
【华为机试真题详解 Python实现】静态扫描最优成本【2023 Q1 | 100分】
文章目录
- 前言
- 题目描述
- 输入描述
- 输出描述
- 示例 1
- 输入:
- 输出:
- 示例 2
- 输入:
- 输出:
- 题目解析
- 参考代码
前言
《华为机试真题详解》专栏含牛客网华为专栏、华为面经试题、华为OD机试真题。
如果您在准备华为的面试,期间有想了解的可以私信我,我会尽可能帮您解答,也可以给您一些建议!
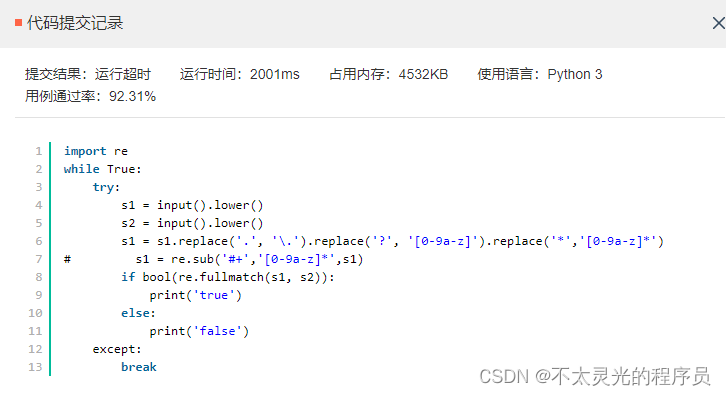
本文解法非最优解(即非性能最优),不能保证通过率。
特别提醒!!!!
注意1:机试为ACM 模式
你的代码需要处理输入输出,input接收输入、注意2:机试按通过率记分
复杂题目可以考虑暴力破解,再逐步优化,不是运行超时就无法得分,如下,提交结果运行超时,但用例通过率>92.31% , 如果是100分的题目,可以得92.3分。
题目描述
静态扫描快速识别源代码的缺陷,静态扫描的结果以扫描报告作为输出:
- 文件扫描的成本和文件大小相关,如果文件大小为 ,则扫描成本为
N个金币 - 扫描报告的缓存成本和文件大小无关,每缓存一个报告需要
M个金币 - 扫描报告缓存后,后继再碰到该文件则不需要扫描成本,直接获取缓存结果
给出源代码文件标识序列和文件大小序列,求解采用合理的缓存策略,最少需要的 金币Q数
输入描述
第一行为缓存一个报告金币数 M,1 <= M <=100
第二行为文件标识序列: F1,F2,F3…Fn,其中1 <= N <= 10000,1 <= F <=1000
第三行为文件大小序列: S1,S2,S3…Sn,其中1 <= N <= 10000,1 <= S <=10
输出描述
采用合理的缓存策略,需要的最少金币数
示例 1
输入:
5
1 2 2 1 2 3 4
1 1 1 1 1 1 1
输出:
7
说明:
文件大小相同,扫描成本均为1个金币。缓存任意文件均不合算,所以每次都是重新扫描文本,因而最少成本为7金币
示例 2
输入:
5
2 2 2 2 2 5 2 2 2
3 3 3 3 3 1 3 3 3
输出:
9
说明:
2号文件出现了8次,不缓存成本为 3*8=24,扫描加缓存成本共计 3+5=8,显然缓存更优,最优成本为 8+1=9
题目解析
获取文件的方式有两种:
第一种是扫描文件,成本包含扫描文件成本;
第二种是从缓存中读取文件,成本包含一次扫描文件成本 + 缓存文件的成本。
我们只需要获取到每个文本的扫描次数与缓存方案的成本进行比较,单个文件选择最优方案,整体成本即为最优方案(贪婪)。
这个方式再业务中也有很多应用场景,例如:
数据访问优化,对于数据库热点数据的访问,首先从数据库获取数据,生成键值并存储在缓存中,下次再获取该数据时直接从缓存中加载,减少数据获取的延时。
在业务场景中高速缓存的使用成本较高,我们可能需要考虑过期时间、淘汰策略等问题,而这道题目中没有缓存加载顺序,使用限制等说明,所以这道题目中不需要考虑。
参考代码
while 1:try:m = int(input())fList = list(map(int, input().split()))sList = list(map(int, input().split()))cache = []total = 0for i in range(len(fList)):if fList[i] in cache:continuecache.append(fList[i])c = fList.count(fList[i])total += min(sList[i] * c, sList[i] + m)print(total)except Exception as e:break
或者保存分项
while 1:try:m = int(input())fList = list(map(int, input().split()))sList = list(map(int, input().split()))cache = {}for i in range(len(fList)):if fList[i] in cache:continuec = fList.count(fList[i])cache[fList[i]] = min(sList[i] * c, sList[i] + m)print(sum(cache.values()))except Exception as e:import tracebackprint(traceback.print_exc())break
最后,如果你有什么样的问题或解题心得,欢迎评论区交流!
上一篇:利用matlab的newff构建BP神经网络来实现数据的逼近和拟合
下一篇:vue-plugin-hiprint vue hiprint vue使用hiprint打印控件VUE HiPrint HiPrint简单使用