
Redis学习【11】之分布式系统
创始人
2024-05-28 21:55:03
0次
文章目录
- 一 数据分区算法
- 1.1 顺序分区
- 1.1.1 轮询分区算法
- 1.1.2 时间片轮转分区算法
- 1.1.3 数据块分区算法
- 1.1.4 业务主题分区算法
- 1.2 哈希分区
- 1.2.1 节点取模分区算法
- 1.2.2 一致性哈希分区算法
- 1.2.3 虚拟槽分区算法
- 二 分布式系统环境搭建与运行
- 2.1 系统搭建
- 2.1.1 系统架构
- 2.1.2 删除持久化文件
- 2.1.3 创建目录
- 2.1.4 复制 2 个配置文件
- 2.1.5 修改 redis.conf
- 2.1.6 修改 redis6380.conf
- 2.1.7 复制 5 个配置文件
- 2.1.8 修改 5 个配置文件
- 2.2 系统启动与关闭
- 2.2.1 启动节点
- 2.2.2 创建分布式系统
- 2.2.3 测试系统
- 2.2.4 关闭系统
- 三 集群操作
- 3.1 连接集群
- 3.2 写入数据
- 3.2.1 key 单个写入&批量操作
- 3.3 集群查询
- 3.3.1 查询 key 的 slot
- 3.3.2 查询 slot 中 key 的数量
- 3.3.3 查询 slot 中的 key
- 3.4 故障转移
- 3.4.1 故障转移
- 3.4.2 全覆盖需求
- 四 分布式系统的限制
- Redis 分布式系统【Redis Cluster Redis 集群】是 Redis 3.0 开始推出的分布式解决方案。其可以很好地解决不同 Redis 节点存放不同数据,并将用户请求方便地路由到不同 Redis 的问题。
一 数据分区算法
- 分布式数据库系统会根据不同的数据分区算法,将数据分散存储到不同的数据库服务器节点上,每个节点管理着整个数据集合中的一个子集。
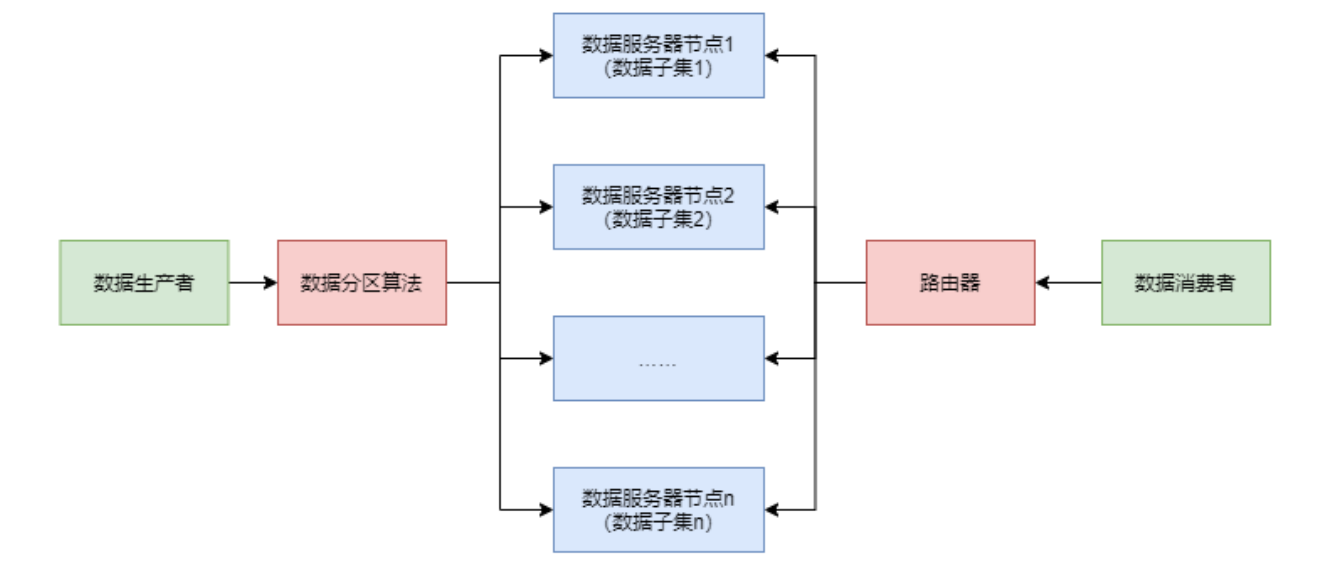
1.1 顺序分区
- 顺序分区规则可以将数据按照某种顺序平均分配到不同的节点。不同的顺序方式,产生了不同的分区算法。
- 如:轮询分区算法、时间片轮转分区算法、数据块分区算法、业务主题分区算法等
1.1.1 轮询分区算法
- 每产生一个数据,就依次分配到不同的节点。该算法适合于数据问题不确定的场景。
- 优点:在数据总量非常庞大的情况下,每个节点中数据是很平均的
- 缺点:生产者与数据节点间的连接要长时间保持
1.1.2 时间片轮转分区算法
- 在某固定长度的时间片内的数据都会分配到一个节点。时间片结束,再产生的数据就会被分配到下一个节点。这些节点会被依次轮转分配数据。
- 优点:生产者与节点间的连接只需占用当前正在使用的,其它连接使用完毕后就立即释放。
- 缺点:该算法可能会出现节点数据不平均的情况(因为每个时间片内产生的数据量可能是不同的)。
1.1.3 数据块分区算法
- 在整体数据总量确定的情况下,根据各个节点的存储能力,可以将连接的某一整块数据分配到某一节点
1.1.4 业务主题分区算法
- 数据可根据不同的业务主题,分配到不同的节点
1.2 哈希分区
- 哈希分区规则是充分利用数据的哈希值来完成分配,对数据哈希值的不同使用方式产生了不同的哈希分区算法。
1.2.1 节点取模分区算法
- 该算法的前提是,每个节点都已分配好了一个唯一序号,对于 NNN 个节点的分布式系统,其序号范围为[0,N−1][0, N-1][0,N−1]。然后选取数据本身或可以代表数据特征的数据的一部分作为keykeykey,计算 hash(key)hash(key)hash(key)与节点数量NNN的模,该计算结果即为该数据的存储节点的序号。
- 该算法最大的优点是简单,但缺点是其也存在较严重的不足。如果分布式系统扩容或缩容,已经存储过的数据需要根据新的节点数量NNN进行数据迁移,否则用户根据 key 是无法再找到原来的数据的。生产中扩容一般采用翻倍扩容方式,以减少扩容时数据迁移的比例。
1.2.2 一致性哈希分区算法
-
一致性 hashhashhash 算法通过一个叫作一致性hashhashhash环的数据结构实现。这个环的起点是 000,终点是 232−12^32-1232−1,并且起点与终点重合。环中间的整数按逆/顺时针分布,故这个环的整数分布范围是[0,232−1][0, 2^32-1][0,232−1]。
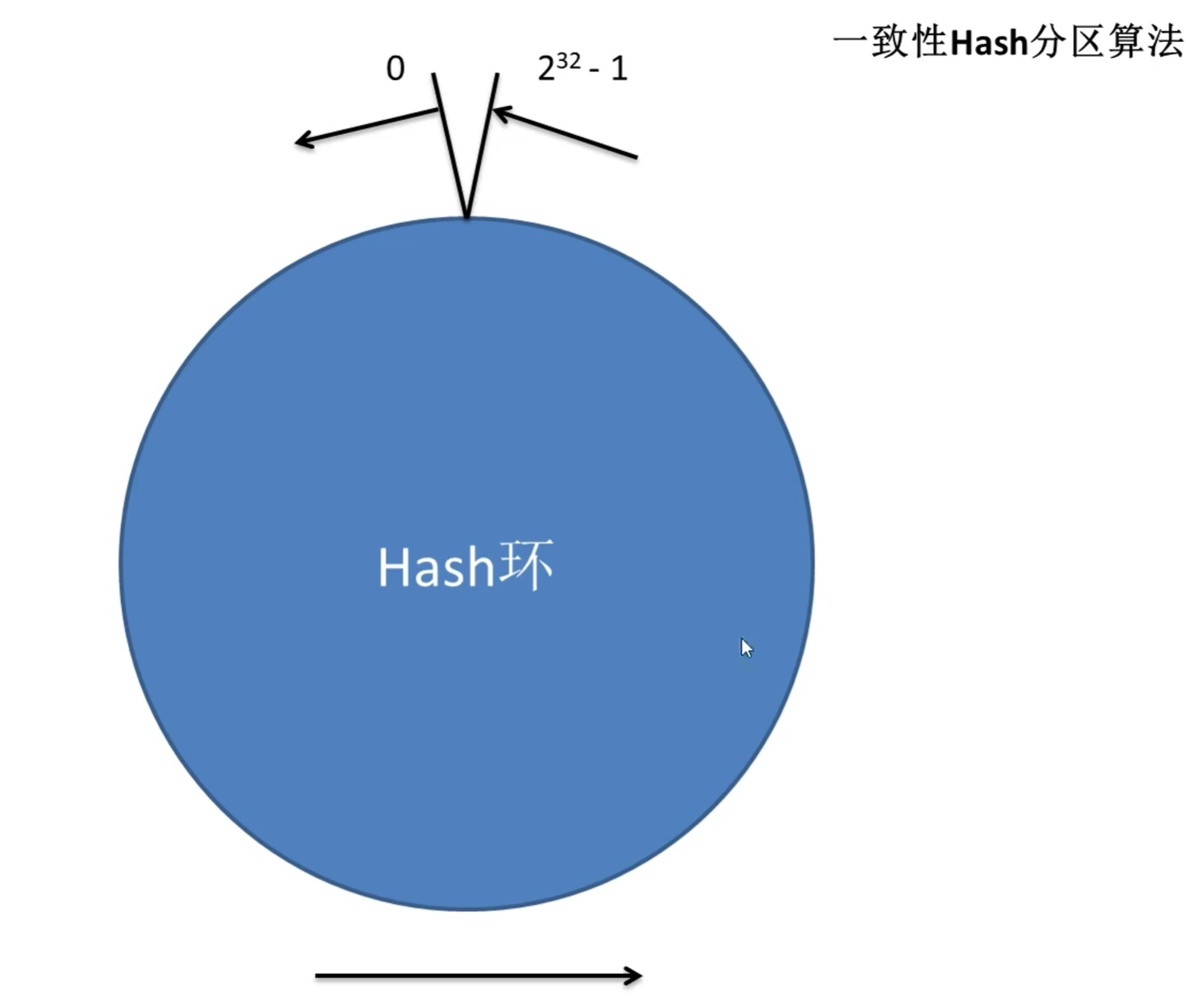
-
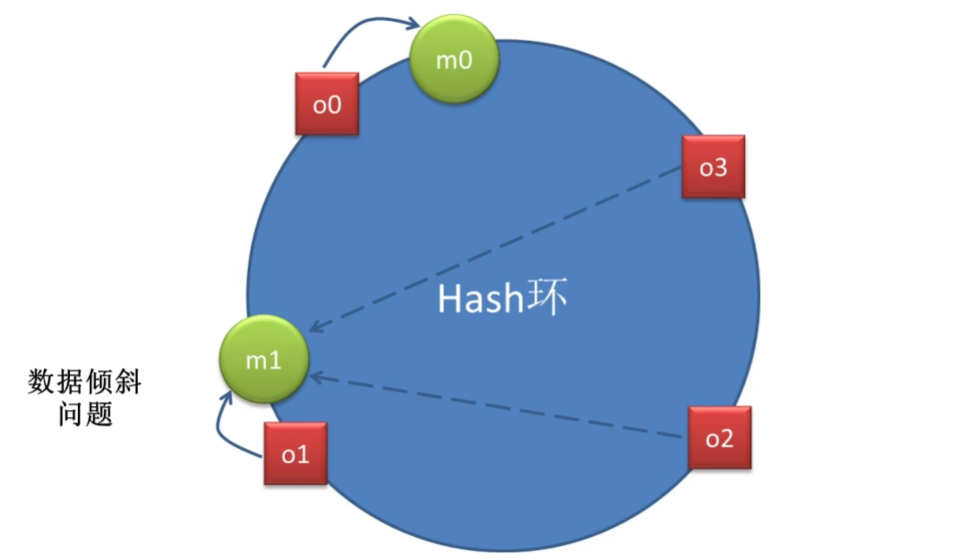
上图中存在四个对象 o1、o2、o3、o4o1、o2、o3、o4o1、o2、o3、o4,分别代表四个待分配的数据,红色方块是这四个数据的 hash(o)hash(o)hash(o)在 Hash 环中的落点。同时,图上还存在三个节点 m0、m1、m2m_0、m_1、m_2m0、m1、m2的主机结点,绿色圆圈是这三节点的 hash(m)hash(m)hash(m)在 Hash 环中的落点。
-
现在要为数据分配其要存储的节点。该数据对象的 hash(o) 按照逆/顺时针方向距离哪个节点的 hash(m)最近,就将该数据存储在哪个节点。这样就会形成上图所示的分配结果。
-
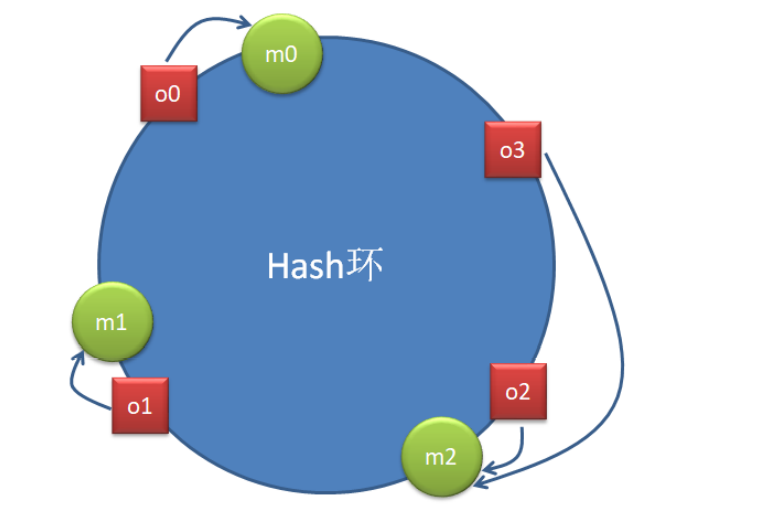
该算法的优点是:节点的扩容与缩容,仅对按照逆/顺时针方向距离该节点最近的节点有影响,对其它节点无影响。
- 如下图:在原来的基础上添加m3m_3m3的主机结点,对o3o_3o3的数据进行迁移
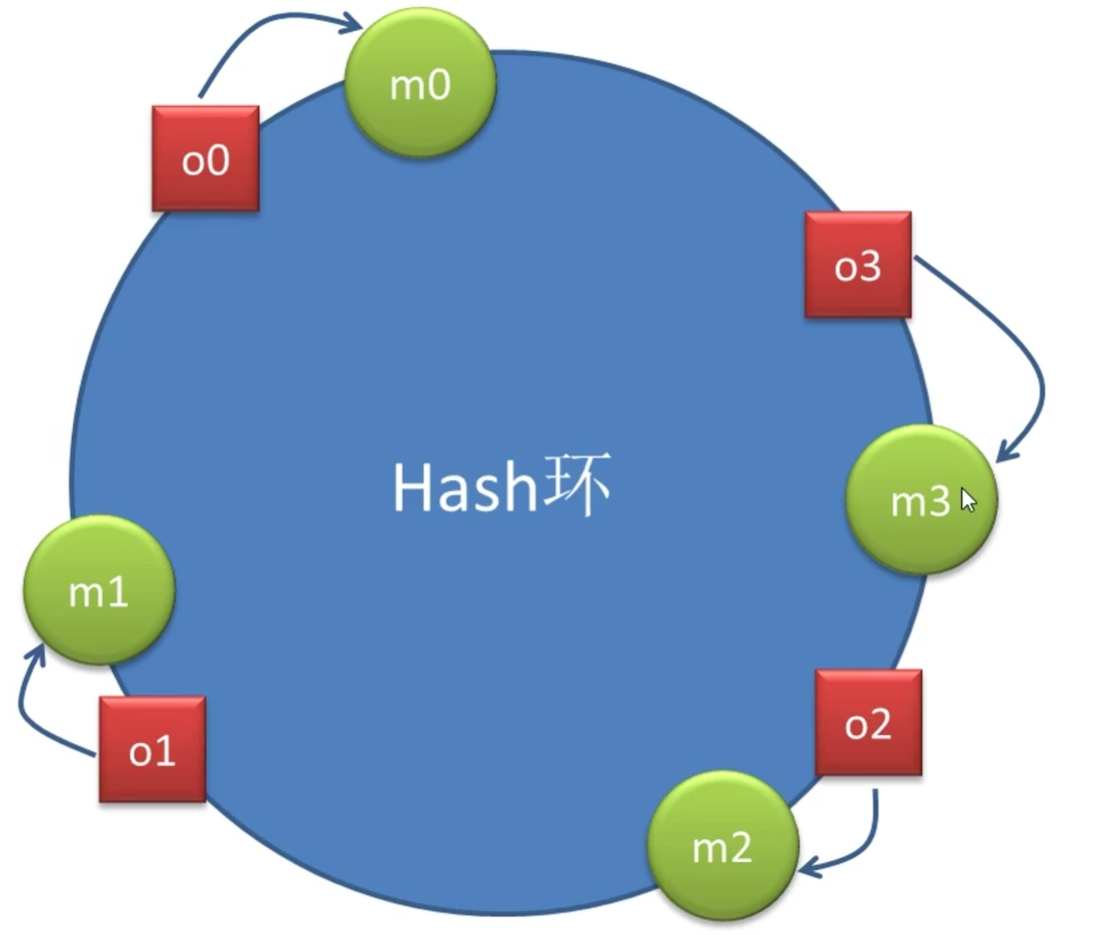
- 如下图:在原来的基础上添加m3m_3m3的主机结点,对o3o_3o3的数据进行迁移
-
当节点数量较少时,容易形成数据倾斜问题,且节点变化影响的节点数量占比较大,即影响的数据量较大。所以该方式不适合数据节点较少的场景。
1.2.3 虚拟槽分区算法
- 该算法首先虚拟出一个固定数量的整数集合,该集合中的每个整数称为一个 slot 槽。这个槽的数量一般是远远大于节点数量的,然后再将所有 slot 槽平均映射到各个节点之上。Redis 分布式系统中共虚拟了 163841638416384 个 slot 槽,其范围为[0,16383][0, 16383][0,16383]。
- 例如,假设共有 3 个节点,那么 slot 槽与节点间的映射关系如下图所示:

- 而数据只与 slot 槽有关系,与节点没有直接关系。数据只通过其 key 的 hash(key)映射到slot 槽:slot=hash(key)%slotNumsslot=hash(key) \% slotNumsslot=hash(key)%slotNums。该算法的一个优点,解耦了数据与节点,客户端无需维护节点,只需维护与 slot 槽的关系即可。
- Redis 数据分区采用的就是该算法。其计算槽点的公式为:slot=CRC16(key)%16384slot = CRC16(key) \% 16384slot=CRC16(key)%16384。CRC16()CRC16()CRC16()是一种带有校验功能的、具有良好分散功能的、特殊的 hash 算法函数。
- 其实 Redis中计算槽点的公式不是上面的那个,而是:KaTeX parse error: Expected 'EOF', got '&' at position 19: …t = CRC16(key) &̲16383。若要计算 a%ba\%ba%b,如果 b 是 2 的整数次幂,那么 KaTeX parse error: Expected 'EOF', got '&' at position 12: a \% b = a &̲ (b-1)。
二 分布式系统环境搭建与运行
2.1 系统搭建
- 这部分的内容,作者主要讲解操作和原理,所以对代码及操作的的实际操作结果展示内容会减少,但主要的步骤还是会保留下来!
2.1.1 系统架构
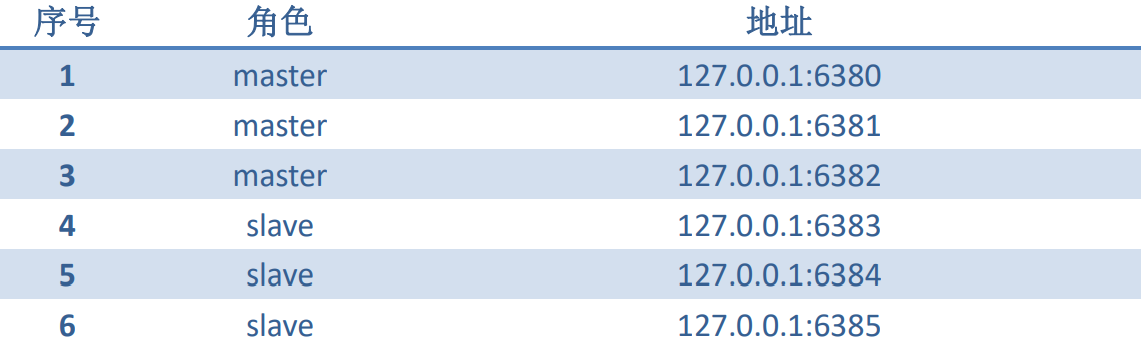
- 要搭建的 Redis 分布式系统由 6 个节点构成,这 6 个节点的地址及角色分别如下表所示。一个 master 配备一个 slave,master 与 slave 的配对关系,在系统搭建成功后会自动分配。
2.1.2 删除持久化文件
- 先将之前“Redis 主从集群”中在 Redis 安装目录下生成的 RDB 持久化文件
dump638*.conf与AOF持久化文件删除。因为Redis分布式系统要求创建在一个空的数据库之上。注意,AOF持久化文件全部在appendonlydir目录中。
# 在目录redis下操作
rm -rf dump638*.rdb appendonlydir
2.1.3 创建目录
- 在 Redis 安装目录中 mkdir 一个新的目录 cluster-dis,用作分布式系统的工作目录。
# 在目录redis下操作
mkdir cluster-dis
2.1.4 复制 2 个配置文件
- 将 cluster 目录中的
redis.conf与redis6380.conf文件复制到 cluster-dis 目录
# 在cluster-dis的操作命令
cp ../cluster/redisconf ./
cp ../cluster/redis6380.conf ./
2.1.5 修改 redis.conf
- 对于 redis.conf 配置文件,主要涉及到以下三个四个属性:
- dir
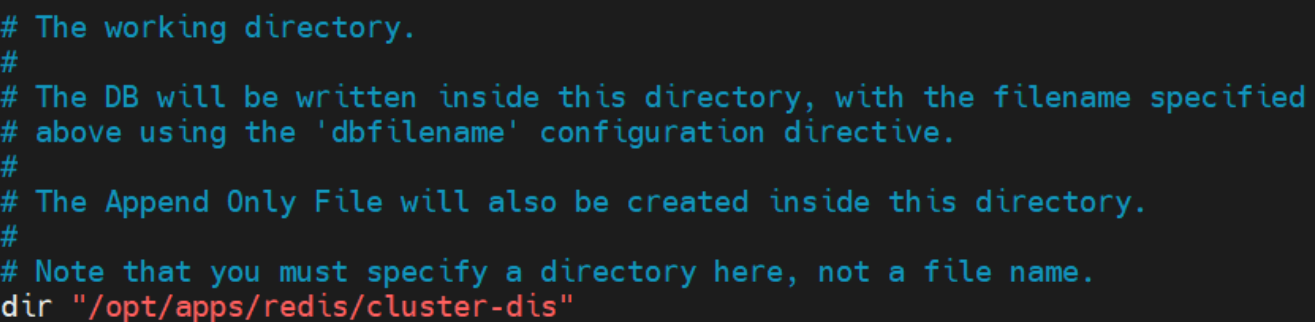
- 指定工作目录为前面创建的
cluster-dis目录。持久化文件、节点配置文件将来都会在工作目录中自动生成。
- 指定工作目录为前面创建的
- cluster-enabled

- 该属性用于开启 Redis 的集群模式
- cluster-config-file

- 该属性用于指定“集群节点”的配置文件。该文件会在第一次节点启动时自动生成,其生成的路径是在 dir 属性指定的工作目录中。在集群节点信息发生变化后(如节点下线、故障转移等),节点会自动将集群状态信息保存到该配置文件中。
- cluster-node-timeout

- 用于指定“集群节点”间通信的超时时间阈值,单位毫秒
2.1.6 修改 redis6380.conf
include redis.conf
pidfile /var/run/redis_6380.pid
port 6380
dbfilename dump6380.rdb
appendfilename appendonly6380.aof
replica-priority 90
cluster-config-file nodes-6380.conf
2.1.7 复制 5 个配置文件
- 使用 redis6380.conf 复制出 5 个配置文件
redis6381.conf、redis6382.conf、redis6383.conf、redis6384.conf、redis6385.conf
cp redis6380.conf redis6381.conf
cp redis6380.conf redis6382.conf
cp redis6380.conf redis6383.conf
cp redis6380.conf redis6384.conf
cp redis6380.conf redis6385.conf
2.1.8 修改 5 个配置文件
- 修改 5 个配置文件
redis6381.conf、redis6382.conf、redis6383.conf、redis6384.conf、redis6385.conf的内容,将其中所有涉及的端口号全部替换为当前文件名称中的端口号。
2.2 系统启动与关闭
2.2.1 启动节点
- 第一种方式:手动启动
- 启动所有 Redis 节点
redis-server redis6380.conf redis-server redis6381.conf redis-server redis6382.conf redis-server redis6383.conf redis-server redis6384.conf redis-server redis6385.conf - 第二种:编写脚本文件启动【该方法在伪集群中使用方便,真实生产环境不适用】
1. 在cluster-dis中,创建文件start-redis-cluster.shvim start-redis-cluster.sh2. 编写内容如下#!/bin/bash rm -rf dump638*.rdb rm -rf appendonlydir rm -rf nodes-638*.conf redis-server redis6380.conf redis-server redis6381.conf redis-server redis6382.conf redis-server redis6383.conf redis-server redis6384.conf redis-server redis6385.conf- 修改文件的权限
chmod 755 start-redis-cluster.sh- 运行文件
./start-redis-cluster.sh
2.2.2 创建分布式系统
- 6 个节点启动后,它们仍是 6 个独立的 Redis,通过
redis-cli --cluster create命令可将 6个节点创建了一个分布式系统。

- 该命令用于将指定的 6 个节点连接为一个分布式系统。
--cluster replicas 1指定每个master 会带有一个slave作为副本。
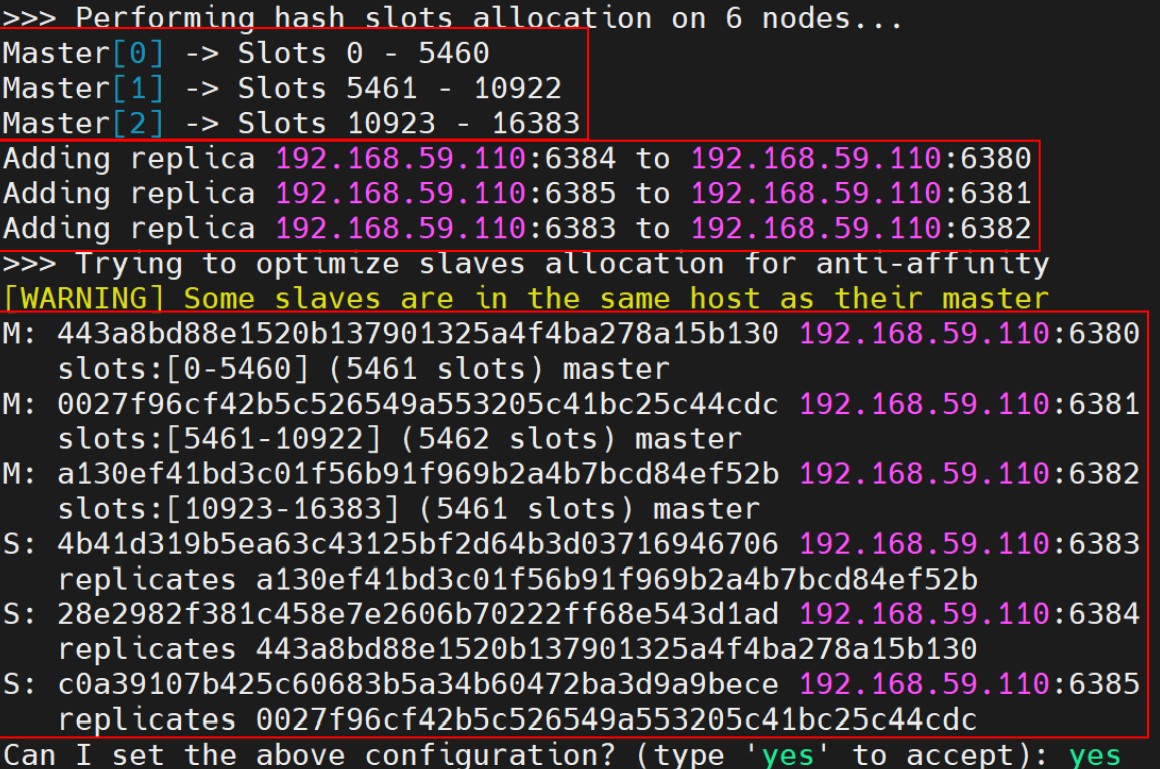
- 输入 yes 后回车,系统就会将以上显示的动态配置信息真正的应用到节点上,然后就可可看到如下日志
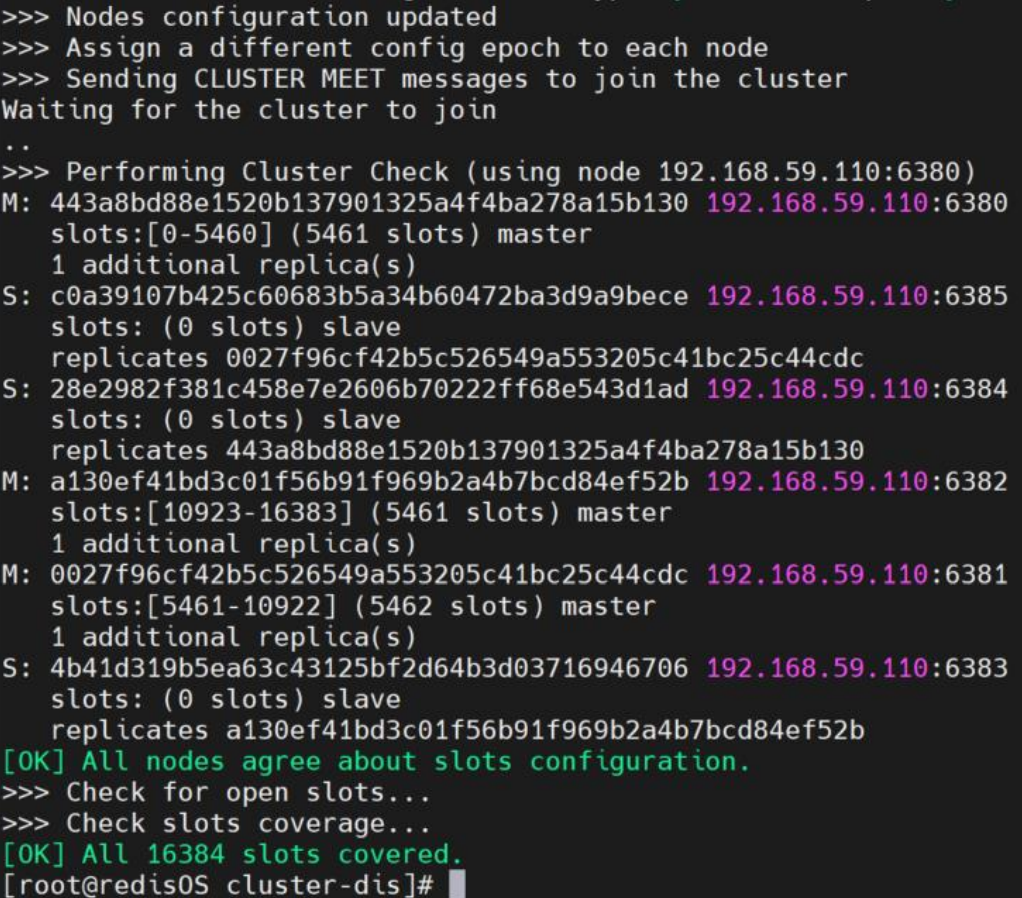
2.2.3 测试系统
- 通过
cluster nodes命令可以查看到系统中各节点的关系及连接情况。能看到每个节点给出 connected,就说明分布式系统已经成功搭建。
redis-cli -c -p 6380 cluster nodes
- 对于客户端连接命令 redis-cli,需要注意两点:
- redis-cli 带有-c 参数,表示这是要连接一个“集群”,而非是一个节点。
- 端口号可以使用 6 个中的任意一个。
2.2.4 关闭系统
- 对于分布式系统的关闭,只需将各个节点 shutdown 即可
- 方法一:手动关闭
redis-cli -p 6380 shutdown
redis-cli -p 6381 shutdown
redis-cli -p 6382 shutdown
redis-cli -p 6383 shutdown
redis-cli -p 6384 shutdown
redis-cli -p 6385 shutdown
- 方法二:配置文件关闭
- 创建执行文件
shutdown-redis-cluster.sh - 编写一下内容
#!/bin/bash redis-cli -p 6380 shutdown redis-cli -p 6381 shutdown redis-cli -p 6382 shutdown redis-cli -p 6383 shutdown redis-cli -p 6384 shutdown redis-cli -p 6385 shutdown # 查看关闭的效果指令 ps aux|grep redis- 修改文件权限
chmode 755 shutdown-redis-cluster.sh - 创建执行文件
三 集群操作
3.1 连接集群
- 与之前单机连接相比的唯一区别就是增加了参数-c。
redis-cli -c -p 6380
3.2 写入数据
3.2.1 key 单个写入&批量操作
- 无论 value 类型为 String 还是 List、Set 等集合类型,只要写入时操作的是一个 key,那么在分布式系统中就没有问题。
- 对一次写入多个 key 的操作,由于多个 key 会计算出多个 slot,多个 slot 可能会对应多个节点。而由于一次只能写入一个节点,所以该操作会报错。系统提供了一种对批量 key 的操作方案,为这些 key 指定一个统一的 group,让这个 group 作为计算 slot 的唯一值。
- 如:
mset name{emp} ming game{emp} kissking
3.3 集群查询
3.3.1 查询 key 的 slot
- 通过
cluster keyslot可以查询指定 key 的slotcluster keyslot xxx
3.3.2 查询 slot 中 key 的数量
- 通过
cluster countkeysinslot命令可以查看到指定slot所包含的key的个数
cluster countkeysinslot xxx
3.3.3 查询 slot 中的 key
- 通过
cluster getkeysinslot命令可以查看到指定 slot 所包含的key
cluster getkeysinslot xxx num
3.4 故障转移
3.4.1 故障转移
- 分布式系统中的某个
master如果出现宕机,那么其相应的slave就会自动晋升为master。如果原master又重新启动了,那么原master会自动变为新master的slave。
3.4.2 全覆盖需求
- 如果某 slot 范围对应节点的 master 与 slave 全部宕机,那么整个分布式系统是否还可以对外提供读服务,就取决于属性
cluster-require-full-coverage的设置。
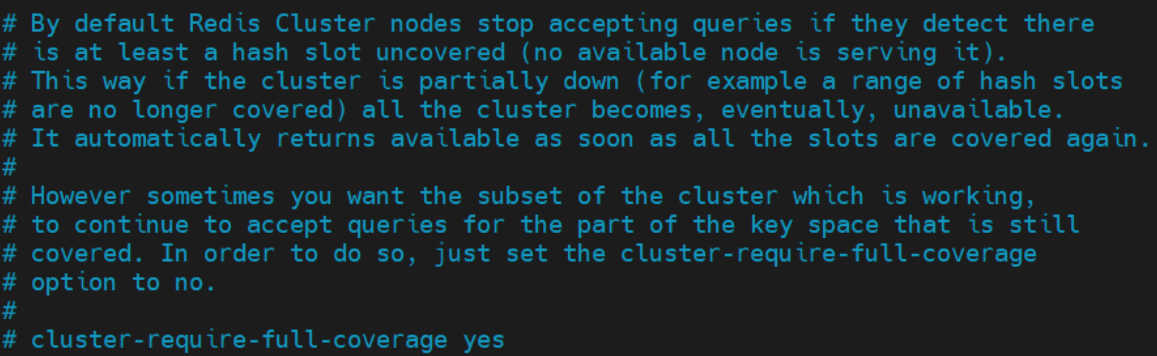
- 该属性有两种取值:
- yes:默认值。要求所有 slot 节点必须全覆盖的情况下系统才能运行。
- no:slot 节点不全的情况下系统也可以提供查询服务。
四 分布式系统的限制
- Redis 的分布式系统存在一些使用限制:
- 仅支持 0 号数据库
- 批量 key 操作支持有限:需要指定GROUP不能跨槽存放
- 分区仅限于 key:即使VALUE是集合,也不能存放到不同的机器上。
- 事务支持有限:在一个主机上有作用,槽点分到不同主机上不起作用。
- 不支持分级管理:不支持分极管理,只有
master和slave
上一篇:四种常见的异步请求方式
下一篇:操作系统重难点笔记
相关内容
热门资讯
iPhone手机怎么玩安卓系统...
你有没有想过,你的iPhone手机竟然也能玩安卓系统?没错,就是那个一直以来让你觉得遥不可及的安卓世...
平板删安卓系统更新不了,原因及...
最近是不是你也遇到了这样的烦恼?平板电脑上的安卓系统更新不了,是不是让你头疼得要命?别急,今天就来给...
苹果组装机安卓系统卡,卡顿背后...
你有没有发现,最近用苹果手机的时候,有时候系统有点卡呢?这可真是让人头疼啊!你知道吗,其实这背后还有...
安卓系统原生浏览器,功能与体验...
你有没有发现,每次打开手机,那个小小的浏览器窗口总是默默无闻地在那里,陪你浏览网页、搜索信息、看视频...
安卓机如何上苹果系统,跨平台体...
你是不是也和我一样,对安卓机和苹果系统之间的切换充满了好奇?想象你的安卓手机里装满了各种应用,而苹果...
安卓导入系统证书失败,原因分析...
最近在使用安卓手机的时候,你是不是也遇到了一个让人头疼的问题——导入系统证书失败?别急,今天就来给你...
安卓原生系统有哪些手机,盘点搭...
你有没有想过,为什么有些手机用起来就是那么流畅,那么顺心呢?这背后可大有学问哦!今天,就让我带你一起...
安卓系统关机了怎么定位,安卓系...
手机突然关机了,是不是有点慌张呢?别担心,今天就来教你一招,让你的安卓手机即使关机了,也能轻松定位到...
安卓系统游戏加速器,畅享无延迟...
你有没有发现,手机游戏越来越好玩了?不过,有时候游戏体验可能并不那么顺畅,是不是因为手机性能不够强大...
安卓4系统天气功能,尽在掌握
安卓4系统天气功能大揭秘在当今这个数字化的世界里,手机已经不仅仅是一个通信工具,它更是一个集成了各种...
安卓系统如何玩碧蓝幻想,攻略与...
你有没有想过,在安卓系统上玩《碧蓝幻想》竟然可以这么酷炫?没错,就是那个让你沉迷其中的二次元大作!今...
安卓系统搜不到图朵,图朵生成之...
最近是不是你也遇到了这样的烦恼?手机里明明有那么多美美的图片,但是用安卓系统搜索的时候,却怎么也找不...
魁族8刷安卓系统,系统升级后的...
哇,你知道吗?最近在安卓系统圈子里,有一个话题可是引起了不小的轰动,那就是魁族8刷安卓系统。你是不是...
微信正版安装安卓系统,畅享沟通...
你有没有想过,你的微信是不是正版安装的安卓系统呢?这可不是一个小问题哦,它关系到你的微信使用体验和隐...
电视能刷安卓系统吗,电视也能刷...
电视能刷安卓系统吗?揭秘智能电视的无限可能想象你家的电视不再只是用来观看节目的工具,而是变成了一个功...
安卓系统开通通知功能,畅享智能...
你知道吗?最近安卓系统更新后,新增了一个超级实用的功能——开通通知功能!这可是个大喜事,让咱们的生活...
苹果系统安卓爱思助手,系统兼容...
你有没有发现,手机的世界里,苹果系统和安卓系统就像是一对欢喜冤家,总是各有各的粉丝,各有各的拥趸。而...
安卓系统占用很大内存,揭秘内存...
手机里的安卓系统是不是让你感觉内存不够用,就像你的房间堆满了杂物,总是找不到地方放新东西?别急,今天...
安卓系统p30,安卓系统下的摄...
你有没有发现,最近安卓系统P30在手机圈里可是火得一塌糊涂呢!这不,我就来给你好好扒一扒这款手机的那...
siri被安卓系统进入了,智能...
你知道吗?最近科技圈可是炸开了锅,因为一个大家伙——Siri,竟然悄悄地溜进了安卓系统!这可不是什么...