
Knowledge-based-BERT(三)
创始人
2024-05-19 19:16:48
0次
多种预训练任务解决NLP处理SMILES的多种弊端,代码:Knowledge-based-BERT,原文:Knowledge-based BERT: a method to extract molecular features like computational chemists,代码解析继续downstream_task。模型框架如下:
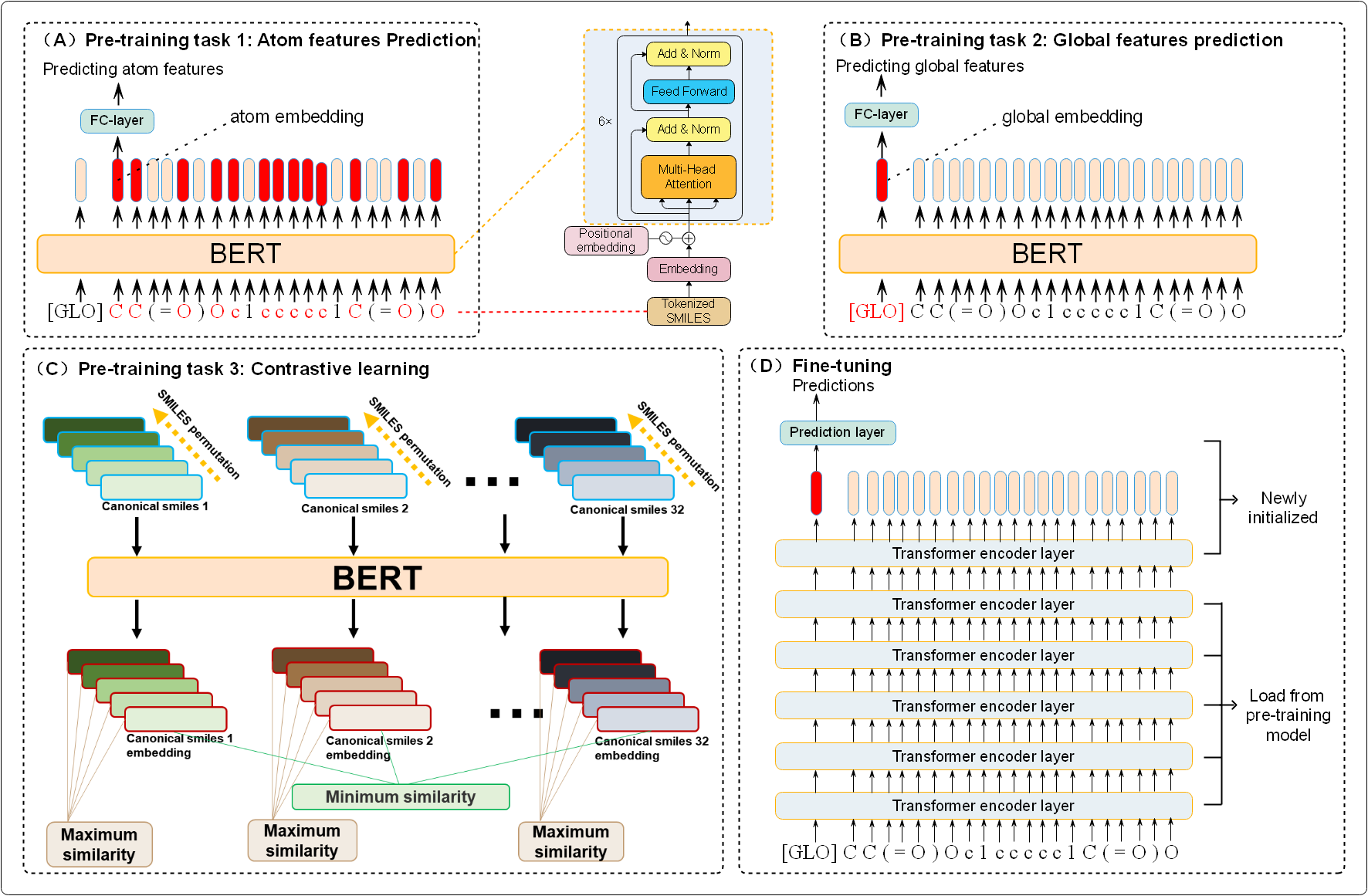
文章目录
- 1.load_data_for_random_splited
- 2.model
- 2.1.pos_weight
- 1.2.load_pretrained_model
- 3.run
- 3.1.run_an_eval_global_epoch
- 3.2.step
for task in args['task_name_list']:args['task_name'] = taskargs['data_path'] = '../data/task_data/' + args['task_name'] + '.npy'all_times_train_result = []all_times_val_result = []all_times_test_result = []result_pd = pd.DataFrame()result_pd['index'] = ['roc_auc', 'accuracy', 'sensitivity', 'specificity', 'f1-score', 'precision', 'recall','error rate', 'mcc']for time_id in range(args['times']):set_random_seed(2020+time_id)train_set, val_set, test_set, task_number = build_data.load_data_for_random_splited(data_path=args['data_path'], shuffle=True)print("Molecule graph is loaded!")
1.load_data_for_random_splited
def load_data_for_random_splited(data_path='example.npy', shuffle=True):data = np.load(data_path, allow_pickle=True)smiles_list = data[0]tokens_idx_list = data[1]labels_list = data[2]mask_list = data[3]group_list = data[4]if shuffle:random.shuffle(group_list)print(group_list)train_set = []val_set = []test_set = []task_number = len(labels_list[1])for i, group in enumerate(group_list):molecule = [smiles_list[i], tokens_idx_list[i], labels_list[i], mask_list[i]]if group == 'training':train_set.append(molecule)elif group == 'val':val_set.append(molecule)else:test_set.append(molecule)print('Training set: {}, Validation set: {}, Test set: {}, task number: {}'.format(len(train_set), len(val_set), len(test_set), task_number))return train_set, val_set, test_set, task_number
2.model
train_loader = DataLoader(dataset=train_set,batch_size=args['batch_size'],shuffle=True,collate_fn=collate_data)val_loader = DataLoader(dataset=val_set,batch_size=args['batch_size'],collate_fn=collate_data)test_loader = DataLoader(dataset=test_set,batch_size=args['batch_size'],collate_fn=collate_data)pos_weight_task = pos_weight(train_set)one_time_train_result = []one_time_val_result = []one_time_test_result = []print('***************************************************************************************************')print('{}, {}/{} time'.format(args['task_name'], time_id+1, args['times']))print('***************************************************************************************************')loss_criterion = torch.nn.BCEWithLogitsLoss(reduction='none', pos_weight=pos_weight_task.to(args['device']))model = K_BERT_WCL(d_model=args['d_model'], n_layers=args['n_layers'], vocab_size=args['vocab_size'],maxlen=args['maxlen'], d_k=args['d_k'], d_v=args['d_v'], n_heads=args['n_heads'], d_ff=args['d_ff'],global_label_dim=args['global_labels_dim'], atom_label_dim=args['atom_labels_dim'])stopper = EarlyStopping(patience=args['patience'], pretrained_model=args['pretrain_model'],pretrain_layer=args['pretrain_layer'],task_name=args['task_name']+'_downstream_k_bert_wcl', mode=args['mode'])model.to(args['device'])stopper.load_pretrained_model(model)optimizer = Adam(model.parameters(), lr=args['lr'])
2.1.pos_weight
def pos_weight(train_set):smiles, tokens_idx, labels, mask = map(list, zip(*train_set))task_pos_weight_list = []for j in range(len(labels[1])):num_pos = 0num_impos = 0for i in labels:if i[j] == 1:num_pos = num_pos + 1if i[j] == 0:num_impos = num_impos + 1task_pos_weight = num_impos / (num_pos+0.00000001)task_pos_weight_list.append(task_pos_weight)return torch.tensor(task_pos_weight_list)
- 这里不理解为什么这么设置 task_pos_weight_list
1.2.load_pretrained_model
def load_pretrained_model(self, model):if self.pretrain_layer == 1:pretrained_parameters = ['embedding.tok_embed.weight', 'embedding.pos_embed.weight', 'embedding.norm.weight', 'embedding.norm.bias', 'layers.0.enc_self_attn.linear.weight', 'layers.0.enc_self_attn.linear.bias', 'layers.0.enc_self_attn.layernorm.weight', 'layers.0.enc_self_attn.layernorm.bias', 'layers.0.enc_self_attn.W_Q.weight', 'layers.0.enc_self_attn.W_Q.bias', 'layers.0.enc_self_attn.W_K.weight', 'layers.0.enc_self_attn.W_K.bias', 'layers.0.enc_self_attn.W_V.weight', 'layers.0.enc_self_attn.W_V.bias', 'layers.0.pos_ffn.fc.0.weight', 'layers.0.pos_ffn.fc.2.weight', 'layers.0.pos_ffn.layernorm.weight', 'layers.0.pos_ffn.layernorm.bias']elif self.pretrain_layer == 2:pretrained_parameters = ['embedding.tok_embed.weight', 'embedding.pos_embed.weight', 'embedding.norm.weight', 'embedding.norm.bias', 'layers.0.enc_self_attn.linear.weight', 'layers.0.enc_self_attn.linear.bias', 'layers.0.enc_self_attn.layernorm.weight', 'layers.0.enc_self_attn.layernorm.bias', 'layers.0.enc_self_attn.W_Q.weight', 'layers.0.enc_self_attn.W_Q.bias', 'layers.0.enc_self_attn.W_K.weight', 'layers.0.enc_self_attn.W_K.bias', 'layers.0.enc_self_attn.W_V.weight', 'layers.0.enc_self_attn.W_V.bias', 'layers.0.pos_ffn.fc.0.weight', 'layers.0.pos_ffn.fc.2.weight', 'layers.0.pos_ffn.layernorm.weight', 'layers.0.pos_ffn.layernorm.bias', 'layers.1.enc_self_attn.linear.weight', 'layers.1.enc_self_attn.linear.bias', 'layers.1.enc_self_attn.layernorm.weight', 'layers.1.enc_self_attn.layernorm.bias', 'layers.1.enc_self_attn.W_Q.weight', 'layers.1.enc_self_attn.W_Q.bias', 'layers.1.enc_self_attn.W_K.weight', 'layers.1.enc_self_attn.W_K.bias', 'layers.1.enc_self_attn.W_V.weight', 'layers.1.enc_self_attn.W_V.bias', 'layers.1.pos_ffn.fc.0.weight', 'layers.1.pos_ffn.fc.2.weight', 'layers.1.pos_ffn.layernorm.weight', 'layers.1.pos_ffn.layernorm.bias']elif self.pretrain_layer == 3:...elif self.pretrain_layer == 'all_12layer':pretrained_parameters = ['embedding.tok_embed.weight', 'embedding.pos_embed.weight','embedding.norm.weight', 'embedding.norm.bias','layers.0.enc_self_attn.linear.weight', 'layers.0.enc_self_attn.linear.bias','layers.0.enc_self_attn.layernorm.weight', 'layers.0.enc_self_attn.layernorm.bias','layers.0.enc_self_attn.W_Q.weight', 'layers.0.enc_self_attn.W_Q.bias','layers.0.enc_self_attn.W_K.weight', 'layers.0.enc_self_attn.W_K.bias','layers.0.enc_self_attn.W_V.weight', 'layers.0.enc_self_attn.W_V.bias','layers.0.pos_ffn.fc.0.weight', 'layers.0.pos_ffn.fc.2.weight','layers.0.pos_ffn.layernorm.weight', 'layers.0.pos_ffn.layernorm.bias','layers.1.enc_self_attn.linear.weight', 'layers.1.enc_self_attn.linear.bias','layers.1.enc_self_attn.layernorm.weight', 'layers.1.enc_self_attn.layernorm.bias','layers.1.enc_self_attn.W_Q.weight', 'layers.1.enc_self_attn.W_Q.bias','layers.1.enc_self_attn.W_K.weight', 'layers.1.enc_self_attn.W_K.bias','layers.1.enc_self_attn.W_V.weight', 'layers.1.enc_self_attn.W_V.bias','layers.1.pos_ffn.fc.0.weight', 'layers.1.pos_ffn.fc.2.weight','layers.1.pos_ffn.layernorm.weight', 'layers.1.pos_ffn.layernorm.bias','layers.2.enc_self_attn.linear.weight', 'layers.2.enc_self_attn.linear.bias','layers.2.enc_self_attn.layernorm.weight', 'layers.2.enc_self_attn.layernorm.bias','layers.2.enc_self_attn.W_Q.weight', 'layers.2.enc_self_attn.W_Q.bias','layers.2.enc_self_attn.W_K.weight', 'layers.2.enc_self_attn.W_K.bias','layers.2.enc_self_attn.W_V.weight', 'layers.2.enc_self_attn.W_V.bias','layers.2.pos_ffn.fc.0.weight', 'layers.2.pos_ffn.fc.2.weight','layers.2.pos_ffn.layernorm.weight', 'layers.2.pos_ffn.layernorm.bias','layers.3.enc_self_attn.linear.weight', 'layers.3.enc_self_attn.linear.bias','layers.3.enc_self_attn.layernorm.weight', 'layers.3.enc_self_attn.layernorm.bias','layers.3.enc_self_attn.W_Q.weight', 'layers.3.enc_self_attn.W_Q.bias','layers.3.enc_self_attn.W_K.weight', 'layers.3.enc_self_attn.W_K.bias','layers.3.enc_self_attn.W_V.weight', 'layers.3.enc_self_attn.W_V.bias','layers.3.pos_ffn.fc.0.weight', 'layers.3.pos_ffn.fc.2.weight','layers.3.pos_ffn.layernorm.weight', 'layers.3.pos_ffn.layernorm.bias','layers.4.enc_self_attn.linear.weight', 'layers.4.enc_self_attn.linear.bias','layers.4.enc_self_attn.layernorm.weight', 'layers.4.enc_self_attn.layernorm.bias','layers.4.enc_self_attn.W_Q.weight', 'layers.4.enc_self_attn.W_Q.bias','layers.4.enc_self_attn.W_K.weight', 'layers.4.enc_self_attn.W_K.bias','layers.4.enc_self_attn.W_V.weight', 'layers.4.enc_self_attn.W_V.bias','layers.4.pos_ffn.fc.0.weight', 'layers.4.pos_ffn.fc.2.weight','layers.4.pos_ffn.layernorm.weight', 'layers.4.pos_ffn.layernorm.bias','layers.5.enc_self_attn.linear.weight', 'layers.5.enc_self_attn.linear.bias','layers.5.enc_self_attn.layernorm.weight', 'layers.5.enc_self_attn.layernorm.bias','layers.5.enc_self_attn.W_Q.weight', 'layers.5.enc_self_attn.W_Q.bias','layers.5.enc_self_attn.W_K.weight', 'layers.5.enc_self_attn.W_K.bias','layers.5.enc_self_attn.W_V.weight', 'layers.5.enc_self_attn.W_V.bias','layers.5.pos_ffn.fc.0.weight', 'layers.5.pos_ffn.fc.2.weight','layers.5.pos_ffn.layernorm.weight', 'layers.5.pos_ffn.layernorm.bias','layers.6.enc_self_attn.linear.weight', 'layers.6.enc_self_attn.linear.bias','layers.6.enc_self_attn.layernorm.weight', 'layers.6.enc_self_attn.layernorm.bias','layers.6.enc_self_attn.W_Q.weight', 'layers.6.enc_self_attn.W_Q.bias','layers.6.enc_self_attn.W_K.weight', 'layers.6.enc_self_attn.W_K.bias','layers.6.enc_self_attn.W_V.weight', 'layers.6.enc_self_attn.W_V.bias','layers.6.pos_ffn.fc.0.weight', 'layers.6.pos_ffn.fc.2.weight','layers.6.pos_ffn.layernorm.weight', 'layers.6.pos_ffn.layernorm.bias','layers.7.enc_self_attn.linear.weight', 'layers.7.enc_self_attn.linear.bias','layers.7.enc_self_attn.layernorm.weight', 'layers.7.enc_self_attn.layernorm.bias','layers.7.enc_self_attn.W_Q.weight', 'layers.7.enc_self_attn.W_Q.bias','layers.7.enc_self_attn.W_K.weight', 'layers.7.enc_self_attn.W_K.bias','layers.7.enc_self_attn.W_V.weight', 'layers.7.enc_self_attn.W_V.bias','layers.7.pos_ffn.fc.0.weight', 'layers.7.pos_ffn.fc.2.weight','layers.7.pos_ffn.layernorm.weight', 'layers.7.pos_ffn.layernorm.bias','layers.8.enc_self_attn.linear.weight', 'layers.8.enc_self_attn.linear.bias','layers.8.enc_self_attn.layernorm.weight', 'layers.8.enc_self_attn.layernorm.bias','layers.8.enc_self_attn.W_Q.weight', 'layers.8.enc_self_attn.W_Q.bias','layers.8.enc_self_attn.W_K.weight', 'layers.8.enc_self_attn.W_K.bias','layers.8.enc_self_attn.W_V.weight', 'layers.8.enc_self_attn.W_V.bias','layers.8.pos_ffn.fc.0.weight', 'layers.8.pos_ffn.fc.2.weight','layers.8.pos_ffn.layernorm.weight', 'layers.8.pos_ffn.layernorm.bias','layers.9.enc_self_attn.linear.weight', 'layers.9.enc_self_attn.linear.bias','layers.9.enc_self_attn.layernorm.weight', 'layers.9.enc_self_attn.layernorm.bias','layers.9.enc_self_attn.W_Q.weight', 'layers.9.enc_self_attn.W_Q.bias','layers.9.enc_self_attn.W_K.weight', 'layers.9.enc_self_attn.W_K.bias','layers.9.enc_self_attn.W_V.weight', 'layers.9.enc_self_attn.W_V.bias','layers.9.pos_ffn.fc.0.weight', 'layers.9.pos_ffn.fc.2.weight','layers.9.pos_ffn.layernorm.weight', 'layers.9.pos_ffn.layernorm.bias','layers.10.enc_self_attn.linear.weight', 'layers.10.enc_self_attn.linear.bias','layers.10.enc_self_attn.layernorm.weight','layers.10.enc_self_attn.layernorm.bias', 'layers.10.enc_self_attn.W_Q.weight','layers.10.enc_self_attn.W_Q.bias', 'layers.10.enc_self_attn.W_K.weight','layers.10.enc_self_attn.W_K.bias', 'layers.10.enc_self_attn.W_V.weight','layers.10.enc_self_attn.W_V.bias', 'layers.10.pos_ffn.fc.0.weight','layers.10.pos_ffn.fc.2.weight', 'layers.10.pos_ffn.layernorm.weight','layers.10.pos_ffn.layernorm.bias''fc.1.weight', 'fc.1.bias', 'fc.3.weight', 'fc.3.bias', 'classifier_global.weight','classifier_global.bias', 'classifier_atom.weight', 'classifier_atom.bias']pretrained_model = torch.load(self.pretrained_model, map_location=torch.device('cpu'))# pretrained_model = torch.load(self.pretrained_model)model_dict = model.state_dict()pretrained_dict = {k: v for k, v in pretrained_model['model_state_dict'].items() if k in pretrained_parameters}model_dict.update(pretrained_dict)model.load_state_dict(pretrained_dict, strict=False)
3.run
for epoch in range(args['num_epochs']):train_score = run_a_train_global_epoch(args, epoch, model, train_loader, loss_criterion, optimizer)# Validation and early stop_ = run_an_eval_global_epoch(args, model, train_loader)[0]val_score = run_an_eval_global_epoch(args, model, val_loader)[0]test_score = run_an_eval_global_epoch(args, model, test_loader)[0]if epoch < 5:early_stop = stopper.step(0, model)else:early_stop = stopper.step(val_score, model)print('epoch {:d}/{:d}, {}, lr: {:.6f}, train: {:.4f}, valid: {:.4f}, best valid {:.4f}, ''test: {:.4f}'.format(epoch + 1, args['num_epochs'], args['metric_name'], optimizer.param_groups[0]['lr'], train_score, val_score,stopper.best_score, test_score))if early_stop:break
stopper.load_checkpoint(model)
3.1.run_an_eval_global_epoch
def run_an_eval_global_epoch(args, model, data_loader):model.eval()eval_meter = Meter()with torch.no_grad():for batch_id, batch_data in enumerate(data_loader):smiles, token_idx, global_labels, mask = batch_datatoken_idx = token_idx.long().to(args['device'])mask = mask.float().to(args['device'])global_labels = global_labels.float().to(args['device'])logits_global = model(token_idx)eval_meter.update(logits_global, global_labels, mask=mask)del token_idx, global_labelstorch.cuda.empty_cache()y_pred, y_true = eval_meter.compute_metric('return_pred_true')y_true_list = y_true.squeeze(dim=1).tolist()y_pred_list = torch.sigmoid(y_pred).squeeze(dim=1).tolist()# save predictiony_pred_label = [1 if x >= 0.5 else 0 for x in y_pred_list]auc = metrics.roc_auc_score(y_true_list, y_pred_list)accuracy = metrics.accuracy_score(y_true_list, y_pred_label)se, sp = sesp_score(y_true_list, y_pred_label)pre, rec, f1, sup = metrics.precision_recall_fscore_support(y_true_list, y_pred_label)mcc = metrics.matthews_corrcoef(y_true_list, y_pred_label)f1 = f1[1]rec = rec[1]pre = pre[1]err = 1 - accuracyresult = [auc, accuracy, se, sp, f1, pre, rec, err, mcc]return result
3.2.step
def step(self, score, model):if self.best_score is None:self.best_score = scoreself.save_checkpoint(model)elif self._check(score, self.best_score):self.best_score = scoreself.save_checkpoint(model)self.counter = 0else:self.counter += 1print('EarlyStopping counter: {} out of {}'.format(self.counter, self.patience))if self.counter >= self.patience:self.early_stop = Truereturn self.early_stop
上一篇:学习C++基本数值类型
下一篇:springboot 定时任务
相关内容
热门资讯
安卓子系统windows11,...
你知道吗?最近科技圈可是炸开了锅,因为安卓子系统在Windows 11上的兼容性成了大家热议的话题。...
电脑里怎么下载安卓系统,电脑端...
你有没有想过,你的电脑里也能装上安卓系统呢?没错,就是那个让你手机不离手的安卓!今天,就让我来带你一...
索尼相机魔改安卓系统,魔改系统...
你知道吗?最近在摄影圈里掀起了一股热潮,那就是索尼相机魔改安卓系统。这可不是一般的改装,而是让这些专...
安卓系统哪家的最流畅,安卓系统...
你有没有想过,为什么你的手机有时候像蜗牛一样慢吞吞的,而别人的手机却能像风一样快?这背后,其实就是安...
安卓最新系统4.42,深度解析...
你有没有发现,你的安卓手机最近是不是有点儿不一样了?没错,就是那个一直在默默更新的安卓最新系统4.4...
android和安卓什么系统最...
你有没有想过,你的安卓手机到底是用的是什么系统呢?是不是有时候觉得手机卡顿,运行缓慢,其实跟这个系统...
平板装安卓xp系统好,探索复古...
你有没有想过,把安卓系统装到平板上,再配上XP系统,这会是怎样一番景象呢?想象一边享受着安卓的便捷,...
投影仪装安卓系统,开启智能投影...
你有没有想过,家里的老式投影仪也能焕发第二春呢?没错,就是那个曾经陪你熬夜看电影的“老伙计”,现在它...
安卓系统无线车载carplay...
你有没有想过,开车的时候也能享受到苹果设备的便利呢?没错,就是那个让你在日常生活中离不开的iOS系统...
谷歌安卓8系统包,系统包解析与...
你有没有发现,手机更新换代的速度简直就像坐上了火箭呢?这不,最近谷歌又发布了安卓8系统包,听说这个新...
微软平板下软件安卓系统,开启全...
你有没有想过,在微软平板上也能畅享安卓系统的乐趣呢?没错,这就是今天我要跟你分享的神奇故事。想象你手...
coloros是基于安卓系统吗...
你有没有想过,手机里的那个色彩斑斓的界面,背后其实有着一个有趣的故事呢?没错,我要说的就是Color...
安卓神盾系统应用市场,一站式智...
你有没有发现,手机里的安卓神盾系统应用市场最近可是火得一塌糊涂啊!这不,我就来给你好好扒一扒,看看这...
黑莓平板安卓系统升级,解锁无限...
亲爱的读者们,你是否还记得那个曾经风靡一时的黑莓手机?那个标志性的全键盘,那个独特的黑莓体验,如今它...
安卓文件系统采用华为,探索高效...
你知道吗?最近安卓系统在文件管理上可是有了大动作呢!华为这个科技巨头,竟然悄悄地给安卓文件系统来了个...
深度系统能用安卓app,探索智...
你知道吗?现在科技的发展真是让人惊叹不已!今天,我要给你揭秘一个超级酷炫的话题——深度系统能用安卓a...
安卓系统的分区类型,深度解析存...
你有没有发现,你的安卓手机里藏着不少秘密?没错,就是那些神秘的分区类型。今天,就让我带你一探究竟,揭...
安卓系统铠无法兑换,揭秘无法兑...
最近是不是有很多小伙伴在玩安卓系统的游戏,突然发现了一个让人头疼的问题——铠无法兑换!别急,今天就来...
汽车安卓系统崩溃怎么刷,一键刷...
亲爱的车主朋友们,你是否曾遇到过汽车安卓系统崩溃的尴尬时刻?手机系统崩溃还能重启,但汽车系统崩溃了,...
miui系统可以刷安卓p系统吗...
亲爱的手机控们,你是否对MIUI系统情有独钟,同时又对安卓P系统的新鲜功能垂涎欲滴?今天,就让我带你...