
BP神经网络的梯度公式推导(三层结构)
创始人
2024-05-26 19:41:11
0次
本站原创文章,转载请说明来自《老饼讲解-BP神经网络》bp.bbbdata.com
目录
一. 推导目标
1.1 梯度公式目标
1.2 本文梯度公式目标
二. 网络表达式梳理
2.1 梳理三层BP神经网络的网络表达式
三. 三层BP神经网络梯度推导过程
3.1 简化推导目标
3.2 输出层权重的梯度推导
3.3 输出层阈值的梯度推导
3.4隐层权重的梯度推导
3.5 隐层阈值的梯度推导
四. 推导结果总结
4.1 三层BP神经网络梯度公式
BP神经网络的训练算法基本都涉及到梯度公式,
本文提供三层BP神经网络的梯度公式和推导过程
一. 推导目标
BP神经网络的梯度推导是个复杂活,
在推导之前 ,本节先把推导目标清晰化
1.1 梯度公式目标
训练算法很多,但各种训练算法一般都需要用到各个待求参数(w,b)在损失函数中的梯度,
因此求出w,b在损失函数中的梯度就成为了BP神经网络必不可少的一环,
求梯度公式,即求以下误差函数E对各个w,b的偏导:
代表网络对第m个样本第k个输出的预测值,w,b就隐含在
中
1.2 本文梯度公式目标
虽然梯度只是简单地求E对w,b的偏导,但E中包含网络的表达式f(x),就变得非常庞大,
求偏导就成了极度艰巨晦涩的苦力活,对多层结构通式的梯度推导稍为抽象,
本文不妨以最常用的三层结构作为具体例子入手,求出三层结构的梯度公式
即:输入层-隐层-输出层 (隐层传递函数为tansig,输出层传递函数为purelin)
虽然只是三层的BP神经网络,
但梯度公式的推导,仍然不仅是一个体力活,还是一个细致活,
且让我们细细一步一步慢慢来
二. 网络表达式梳理
在损失函数E中包括了网络表达式,在求梯度之前,
先将表达式的梳理清晰,有助于后面的推导
2.1 梳理三层BP神经网络的网络表达式
网络表达式的参考形式
隐层传递函数为tansig,输出层传递函数为purelin的三层BP神经网络,
有形如下式的数学表达式
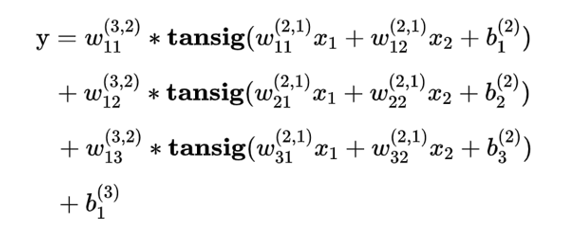
网络表达式的通用矩阵形式
写成通用的矩阵形式为
这里的为矩阵,
和
为向量,
上标(o)和(h)分别代表输出层(out)和隐层(hide),
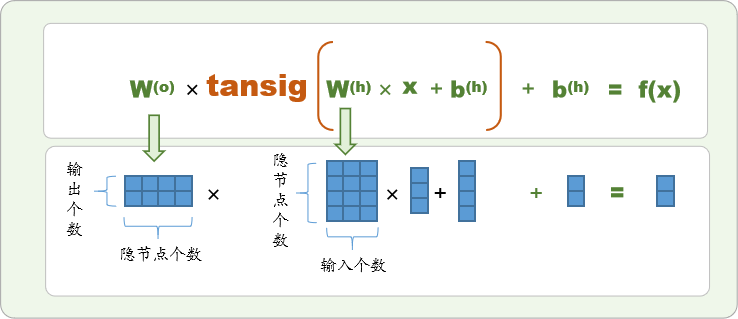
例如,2输入,4隐节点,2输出的BP神经网络可以图解如下:
三. 三层BP神经网络梯度推导过程
本节我们具体推导误差函数对每一个待求参数w,b的梯度
3.1 简化推导目标
由于E的表达式较为复杂,
不妨先将问题转化为"求单样本梯度"来简化推导表达式
对于任何一个需要求偏导的待求参数w,都有: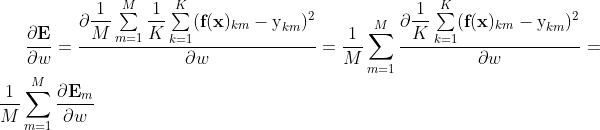
即损失函数的梯度,等于单个样本的损失函数的梯度之和(E对b的梯度也如此),
因此,我们先推导单个样本的梯度,最后再对单样本梯度求和即可。
现在问题简化为求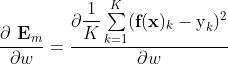
3.2 输出层权重的梯度推导
输出层权重梯度推导
输出层的权重为"输出个数*隐节点个数"的矩阵,
现推导任意一个权重wji (即连接第i个隐层与第j个输出的权重)的单样本梯度
如下:
事实上,只有第j个输出是关于
的函数,也即对于其它输出
因此,
上式即等于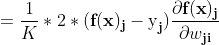
继续求导是第j个输出的误差,简记为
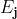
是第j个隐节点的激活值,简记为
(A即Active)
上式即可写为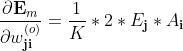
上述是单样本的梯度,
整体样本的梯度则应记为
M,K为样本个数、输出个数是第m个样本第j个输出的误差
是第m个样本第i个隐节点的激活值
3.3 输出层阈值的梯度推导
输出层阈值梯度推导
对于阈值(第j个输出节点的阈值)的推导与权重梯度的推导是类似的,
只是上述标蓝部分应改为
简记为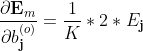
上述是单样本的梯度,
整体样本的梯度则应记为
M,K为样本个数、输出个数
3.4隐层权重的梯度推导
隐层的权重为"隐节点个数*输入个数"的矩阵,
现推导任意一个权重(即连接第i个输入与第j个隐节点的权重)的单样本梯度
如下:
只有第j个tansig是关于
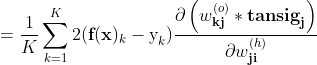
继续求导



又由
所以上式为:
简写为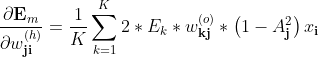
上述是单样本的梯度,对整体样本则有:
M,KM,K为样本个数、输出个数是第m个样本第k个输出的误差
是第m个样本第i个输入
3.5 隐层阈值的梯度推导
隐层阈值梯度推导
对于阈值b_\textbf{j}^{(h)} (第j个隐节点的阈值)的推导与隐层权重梯度的推导是类似的,
只是蓝色部分应改为
又由
所以上式为:
简写为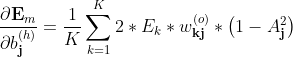
上述是单样本的梯度,对整体样本则有:
M,K为样本个数、输出个数
四. 推导结果总结
4.1 三层BP神经网络梯度公式
输出层梯度公式
输出层权重梯度: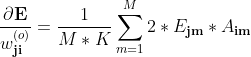
输出层阈值梯度: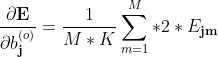
隐层梯度公式
隐层权重梯度:
隐层阈值梯度: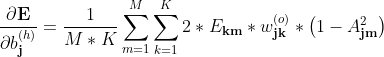
✍️符号说明
M,K为样本个数、输出个数
相关文章
《BP神经网络梯度推导》
《BP神经网络提取的数学表达式》
《一个BP的完整建模流程》
上一篇:程序员都在用的免费常用API
下一篇:Python 模块和包
相关内容
热门资讯
安卓子系统windows11,...
你知道吗?最近科技圈可是炸开了锅,因为安卓子系统在Windows 11上的兼容性成了大家热议的话题。...
电脑里怎么下载安卓系统,电脑端...
你有没有想过,你的电脑里也能装上安卓系统呢?没错,就是那个让你手机不离手的安卓!今天,就让我来带你一...
索尼相机魔改安卓系统,魔改系统...
你知道吗?最近在摄影圈里掀起了一股热潮,那就是索尼相机魔改安卓系统。这可不是一般的改装,而是让这些专...
安卓系统哪家的最流畅,安卓系统...
你有没有想过,为什么你的手机有时候像蜗牛一样慢吞吞的,而别人的手机却能像风一样快?这背后,其实就是安...
安卓最新系统4.42,深度解析...
你有没有发现,你的安卓手机最近是不是有点儿不一样了?没错,就是那个一直在默默更新的安卓最新系统4.4...
android和安卓什么系统最...
你有没有想过,你的安卓手机到底是用的是什么系统呢?是不是有时候觉得手机卡顿,运行缓慢,其实跟这个系统...
平板装安卓xp系统好,探索复古...
你有没有想过,把安卓系统装到平板上,再配上XP系统,这会是怎样一番景象呢?想象一边享受着安卓的便捷,...
投影仪装安卓系统,开启智能投影...
你有没有想过,家里的老式投影仪也能焕发第二春呢?没错,就是那个曾经陪你熬夜看电影的“老伙计”,现在它...
安卓系统无线车载carplay...
你有没有想过,开车的时候也能享受到苹果设备的便利呢?没错,就是那个让你在日常生活中离不开的iOS系统...
谷歌安卓8系统包,系统包解析与...
你有没有发现,手机更新换代的速度简直就像坐上了火箭呢?这不,最近谷歌又发布了安卓8系统包,听说这个新...
微软平板下软件安卓系统,开启全...
你有没有想过,在微软平板上也能畅享安卓系统的乐趣呢?没错,这就是今天我要跟你分享的神奇故事。想象你手...
coloros是基于安卓系统吗...
你有没有想过,手机里的那个色彩斑斓的界面,背后其实有着一个有趣的故事呢?没错,我要说的就是Color...
安卓神盾系统应用市场,一站式智...
你有没有发现,手机里的安卓神盾系统应用市场最近可是火得一塌糊涂啊!这不,我就来给你好好扒一扒,看看这...
黑莓平板安卓系统升级,解锁无限...
亲爱的读者们,你是否还记得那个曾经风靡一时的黑莓手机?那个标志性的全键盘,那个独特的黑莓体验,如今它...
安卓文件系统采用华为,探索高效...
你知道吗?最近安卓系统在文件管理上可是有了大动作呢!华为这个科技巨头,竟然悄悄地给安卓文件系统来了个...
深度系统能用安卓app,探索智...
你知道吗?现在科技的发展真是让人惊叹不已!今天,我要给你揭秘一个超级酷炫的话题——深度系统能用安卓a...
安卓系统的分区类型,深度解析存...
你有没有发现,你的安卓手机里藏着不少秘密?没错,就是那些神秘的分区类型。今天,就让我带你一探究竟,揭...
安卓系统铠无法兑换,揭秘无法兑...
最近是不是有很多小伙伴在玩安卓系统的游戏,突然发现了一个让人头疼的问题——铠无法兑换!别急,今天就来...
汽车安卓系统崩溃怎么刷,一键刷...
亲爱的车主朋友们,你是否曾遇到过汽车安卓系统崩溃的尴尬时刻?手机系统崩溃还能重启,但汽车系统崩溃了,...
miui系统可以刷安卓p系统吗...
亲爱的手机控们,你是否对MIUI系统情有独钟,同时又对安卓P系统的新鲜功能垂涎欲滴?今天,就让我带你...