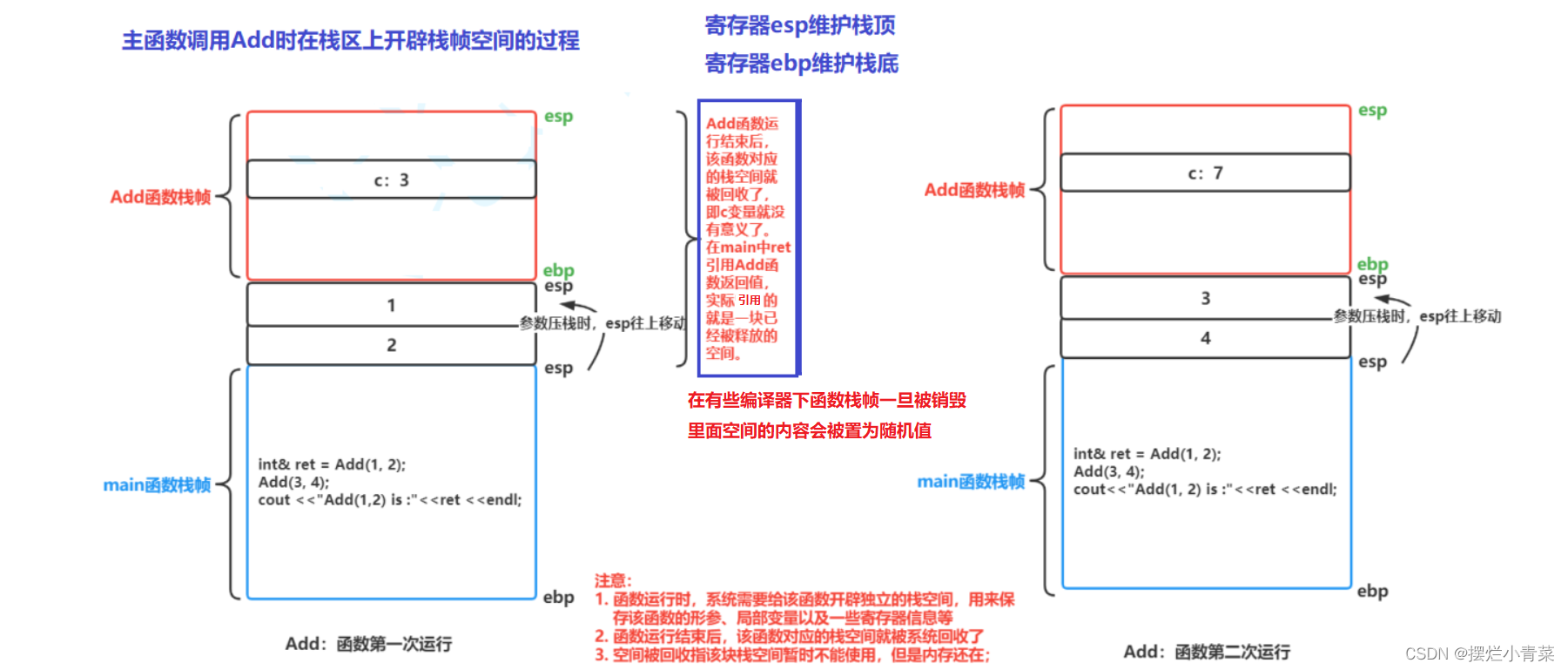
因此如果函数返回时,出了函数作用域,返回对象还在(还没还给系统),则可以使用
引用返回,如果已经还给系统了,则必须使用传值返回。
3.引用作为函数形参或作为函数返回值的好处
对于值传递和值返回的函数,在传参和返回期间,会传递实参或者返回变量的一份临时的拷贝,因此用值作为参数或者返回值类型,效率是非常低下的,尤其是当参数或者返回值类型字节数非常大时,效率就更低。
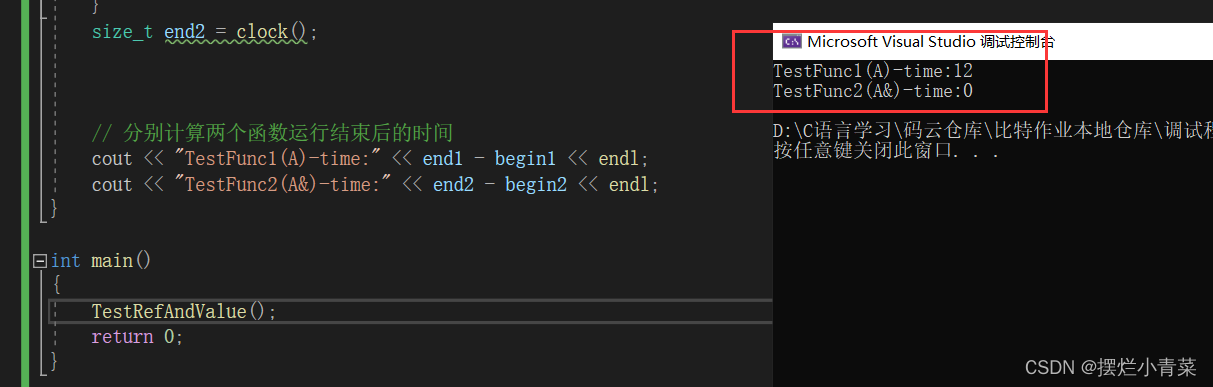
传值、传引用效率比较:
#include#include using std::cout; using std::endl; struct A { int a[10000]; }; void TestFunc1(A a) {} void TestFunc2(A& a) {}void TestRefAndValue() {A a;size_t begin1 = clock();for (size_t i = 0; i < 10000; ++i){TestFunc1(a); //以值作为函数参数}size_t end1 = clock();size_t begin2 = clock();for (size_t i = 0; i < 10000; ++i){TestFunc2(a); //以引用作为函数参数}size_t end2 = clock();// 分别计算两个函数运行结束后的时间cout << "TestFunc1(A)-time:" << end1 - begin1 << endl;cout << "TestFunc2(A&)-time:" << end2 - begin2 << endl; }int main() {TestRefAndValue();return 0; }
从上面的时间对比上可以看出,引用作为参数的函数运行效率更高。
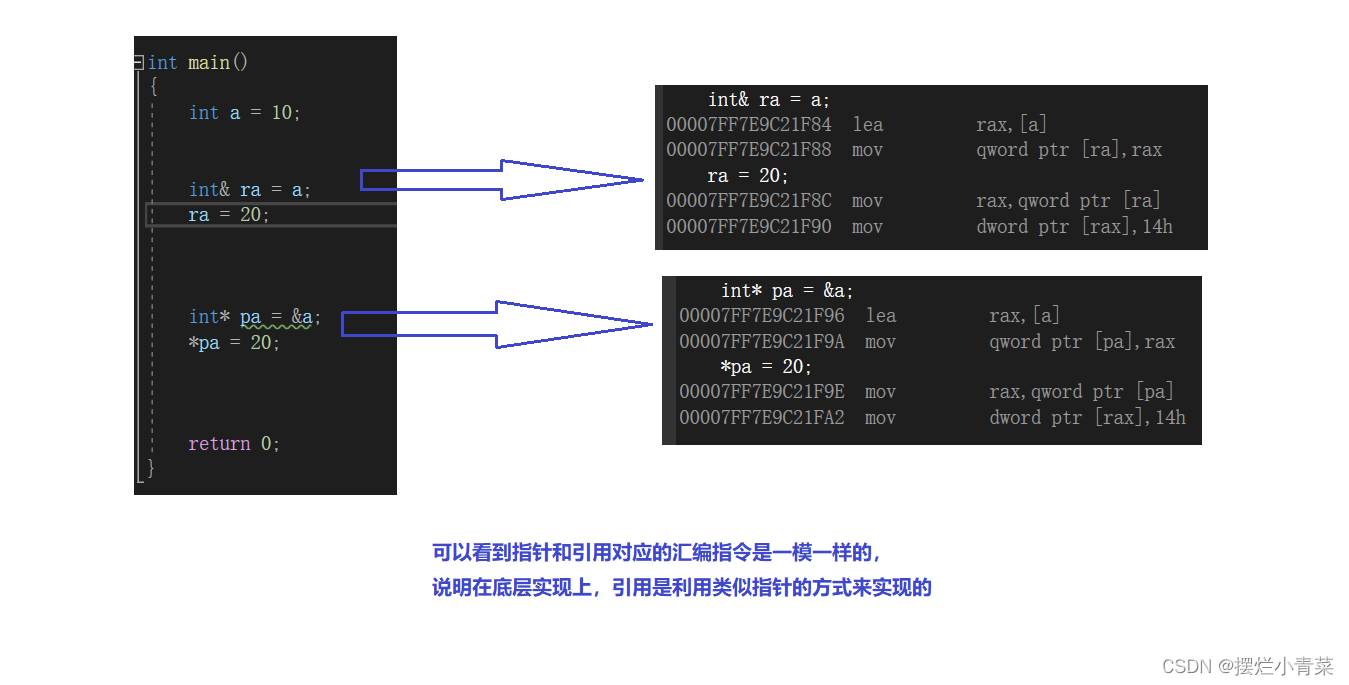
附:引用的定义和指针的定义的汇编代码
int main()
{int a = 10;int& ra = a;ra = 20;int* pa = &a;*pa = 20;return 0;
}

上一篇:C++ 引用! 他是坤坤也是鸡哥
下一篇:Docker 应用实践-容器篇