
PPQ库中KLD算法实现代码解析
创始人
2024-05-29 12:13:06
0次
PPQ量化工具库KLD算法解析
- 前言
- PPQ算法实现
- NVIDIA的PPT中KLD算法流程
- KLD算法PPQ实现版本
- PPQ与NVIDIA的区别:
前言
这是对PPQ库中KLD算法实现代码解析,关于PPQ库安装与使用详情见专栏上一篇博客。
PPQ算法实现
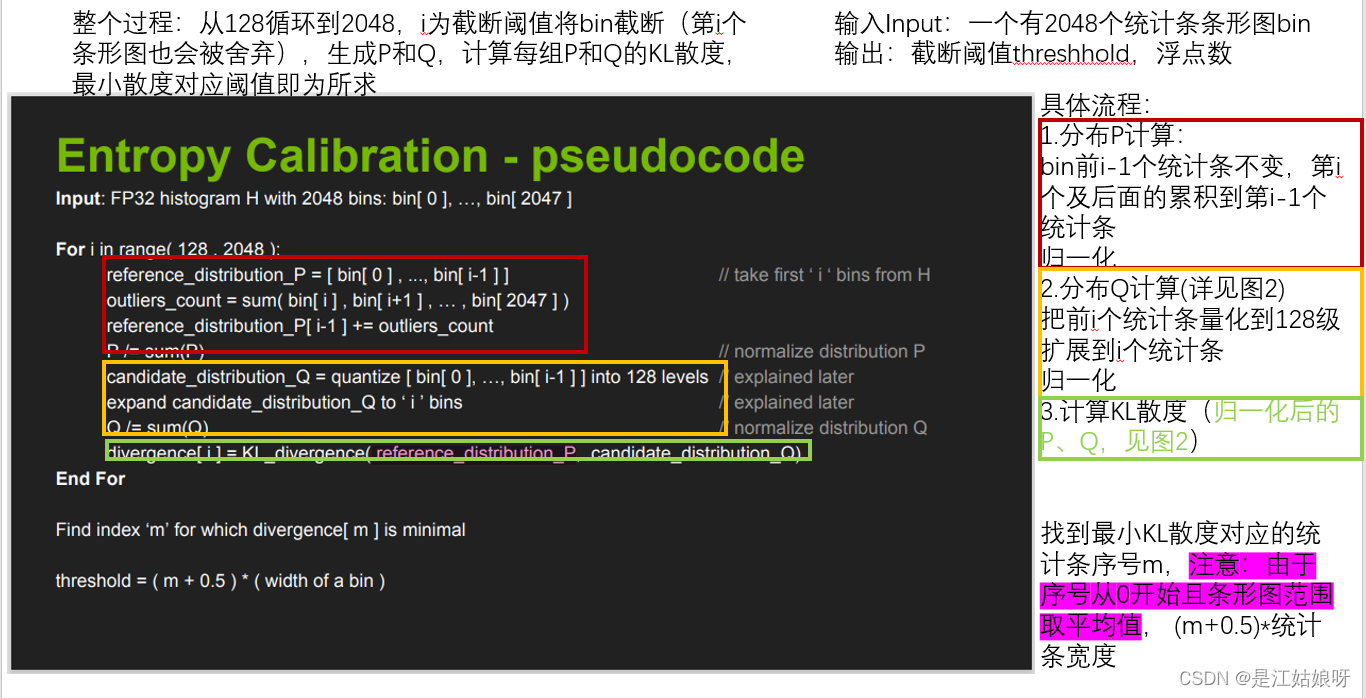
nvidia发布的PPT:8-bit Inference with TensorRT,百度可下载。下两图是KLD算法的实现伪代码:


下图是PPQ算法的实现过程:见https://github.com/openppl-public/ppq/blob/master/ppq/quantization/observer/range.py
def hist_to_scale_offset(self, histogram: torch.Tensor, hist_bins: int, hist_scale: float,config: TensorQuantizationConfig, computing_device: str = OBSERVER_KL_COMPUTING_DEVICE,scale_threshold: float=OBSERVER_MIN_SCALE) -> Tuple[float, int]:"""PPQ core quant parameter computing method - Histogram to scale & offsetWith a pre-defined histogram,this function will automatically search best clip valueto minimize KL divergence between quantized result and fp32 input.only work for per-tensor symmetrical quantization policy for now.see also https://on-demand.gputechconf.com/gtc/2017/presentation/s7310-8-bit-inference-with-tensorrt.pdfArgs:histogram (torch.Tensor): histogram records activation's statistics.hist_bins (int): how many bins are included in histogram(also known as histogram length)hist_scale (float): histogram step size. it can be solved by histogram.max_val / histogram.binsconfig (TensorQuantizationConfig): quantization config.computing_device (str, optional): computing device. Defaults to 'cpu'.Raises:ValueError: given quantization config is invalid.Returns:Tuple[float, int]: scale(fp32) and offset(int)."""if config.policy.has_property(QuantizationProperty.ASYMMETRICAL):raise PermissionError('KL observer is not designed for ASYMMETRICAL quantization')if OBSERVER_MIN_SCALE_MANUL_OVERRIDE in config.detail:scale_threshold = config.detail[OBSERVER_MIN_SCALE_MANUL_OVERRIDE]# move histogram to cpu, speedup computation.histogram = histogram.to(computing_device).float()# compute symmtrical kl-divergence.# Here is a simple example: reference distribution P consisting of 8 bins, we want to quantize into 2 bins:# P = [ 1, 0, 2, 3, 5, 3, 1, 7]# we merge into 2 bins (8 / 2 = 4 consecutive bins are merged into one bin)# [1 + 0 + 2 + 3 , 5 + 3 + 1 + 7] = [6, 16]# then proportionally expand back to 8 bins, we preserve empty bins from the original distribution P:# Q = [ 6/3, 0, 6/3, 6/3, 16/4, 16/4, 16/4, 16/4] = [ 2, 0, 2, 2, 4, 4, 4, 4]# now we should normalize both distributions, after that we can compute KL_divergence# P /= sum(P) Q /= sum(Q)# result = KL_divergence(P, Q)# see also# https://github.com/NVIDIA/TensorRT/blob/3835424af081db4dc8cfa3ff3c9f4a8b89844421/tools/pytorch-quantization/pytorch_quantization/calib/histogram.py#L147losses, quant_bins = [], 2 ** (config.num_of_bits - 1)# following code is curcial, do not movehistogram[: int(hist_bins * .002)] = 0histogram[int(hist_bins * .002)] = 1hist_sum = torch.sum(histogram)for bin_range in range(quant_bins, hist_bins + quant_bins - 1, quant_bins):p_hist = torch.zeros(size=(bin_range, ), dtype=torch.float, device=computing_device)p_hist[: bin_range].copy_(histogram[: bin_range])p_hist[bin_range - 1] += torch.sum(histogram[bin_range: ])p_hist = p_hist / hist_sumexpand_ratio = int(bin_range / quant_bins)q_hist = histogram[: bin_range].clone()q_hist = q_hist.reshape((quant_bins, expand_ratio))positive_map = q_hist > 0positive_cnt = positive_map.sum(axis=1, keepdim=True)positive_cnt[positive_cnt == 0] = 1q_hist = torch.div(q_hist.sum(axis=1, keepdim=True), positive_cnt)q_hist = q_hist.repeat([1, expand_ratio])q_hist = q_hist * positive_mapq_hist = q_hist / torch.sum(q_hist)q_hist = q_hist.flatten()losses.append({'kl': torch_KL_divergence(p_hist, q_hist),'bin_range': bin_range})best_bin_range = sorted(losses, key=lambda x: x['kl'])[0]['bin_range']scale, offset = (best_bin_range / self._hist_bins) * hist_scale * (self._hist_bins / quant_bins), 0if scale < scale_threshold and OBSERVER_WARNING: ppq_warning('Numeric instability detected: ''ppq find there is a scale value < 1e-7, ''which probably cause numeric underflow in further computation.')scale = max(scale, scale_threshold)if config.policy.has_property(QuantizationProperty.POWER_OF_2):scale = ppq_round_to_power_of_2(scale, policy=RoundingPolicy.ROUND_HALF_UP)return scale, offset
NVIDIA的PPT中KLD算法流程
整个过程:从128循环到2048,i为截断阈值将bin截断(第i个条形图也会被舍弃),生成P和Q,计算每组P和Q的KL散度,最小散度对应阈值即为所求
输入Input:一个有2048个统计条条形图bin
输出:截断阈值threshhold,浮点数

KLD算法PPQ实现版本
算法流程:
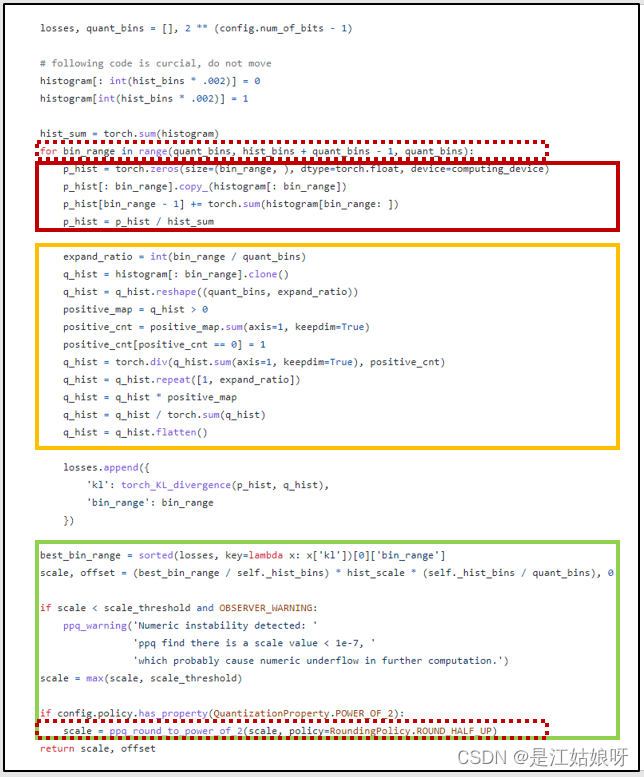
具体代码分析:

PPQ与NVIDIA的区别:
1.原始histogram条形图舍弃
NVIDIA是:不进行预处理
PPQ:前其千分之二置为零,第千分之二个条形置为1
2.for循环找截断阈值
NVIDIA是:for i in range(102,2048)
PPQ库是:for bin_range in range(quant_bins, hist_bins + quant_bins - 1, quant_bins):
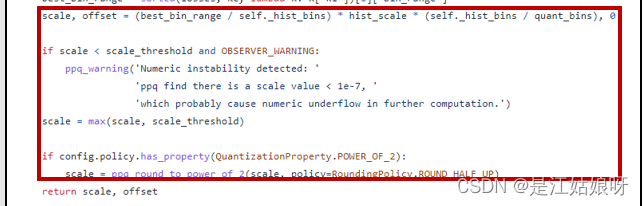
3.阈值m转为实际浮点数
NVIDIA是:threshold = ( m + 0.5 ) * ( width of a bin )
PPQ库是:
上一篇:函数式编程:Lambda 表达式
下一篇:中文代码86
相关内容
热门资讯
电视安卓系统哪个品牌好,哪家品...
你有没有想过,家里的电视是不是该升级换代了呢?现在市面上电视品牌琳琅满目,各种操作系统也是让人眼花缭...
安卓会员管理系统怎么用,提升服...
你有没有想过,手机里那些你爱不释手的APP,背后其实有个强大的会员管理系统在默默支持呢?没错,就是那...
安卓系统软件使用技巧,解锁软件...
你有没有发现,用安卓手机的时候,总有一些小技巧能让你玩得更溜?别小看了这些小细节,它们可是能让你的手...
安卓系统提示音替换
你知道吗?手机里那个时不时响起的提示音,有时候真的能让人心情大好,有时候又让人抓狂不已。今天,就让我...
安卓开机不了系统更新
手机突然开不了机,系统更新还卡在那里,这可真是让人头疼的问题啊!你是不是也遇到了这种情况?别急,今天...
安卓系统中微信视频,安卓系统下...
你有没有发现,现在用手机聊天,视频通话简直成了标配!尤其是咱们安卓系统的小伙伴们,微信视频功能更是用...
安卓系统是服务器,服务器端的智...
你知道吗?在科技的世界里,安卓系统可是个超级明星呢!它不仅仅是个手机操作系统,竟然还能成为服务器的得...
pc电脑安卓系统下载软件,轻松...
你有没有想过,你的PC电脑上安装了安卓系统,是不是瞬间觉得世界都大不一样了呢?没错,就是那种“一机在...
电影院购票系统安卓,便捷观影新...
你有没有想过,在繁忙的生活中,一部好电影就像是一剂强心针,能瞬间让你放松心情?而我今天要和你分享的,...
安卓系统可以写程序?
你有没有想过,安卓系统竟然也能写程序呢?没错,你没听错!这个我们日常使用的智能手机操作系统,竟然有着...
安卓系统架构书籍推荐,权威书籍...
你有没有想过,想要深入了解安卓系统架构,却不知道从何下手?别急,今天我就要给你推荐几本超级实用的书籍...
安卓系统看到的炸弹,技术解析与...
安卓系统看到的炸弹——揭秘手机中的隐形威胁在数字化时代,智能手机已经成为我们生活中不可或缺的一部分。...
鸿蒙系统有安卓文件,畅享多平台...
你知道吗?最近在科技圈里,有个大新闻可是闹得沸沸扬扬的,那就是鸿蒙系统竟然有了安卓文件!是不是觉得有...
宝马安卓车机系统切换,驾驭未来...
你有没有发现,现在的汽车越来越智能了?尤其是那些豪华品牌,比如宝马,它们的内饰里那个大屏幕,简直就像...
p30退回安卓系统
你有没有听说最近P30的用户们都在忙活一件大事?没错,就是他们的手机要退回安卓系统啦!这可不是一个简...
oppoa57安卓原生系统,原...
你有没有发现,最近OPPO A57这款手机在安卓原生系统上的表现真是让人眼前一亮呢?今天,就让我带你...
安卓系统输入法联想,安卓系统输...
你有没有发现,手机上的输入法真的是个神奇的小助手呢?尤其是安卓系统的输入法,简直就是智能生活的点睛之...
怎么进入安卓刷机系统,安卓刷机...
亲爱的手机控们,你是否曾对安卓手机的刷机系统充满好奇?想要解锁手机潜能,体验全新的系统魅力?别急,今...
安卓系统程序有病毒
你知道吗?在这个数字化时代,手机已经成了我们生活中不可或缺的好伙伴。但是,你知道吗?即使是安卓系统,...
奥迪中控安卓系统下载,畅享智能...
你有没有发现,现在汽车的中控系统越来越智能了?尤其是奥迪这种豪华品牌,他们的中控系统简直就是科技与艺...