
FewJoint few‑shot learning for joint dialogue understanding
FewJoint: few‑shot learning for joint dialogue understanding
摘要
在少样本环境下,意图识别与语义槽填充联合建模所面临的两大挑战:①样本数据的稀疏性增大了建模两个任务之间联系的难度。②在少样本环境下联合多任务学习的研究目前较少。本文提出FewJoint,这是首个FSL联合对话理解的基准。同时本篇工作提出了一个新的语料库,包含来自工业API59个不同的对话领域,以及一个简化FSL实验设置的代码平台。此外为解决少样本环境下性能不足导致两个子任务之间噪声共享,联合学习受干扰问题,作者通过使用显示意图信息来引导语义槽,同时提出一种新的信任门控机制来阻止低置信度意图信息。最后引入了一种基于爬行动物的元学习策略,以在未显示的少样本域中实现更好的泛化。
介绍

构建FSL基准的主要障碍之一是FSL具有特殊的评估范式:少样本模型通常首先在数据丰富的领域进行预训练,然后在不可见的领域进行测试。这样的评估范式通常需要很多不同的训练/测试领域来学习一般的先验知识并克服结果的随机性,这对NLP任务来说通常是很难的。
之前的NLP FSL工作通常从单个数据集构造伪域,将标签集分成几个子集。然后,对于每个标签子集,用相应的样本构建一个合成域。缺陷: 此类模拟通常会干扰样本的自然分布,因此可能无法很好地反映少样本DU的复杂性。
作者发现将意图识别与语义槽填充任务直接共享信息,可能会引入较多的噪声,并且会损害彼此的性能。为了解决此类负面共享问题,本篇工作使用显式意图信息来引导槽填充,并引入一种新的信任门控机制,以确保高质量的信息共享。具体地,信任门控机制利用意图预测的置信度来选择性地将意图信息共享给每个样本的槽填充任务。同时将基于Reptile的元学习策略引入少样本联合DU任务中使模型能够更好的训练和泛化。
相关工作
FSL的旨在识别只有少数标记样本的新类。
目前两个研究方向:①基于表示学习的方法(基于度量或基于相似性的方法)目标是设计一个好的特征提取器或训练策略,以从数据丰富的类中获得更好的可转移表示,从而使新的类可以被许多距离函数或分类器识别,例如余弦距离、欧氏距离等。
②基于优化的方法(基于元学习的方法)目标是获得良好的模型初始化,对于大量的FSL任务,学习任务不可知元学习器以加速元测试阶段的优化。
对话理解的一个流行解决方案是两个子任务的联合学习,ConProm[27](Hou Y, Lai Y, Chen C, et al (2021a) Learning to bridge metric spaces: Few-shot joint learning of intent detection and slot flling. In: Findings of ACL-IJCNLP, pp 3190–3200)首先探索了基于度量学习的联合DU方法,该方法将意图和槽位度量空间与交叉关注联系起来。为了捕获任务关系并减少错误分类,他们在桥接度量空间中对齐相关的跨任务标签,并强制分离不相关的标签。
有工作采用MAML来联合DU任务[5](Bhathiya HS, Thayasivam U (2020) Meta learning for few-shot joint intent detection and slot-flling. In: ICMLT, pp 86–92) 、[31](Krone J, Zhang Y, Diab M (2020) Learning to classify intents and slot labels given a handful of examples. In: Proc. of the 2nd Workshop on Natural Language Processing for Conversational AI),这可以为意图检测和槽位标记的联合模型学习更好的初始化参数,并可以将知识快速转移到其他领域的任务。
缺陷: 这些工作通过简单地在意图和槽位模型之间共享编码层来实现联合对话理解,这无法捕获明确的意图-槽位关系;同时这些方法往往受到MAML中基于二阶导数优化的高成本和不稳定性。[2](Antoniou A, Edwards H, Storkey A (2019) How to train your maml. In: Proc. of ICLR) 、[44](Nichol A, Achiam J, Schulman J (2018) On frst-order meta-learning algorithms. arXiv preprint arXiv:1803.02999)
随着少样本学习的发展,越来越多的新数据集[14]( Ding N, Xu G, Chen Y, et al (2021) Few-nerd: A few-shot named entity recognition dataset. In: Proc. of ACL-IJCNLP, pp 3198–3213)、泛化方法[57](Triantafllou E, Larochelle H, Zemel R, et al (2021) Learning a universal template for few-shot dataset generalization. In: ICML, pp 10,424–10,433)和基准[43](Mukherjee S, Liu X, Zheng G, et al (2021) Clues: Few-shot learning evaluation in natural language understanding. arXiv preprint arXiv:2111.02570)、[65](Xu L, Lu X, Yuan C, et al (2021) Fewclue: A chinese few-shot learning evaluation benchmark. arXiv preprint arXiv:2107.07498)、[74](Zheng Y, Zhou J, Qian Y, et al (2022) Fewnlu: Benchmarking state-of-the-art methods for few-shot natural language understanding. In: Proc. of ACL)有助于促进该领域的进一步研究。
问题定义
定义短语 x=(x1,x2,…,xn),对应的语义架构为 y=(c,s),其中 c 是短语对于的意图标签, s是语义槽标签序列s=(s1,s2,…,sn,),A域 D={(x(i),y(i))}Ni=1是一组(x,y)集合对。对于每一组域都有一个相应的特定于域的标签集ζD。
在少样本学习场景中,模型首先在一组源域上进行训练{D1,D2,…},在另一组不可见的目标域{D’1,D’2,…}上进行评估。目标域D’j上通常只包含少数标记的例子,称之为支持集S={(x(i),y(i))}Ni=1,对于N个标签(N-shot)中的每一个,S集中通常包括K个示例(K-shot)。
在K-shot对话理解任务中给定输入查询短语序列x=(x1,x2,…,xn)和K-shot支持集S作为参考,找到x的最合适的语义框架y*: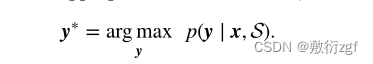
建议方法
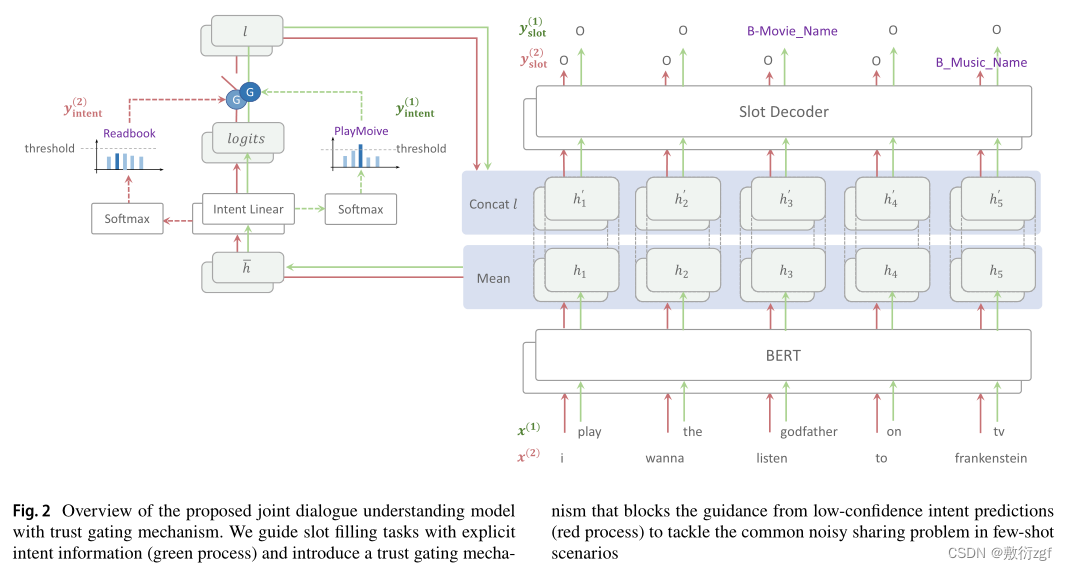
联合对话模型
以[JointBert](Chen Q, Zhuo Z, Wang W (2019) Bert for joint intent classifcation and slot flling)模型作为基础,缺陷: 该方法通过同时学习两个有监督的公共表示空间来实现内隐联合学习,这通常在平衡两个任务的学习方面面临困难,并且无法捕获显式任务关系。为了解决这一问题,先前的工作已经证明了明确使用意图信息来指导槽位填充任务的有效性[22]( Goo CW, Gao G, Hsu YK, et al (2018) Slot-gated modeling for joint slot flling and intent prediction. In: Proc. of NAACL-HLT, pp 753–757),[35](Li C, Li L, Qi J (2018) A self-attentive model with gate mechanism for spoken language understanding. In: Proc. of EMNLP, pp 3824–3833),[47](Qin L, Che W, Li Y, et al (2019) A stack-propagation framework with token-level intent detection for spoken language understanding. In: Proc. of EMNLP-IJCNLP, pp 2078–2087),[49](Qin L, Li Z, Che W, et al (2021a) Co-gat: A co-interactive graph attention network for joint dialog act recognition and sentiment classifcation. In: Proc. of AAAI, pp 13,709–13,717)。基于类似的思想,本篇工作提出了一种新的信任门控机制,以通过显式联合学习来改进模型。
信任门控机制
采用了一种直接有效的使用意图信息的方式,即直接共享预测意图分布的意图信息。具体地说,与普通联合学习不同,将intent与编码器输出h的逻辑连接起来,以获得插槽的intent引导特征h′。计算程序如下:
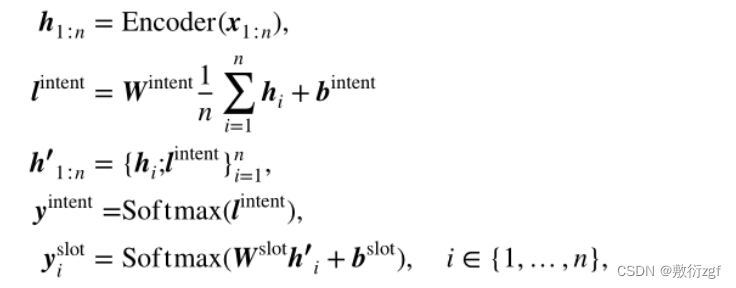
Encoder是两个任务共享的BERT模型,Wintent、bintent和Wslot、bslot分别是意图和槽位分类器的权重和偏差。
在少样本学习环境下,将意图信息直接共享给槽位填充任务可能会带来一些问题,例如负面的意图分类性能可能会导致负面引导,并损害两者的性能,因此需要确定意图信息是否可信。
本篇工作引入意图的置信度分数Cintent,其计算为yintent的最大值。其中Cintent表示模型预测的最可能意图的概率,这可以反映模型正确预测的置信度。对于置信度分数较低的情况,例如Cintent=0.2,意图信息容易产生噪声,不应与槽位填充任务共享。因此,设置了一个置信阈值t来过滤出可信信息,并形成信任门G。
模型学习
元学习是少样本学习问题最流行的解决方案之一,它经常学习大量任务的泛化能力,并通过几个例子快速适应新领域。这些算法的经典类型,如MAML[20](Finn C, Abbeel P, Levine S (2017) Model-agnostic meta-learning for fast adaptation of deep networks. In: ICML, pp 1126–1135)和Reptile[44](Nichol A, Achiam J, Schulman J (2018) On frst-order meta-learning algorithms. arXiv preprint arXiv:1803.02999),通过学习更好的初始化,可以快速适应少样本领域。
首次引入Reptile联合对话理解的改进方法,Reptile是一种一阶元学习方法,它在许多成熟的FSL基准上实现了良好的性能,同时避免了经典元算法(如MAML)的二阶派生的高成本。Reptile通过学习多个源域上的元模型来学习良好的通用初始化。具体来说,它对单个域重复采样,在其上训练复制的模型,并将元模型移向域上训练复制模型的权重。在重复训练之后,训练的元模型的参数被用作不可见域的初始化。
常见的Reptile算法可能不稳定,因为它为每个域更新一次元模型,而域可能会非常不同。在差距较大的领域之间切换可能会打乱学习方向。此外,在一致的学习率下,元模型可能在某些特定任务上学习过多的任务相关知识,这可能会损害元模型的泛化能力。此外,原始Reptile在更新初始化参数时使用固定的学习速率,这也会阻碍收敛。
使用改进的Reptile去训练联合对话理解
作者发现同时在多个任务上更新模型可以学习更好的通用模型,在Reptile中,作者使用恒定的学习速率通过简单的随机梯度下降(SGD)来优化元模型。然而,学习率预热和衰减[23]被证明对学习更广义的模型至关重要。此外,像AdaGrad[15]、Adam[30]和AdamW[36]这样的自适应梯度方法有助于对逃避局部极小值进行建模,是训练深度神经网络的默认选择。因此,我们建议将线性学习速率衰减调度和带预热的AdamW优化器应用于元模型的优化。
使用上述改进的爬行算法,本篇工作消除了优化方向的尖峰,并平滑了训练过程,以训练一个更广义的元模型,该模型可以通过几个样本快速适应。
数据集构建
构建过程分为两步:①收集并注释了一个包含59个领域的完整对话理解语料库;②将语料库分为训练和不可见的少样本。还对支持和查询集进行了采样,以模拟少样本学习场景。
对话收集
从iFlytek的AIUI开放对话平台收集真实对话域的对话话语,在话语收集之前,根据API调用的频率选择流行域,例如“冠状病毒的搜索信息”。忽略了没有意向或没有槽位的域,以确保联合学习。对于模式定义,利用AIUI定义的语义框架和域,并细化域的部分以删除不明确的标签。最后,收集了59个不同的对话域以及语义框架定义。
由于并非所有领域都有足够的真实用户数据,通常从两个来源收集用户话语:(1)真实用户话语。(2)由数据注释器编写的语句。第二种构造数据的方法类似于经典的对话数据收集方法,即Oz向导[6,16,29,75],其中机器从注释器类型的对话日志中学习。
对于源(1)从AIUI平台中对现有用户话语进行采样,并删除敏感信息。对于源(2)要求四个数据注释器模拟对话代理的用户,并为特定域编写查询语句,例如查询天气。源(1)和(2)之间的平均话语比率约为3∶7。
数据标注
用意图(句子级别)和槽标签(标记级别)标记每个话语。
标记过程包括两个步骤:①通过使用AIUI平台的测试工具预测语义框架来获得每个话语的粗略注释。②人类工作者验证每个粗略标注的话语,并重新标注不恰当的话语。数据被平均分成四部分,然后由四名工人分别标注。参与写作的四位标注者也负责这一部分。标注后,执行数据重新检查。另外三个标注器独立地检查了所有数据,在此期间重新标注了不正确的数据。
少样本场景模拟
少样本数据构建
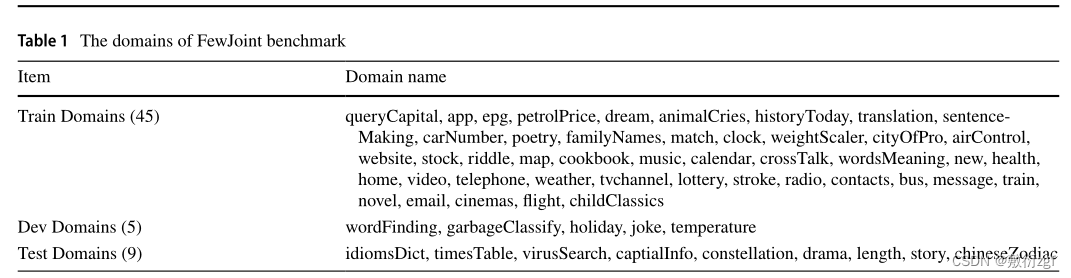
保留一些领域作为少样本学习测试领域,这些领域在训练期间不可见。首先将59个域分成三个没有交集的部分,即训练、验证和测试集。然后在每个验证或测试集域上,构建一个K-shot支持集,并使用其他数据作为查询集。因此,FewJoint可以在看不见的测试域上模拟少样本场景:需要模型来预测查询样本的标签,只需要几个支持示例。表1显示了域划分的详细信息。
重构测试领域
手动将每个测试/验证域重建为两个部分:少样本支持集和一个查询集。在这里,K-shot支持集由以下原则手动构建:①确保每个类(intent和slot)至少出现k次,同时保持支持集尽可能小;②避免支持集和查询集之间的重复;③引导表达式和支持集槽值的多样性。
重构训练领域
训练集由45个训练领域组成,这些领域提供了先验知识,帮助快速学习未知领域。对于少样本学习,有两种流行的策略来学习这些先验知识,并且它们的数据格式非常不同。在基准测试中,提供了两种训练集格式来支持这两种学习策略:①学习所有训练数据的特征编码层,这只需要将所有训练域话语组合成一个单独的预训练集;②只举几个例子,即元学习,学习快速学习的能力。这需要将训练集重建为一系列少样本集(即支持集和查询集对)。策略(1)不需要特殊的数据处理。为了支持策略(2)需要对查询和支持集进行采样,以在训练域内构建少样本学习集。采用最小包含算法[26]来实现大量少样本集的自动采样。
最小包含算法有助于对序列标签问题和多标签问题的支持集进行采样,其中单个实例可能与多个标签相关联。
统计
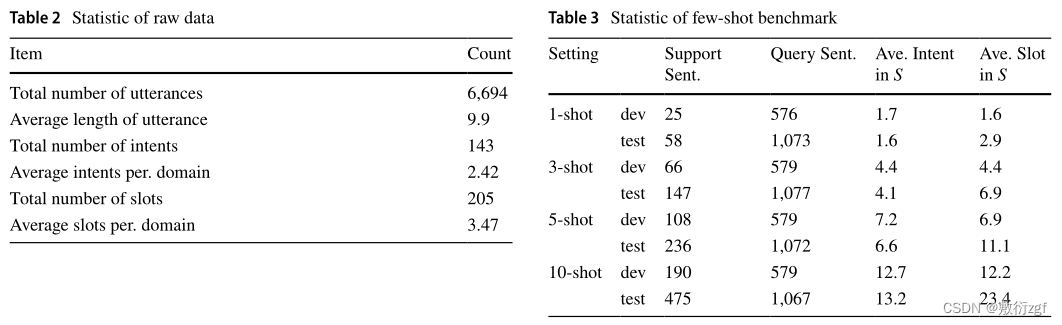
语料库中包含6694个话语,平均话语长度为9.9(汉字数)。如前所述,收集了59个真实对话域的数据。其中,保留了14个域作为不可见的少样本域进行评估,并将所有其他45个域用作训练域。为了进行评估,选择了9个域作为测试集,并使用5个域进行开发。总体而言,数据集包含143个不同的意图和205个不同的槽。
实验
除了验证FewJoint,还在Snips上验证模型的泛化性。
评估
三个评估指标:意图准确率、槽位F1分值、联合准确率。
基线
将该方法与各种基线方法进行比较,基于相似度的少样本学习方法(非微调方法)、基于微调的迁移学习方法。
结果
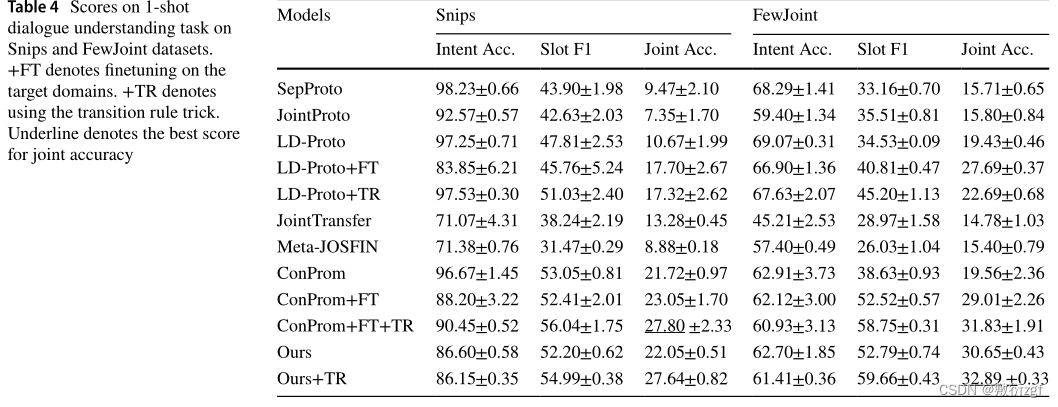
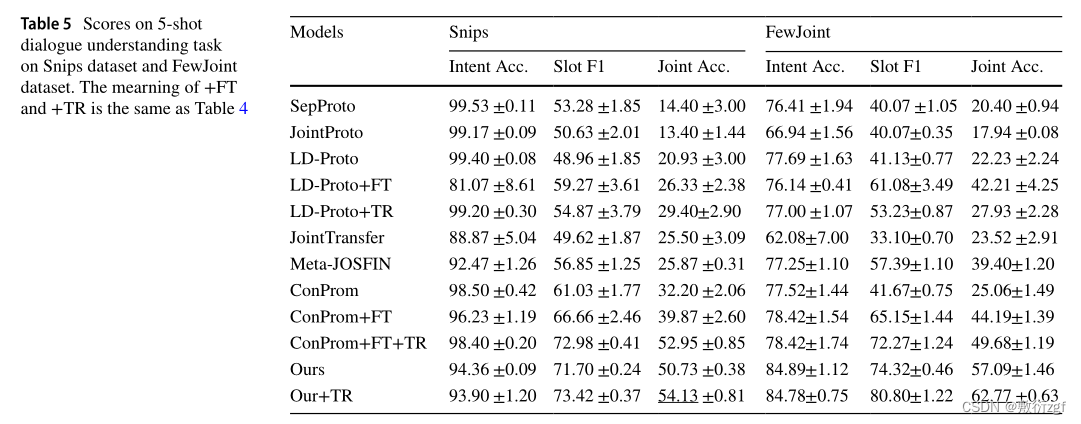
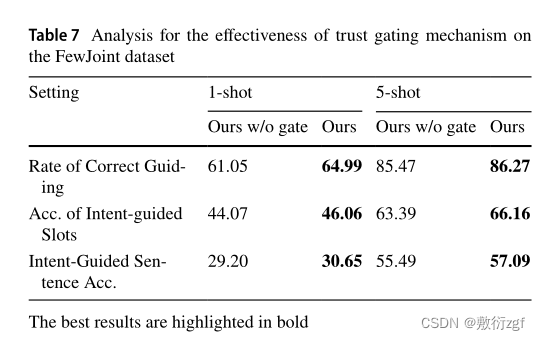
信任门控机制的有效性
结论
本篇工作提出了一种新的用于联合对话理解的少样本学习基准,这也是第一个用于联合多任务学习的少样本NLP基准。与现有的少样本学习数据集(通常需要构建假域)相比,该基准由59个真实对话域组成,这可以更好地反映真实世界中对话理解的复杂性。此外,引入了一种基于信任门控机制的模型,以指导高质量意图信息的槽位填充,并引入了一个基于Reptile的训练过程,以提高在不可见的少样本域上的模型可推广性。在两个数据集上的实验中,所提出的方法显著提高了性能并实现了新的最先进性能。