
特征锦囊:使用过滤法(Filter)对高维特征进行降维

今日锦囊
特征锦囊:使用过滤法(Filter)对高维特征进行降维
🚅 Index
01 方差筛选
02 缺失率筛选
03 同质性筛选
04 IV值筛选
05 PSI筛选
06 相关性/共线性筛选
07 卡方检验
特征选择中的Filter法是根据特征与特征之间的关系、特征与目标之间的关系来计算相关指标,从而量化特征效果来过滤低效或者不重要的特征。它是先对数据集进行特征选择,然后再训练模型,而且特征选择的过程与后续的模型训练无关。
这里我们日常中常用的特征筛选方法主要有:方差筛选、缺失率筛选、同质性筛选、IV值筛选、PSI筛选、相关性/共线性筛选以及卡方检验等。
01 方差筛选
方差一般是用来描述数据波动的,如果计算出来的指标值比较小的话,一般会认为数据之间区分度不大,但是实际工作中我们也不能直接拿来用,因为每个指标的量纲都不同,无法做直接的比较。而且怎么说,有的时候即便方差小,但指标确实可以识别出坏人。因此还是需要结合区分度来综合判断才可以过滤特征。
02 缺失率筛选
缺失值的话也是一个比较简单过滤特征的方法,如果缺失值过高(比如80%+)一般会在风控评分卡建模这块我们会直接选择过滤特征,但如果是反欺诈场景的话就不能简单地就过滤了,说不定有用的信息就藏在了这个特征里了。
03 同质性筛选
同质性的意思就是特征里的具体某个特征值的占比过高的说法,就是说这个特征的信息都长得差不多,这样子的特征其实和缺失率超过80%有一点像,通常情况下都不太会用这个特征了。
04 IV值筛选
关于IV的原理和实现,先前专栏里的一篇文章《风控ML[3] | 风控建模的WOE与IV》有专门说过,感兴趣的可以回去翻一下哈。
IV全称是Information Value,即信息值,这个指标是用来衡量特征的预测能力强弱的,而IV又是通过WOE来算的,WOE是通过类别变量来计算的,如果是连续性变量需要额外考虑分箱、离散化的问题,关于连续变量分箱方法的原理和实现可以看之前的两篇文章。
《风控ML[10] | 风控建模中的自动分箱的方法有哪些》
《风控ML[11] | 3种连续变量分箱方法的代码分享》
一般来说IV值<0.02,意味着特征没有什么预测力,可以直接过滤。这里涉及的代码就比较多了,就不贴过来了,有需要的同学可以自行移步到 风控ML[11] 这边看。
05 PSI筛选
PSI全称叫做“Population Stability Index” ,中文翻译是群体稳定性指标,从风控应用的角度理解就是分组的测试与跨时间稳定性指标。
在我们建模的时候,数据(变量或者模型分)的分组占比分布是我们的期望值,也就是我们希望在测试数据集里以及未来的数据集里,也能够展示出相似的分组分布,我们称之为稳定。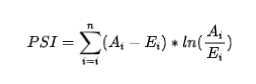 PSI值没有指定的值域,我们需要知道的是值越小越稳定,一般在风控中会拿0.25来作为筛选阈值,即PSI>0.25我们就认定这个变量或者模型不稳定了,这样子的变量一般来说也是不会直接拿来建模,不然模型效果会不太稳定。
PSI值没有指定的值域,我们需要知道的是值越小越稳定,一般在风控中会拿0.25来作为筛选阈值,即PSI>0.25我们就认定这个变量或者模型不稳定了,这样子的变量一般来说也是不会直接拿来建模,不然模型效果会不太稳定。
更多关于PSI的原理解释和代码实现,可以移步到《风控ML[13] | 特征稳定性指标PSI的原理与代码分享》来进行详细了解哈。
06 相关性/共线性筛选
关于这种特征筛选方法,有两种理解的切入角度与应用:
第一就是拿X特征与目标Y特征之间计算指标,然后用来过滤与目标Y特征没有关系的X特征,这种我们常叫相关性筛选;
第二就是拿不同的X特征来计算之间的共线性,入模型前只保留相关独立的特征,这种我们常叫共线性筛选。这种一般对于LR来说不能同时进入模型的,必须剔除其中一个,但对于集成树模型(比如XGBoost、GBDT等)来说倒没多大关系,因为前者模型需要有较强的稳定性和可解释性,共线性的特征会让模型不太好解释,而后者模型对解释性要求不高,所以不筛选也问题不大。
以上说的相关性/共线性筛选,我们一般会用Pearson Correlation,即我们常说的皮尔逊相关系数,该衡量方法就是可以计算出两个特征之间相关性大小,阈值在[-1, 1]之间,负数代表负相关,正数代表正相关,0代表没有线性关系。
我们在调spicy里的pearson相关系数的API后会发现它返回了两个值,第一个是相关性系数,第二个是相关系数显著性p。简单解释下,相关性系数就是上一段说的那样子值域在-1到1之间,但是我们不能直接用这个指标,我们还要结合相关系数显著性水平来使用,我们要保证相关系数显著,才能保证计算的相关性系数有统计学意义。
而什么情况下有统计学意义呢?一般就是取值小于0.01。
07 卡方检验
卡方检验属于非参数检验,由于非参检验不存在具体参数和总结正态分布的假设,所以有的时候也被称为自由分布检验。它的原理就是检验统计量来对比期望结果与实际结果的差异,最终根据显著性水平确定卡方值,从而来判断事情发生的概率。
公式如下: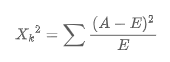 其中,A是实际频数,E是期望频数。
其中,A是实际频数,E是期望频数。
说白了和上一小节说的Pearson相关系数有点类似的效果,也是有两种应用方向。
第一就是拿X特征与目标Y特征之间计算指标,卡方检验的原假设是X特征与目标Y特征之间是独立的,卡方值越大就说明两者之间的差异越大,也就是相关性越高,对于我们预测更加有效果。
第二就是拿不同的X特征来计算之间的共线性,找到相互之间有相关性的特征,然后在入模型之前做好过滤工作。
下面的例子我们调用sklearn里的SelectKBest来选择K个评分最高的特征,这一步可以在我们在我们最开始做特征筛选的时候用,把一些末尾的特征进行直接过滤。
📖 References
[1] MLK | 机器学习的降维"打击"
https://zhuanlan.zhihu.com/p/77340182
[2] 风控建模系列之数据特征筛选方法总结
https://zhuanlan.zhihu.com/p/524582723
[3] 卡方检验与特征选择
https://zhuanlan.zhihu.com/p/432912922
[4] sklearn 数据降维快速入门2 - SelectKBest + 卡方检验/方差分析
https://zhuanlan.zhihu.com/p/438598029
[5] 特征工程:特征降维
https://blog.csdn.net/yeshang_lady/article/details/118159218
[6] 机器学习(七):数据预处理--特征选择-L1、L2正则化
https://zhuanlan.zhihu.com/p/129782115
[7] 金融风控建模评分卡系列:机器学习特征选择方法
https://zhuanlan.zhihu.com/p/522255272?utm_medium=social&utm_oi=860607872822833152

广而告之

PICK ME
朋友们,阿Sam这边也开通了小红书账号,也会定期发布一些机器学习、风控挖掘、特征工程等相关工程(几乎日更哦),欢迎大家也关注关注,哈哈~

