
Spark读取JDBC调优
Spark读取JDBC调优,如何调参
- 一、场景构建
- 二、参数设置
- 1.灵活运用分区列
实际问题:工作中需要读取一个存放了三四年历史数据的pg数仓表(缺少主键id),需要将数据同步到阿里云 MC中,Spark在使用JDBC读取关系型数据库时,默认只开启一个task去执行,性能低下,因此需要通过设置一些参数来提高并发度。一定要充分理解参数的含义,否则可能会因为配置不当导致数据倾斜!
翻看了网络上好多相关介绍,都沾边。下边总结一下!
您是菜鸟就好好学习,您是大佬欢迎提出修改意见!
一、场景构建
以100行数据为例(实际307983条):
- 创建表
CREATE TABLE IF NOT EXISTS test(good_id STRING ,title STRING ,sellcount BIGINT,salesamount Double
)COMMENT '测试表'
PARTITIONED BY (dt STRING COMMENT '分区字段'
);
- 插入数据
insert into test partition (dt = '202001')
values ('1001','卫衣',1,100.1),('1002','卫裤',2,101.2),('1003','拖鞋',3,10.3)...,('1100','帽子',100,19.23)
二、参数设置
配置文件示例:
jdbc: &jdbcoptions.url: "jdbc:postgresql://xxx.xxx.xxx.xxx:8000/postgres"options.user: "xxxxxx"options.password: "xxxxxx"options.driver: "org.postgresql.Driver"input:- moduleClass: "JDBC"<<: *jdbcoptions.dbtable: "SELECT *,cast(good_id as bigint)*1%6 mo FROM test.test where dt = '202001'"options.fetchsize: "100"options.partitionColumn: "mo" # 分区列,一般为自增id,下边解释下为啥用mooptions.numPartitions: "6" #分区数options.lowerBound: "0"options.mytime: "${yyyy}-${MM}-${dd}"options.upperBound: "6" # 该值设置为和分区列最大值差不多的值resultDF: "df"
提交spark配置
spark-submit \--class xx.xxx.xxx.xxx \--master local[*] \--num-executors 6 \--executor-cores 1 \--executor-memory 2G \--driver-memory 4G \/root/test/xxx.jar \-p xxx/xxx.yaml -cyctime $cyctime
-
options.fetchsize:一次性读取的数据条数,按集群规模(例:64核128G)一次1000条;阿里云Spark集群链接不了华为云pg数仓,我开了一台独立机器(8核16G)一次100条
-
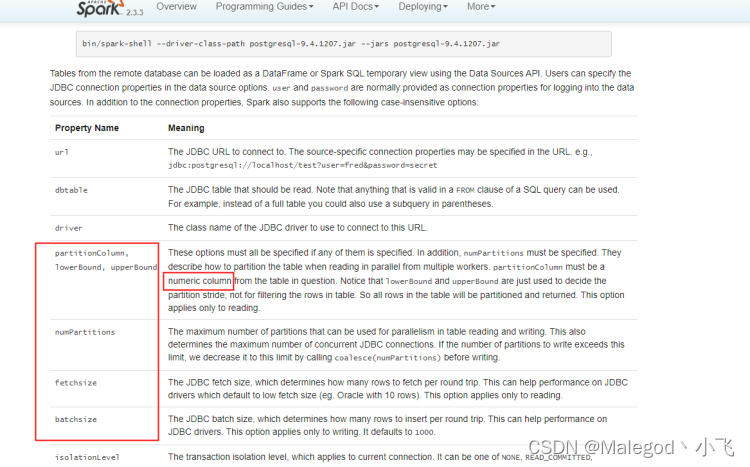
options.partitionColumn:分区列,必须是bigint类型;
-
options.numPartitions:设置分区数,最好和spark提交的executors数一致;上文中spark任务数为6,分区数也为6
-
options.lowerBound:分区开始值
-
options.upperBound:分区结束值;numPartitions、lowerBound、upperBound这三个必须同时设置,每个分区的数据量计算公式为:upperBound / numPartitions - lowerBound / numPartitions,任务运行时间看的是最长的那个任务,所以要尽可能保证每一个分区的数据量差不多
官方配置文档:
1.灵活运用分区列
有的小伙伴就该思考为啥不用自增id做分区列呢?
因为实际生产环境中,一是不需要,二是创建表忽略了自增id等等。
为啥要新做一列mo,而不直接将商品id转bigint用呢?
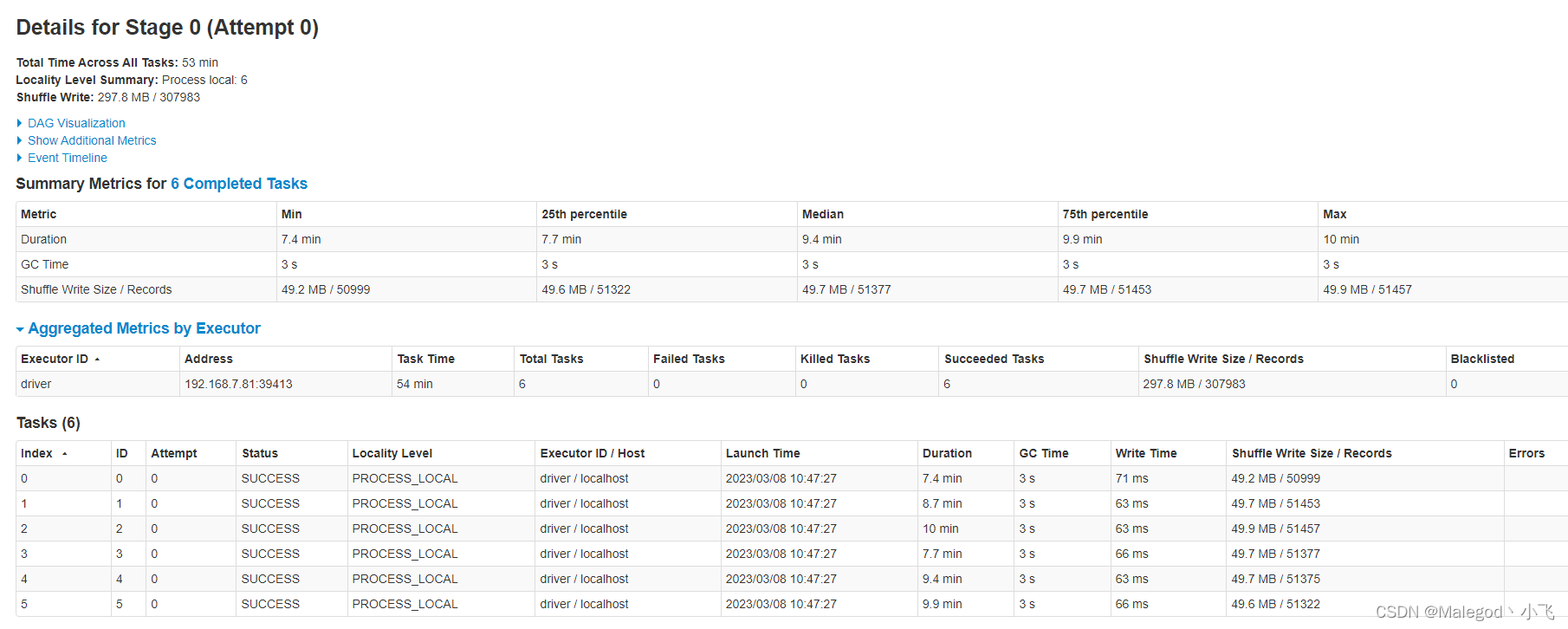
算是一个补救措施,新做一个数据列,在读取过程用mo做shuffle,mo是商品id强转为bigint后对6取膜,结果为0-5共6种可能,提高了shuffle的效率,计算分区的数据量:6 / 6 - 0 / 6 = 1;也就是说分区值为0,1,2,3,4,(大于5),对应6个任务,6个核心。
下面是运行shuffle结束后的截图,可以看到每一个task获取的数据量都比较均匀
下面来看一个错误的案例:
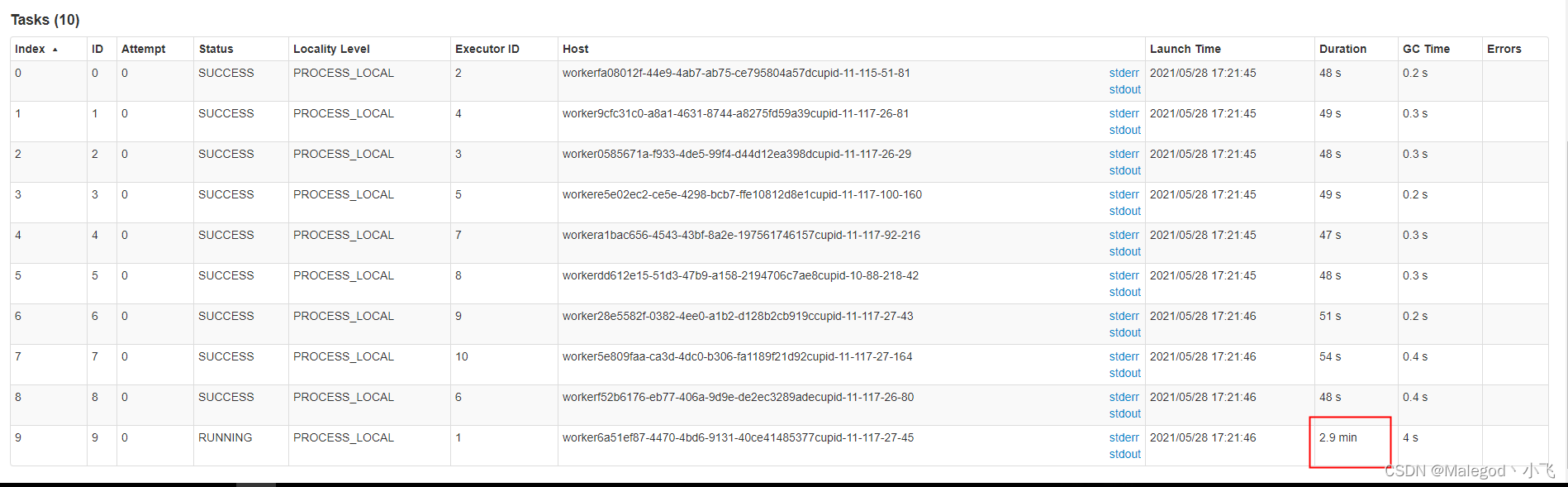
上图配置就会导致数据倾斜
numPartitions=10,
lowerBound=0,
upperBound=100,
表的数据量是1000。
根据计算公式每个分区的数据量是100/10-0/10=10,分10个区,那么前9个分区数据量都是10,但最后一个分区数据量却达到了910,即数据倾斜了,所以upperBound-lowerBound要和表的分区字段最大值差不多
有啥需要优化的欢迎评论纠正