一文读懂倒排序索引涉及的核心概念
基础概念
相信对于第一次接触Elasticsearch的同学来说,最难理解的概念就是倒排序索引(也叫反向索引),因为这个概念跟我们之前在传统关系型数据库中的索引概念是完全不同的!在这里我就重点给大家介绍一下倒排序索引,这个概念搞明白之后,然后学习Elasticsearch就会清晰很多了。
正向索引和倒排序索引
在没有搜索引擎时,我们是直接输入一个网址,然后获取网站内容,这时我们的行为是:
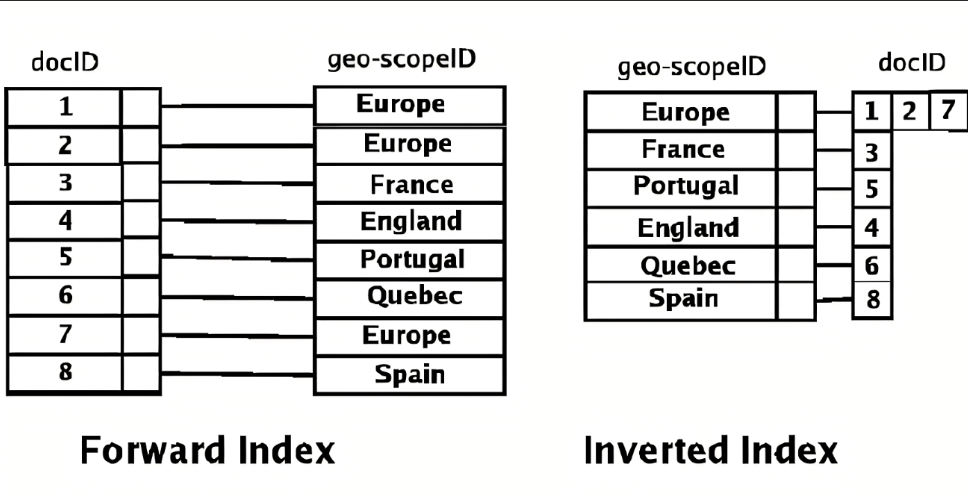
document -> to -> words 通过文章,获取里面的单词,此谓正向索引,forward index.
有了搜索引擎后,我们的行为是:输入一个单词,找到含有这个单词或者和这个单词有关系的文章:word -> to -> documents 我们把这种索引叫做inverted index,直译过来叫做倒排序索引,也叫反向索引。
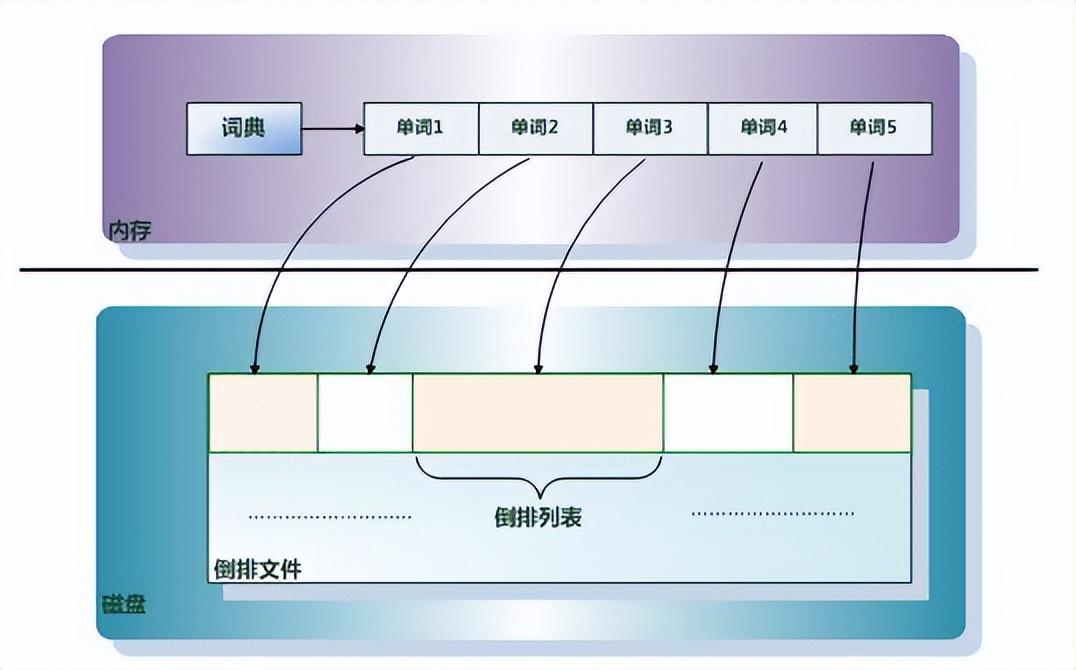
倒排序索引是实现“单词-文档矩阵”的一种具体存储形式,通过倒排序索引,可以根据单词快速获取包含这个单词的文档列表。倒排序索引主要由两个部分组成:“单词词典”和“倒排文件”
倒排序索引中重要的概念
文档(Document)
一般搜索引擎的处理对象是互联网网页,而文档这个概念要更宽泛些,代表以文本形式存在的存储对象,相比网页来说,涵盖更多种形式,比如Word,PDF,html,XML等不同格式的文件都可以称之为文档
字段(Field)
可以理解成数据库行中的字段,一个Document会由一个或多个Field组成
文档编号(Document ID)
在搜索引擎内部,会将文档集合内每个文档赋予一个唯一的内部编号,以此编号来作为这个文档的唯一标识,这样方便内部处理,每个文档的内部编号即称之为“文档编号”,后文有时会用DocID来便捷地代表文档编号。
举个例子,文档和词条之间的关系如下图:
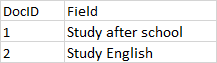
上图中每一行就是一个Document
字段值被分析之后,存储在倒排索引中,倒排索引存储的是分词(Term)和文档(Doc),它们之间的关系,简化版的倒排索引如下图:
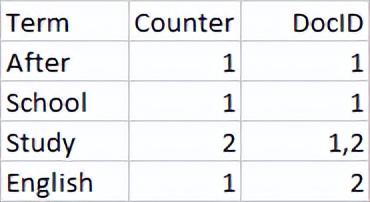
上图中counter代表统计分词的次数
单词词典(Lexicon)
搜索引擎的索引单位通常是单词,单词词典是由文档集合中出现过的所有单词构成的字符串集合,它用来维护文档集合中出现过的所有单词的相关信息,同时用来记载某个单词对应的倒排列表在倒排文件中的位置信息。
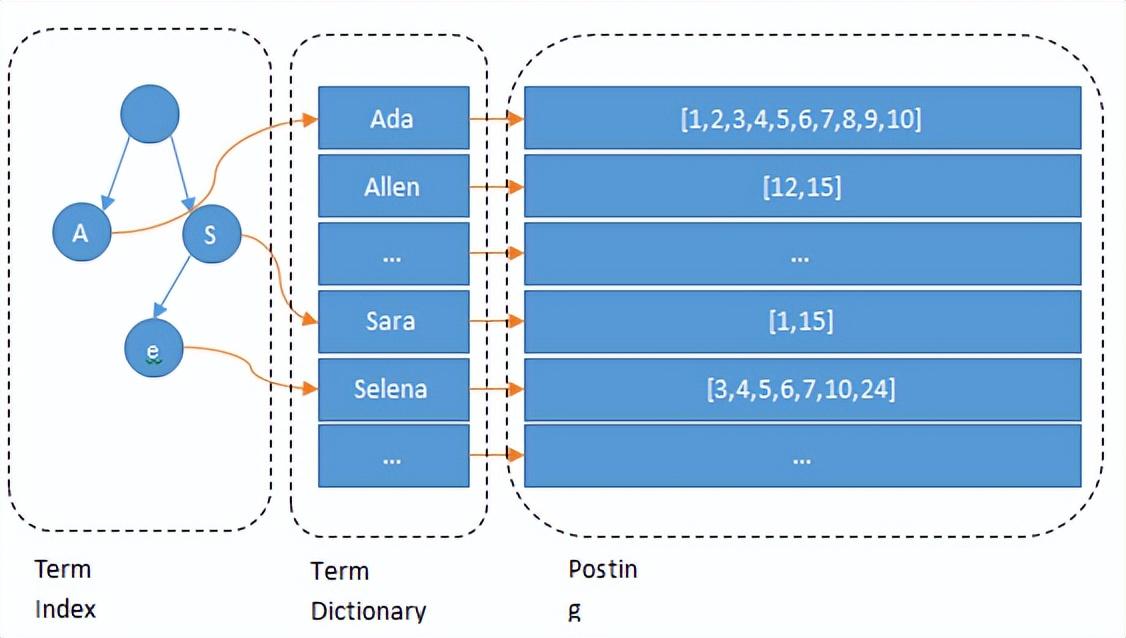
为了更好的理解单词词典这个抽象概念,我们通过Elasticsearch来进行举例,ES 为了能快速找到某个 Term,先将所有的 Term 排个序,然后根据二分法查找 Term,时间复杂度为 O(log n);,就像通过字典查找一样,这就是 Term Dictionary。如果 Term 太多,Term Dictionary 也会很大,放内存不现实,于是有了 Term Index。就像字典里的索引页一样,S开头的有哪些 Term,分别在哪页,可以理解 Term Index是一棵树,这棵树不会包含所有的 Term,它包含的是 Term 的一些前缀,通过 Term Index 可以快速地定位到 Term Dictionary 的某个 Offset,然后从这个位置再往后顺序查找。
在内存中用 FST 方式压缩 Term Index,FST 以字节的方式存储所有的 Term,这种压缩方式可以有效的缩减存储空间,使得 Term Index 足以放进内存,但这种方式也会导致查找时需要更多的 CPU 资源。对于存储在磁盘上的倒排表同样也采用了压缩技术减少存储所占用的空间。
分词(Analysis)
将文本切分为一系列单词的过程
例如文本:谷歌地图之父跳槽FaceBook
分词结果:谷歌\ 地图\之父\跳槽\FaceBook
倒排列表(PostingList)
倒排列表记录了出现过某个单词的所有文档的文档列表及单词在该文档中出现的位置信息,每条记录称为一个倒排项(Posting)。根据倒排列表,即可获知哪些文档包含某个单词。实际的倒排列表中并不只是存了文档ID这么简单,还有一些其它的信息,比如:词频(Term出现的次数)、偏移量(offset)等,如下图所示:
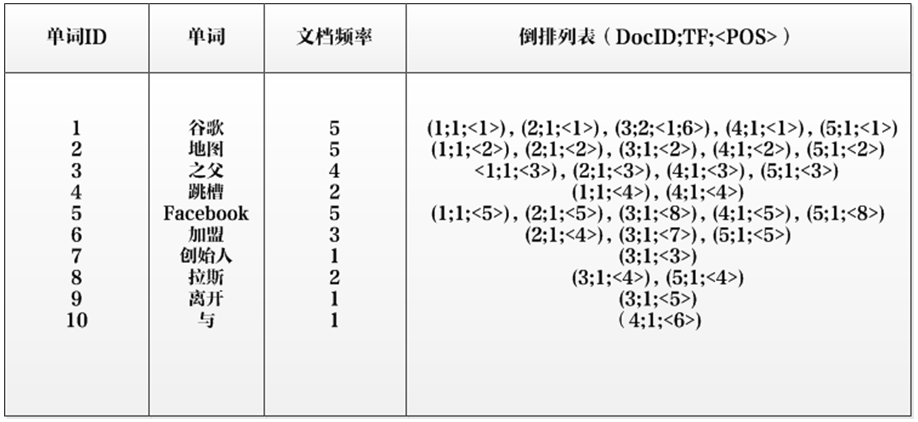
单词ID、单词和文档频率就不多说了,这里重点解释一下倒排列表:
DocID:单词出现的文档id
TF:单词在某个文档中出现的次数
POS:单词在文档中出现的位置
以单词“加盟”为例,其单词编号为6,文档频率为3,代表整个文档集合中有三个文档包含这个单词,对应的倒排列表为{(2;1;<4>),(3;1;<7>),(5;1;<5>)},含义是在文档2,3,5出现过这个单词,在每个文档的出现过1次,单词“加盟”在第一个文档的POS是4,即文档的第四个单词是“加盟”,其他的类似。
倒排文件(Inverted File)
所有单词的倒排列表往往顺序地存储在磁盘的某个文件里,这个文件即被称之为倒排文件,倒排文件是存储倒排索引的物理文件。
词典、单词、倒排文件和倒排列表概念之间的关系
一张图就能很好的说明这些概念的关系