
MySQL - 多表查询
创始人
2024-06-01 00:20:29
0次
目录
- 1. 多表查询示例
- 2. 多表查询分类
- 2.1 等/非等值连接
- 2.1.1 等值连接
- 2.1.2非等值连接
- 2.2 自然/非自然连接
- 2.3 内/外连接
- 2.3.1 内连接
- 2.3.2 外连接
- 3.UNION的使用
- 3.1 合并查询结果
- 3.1.1 UNION操作符
- 3.1.2 UNION ALL操作符
- 4. 7种JOIN操作
- 5. join 多张表
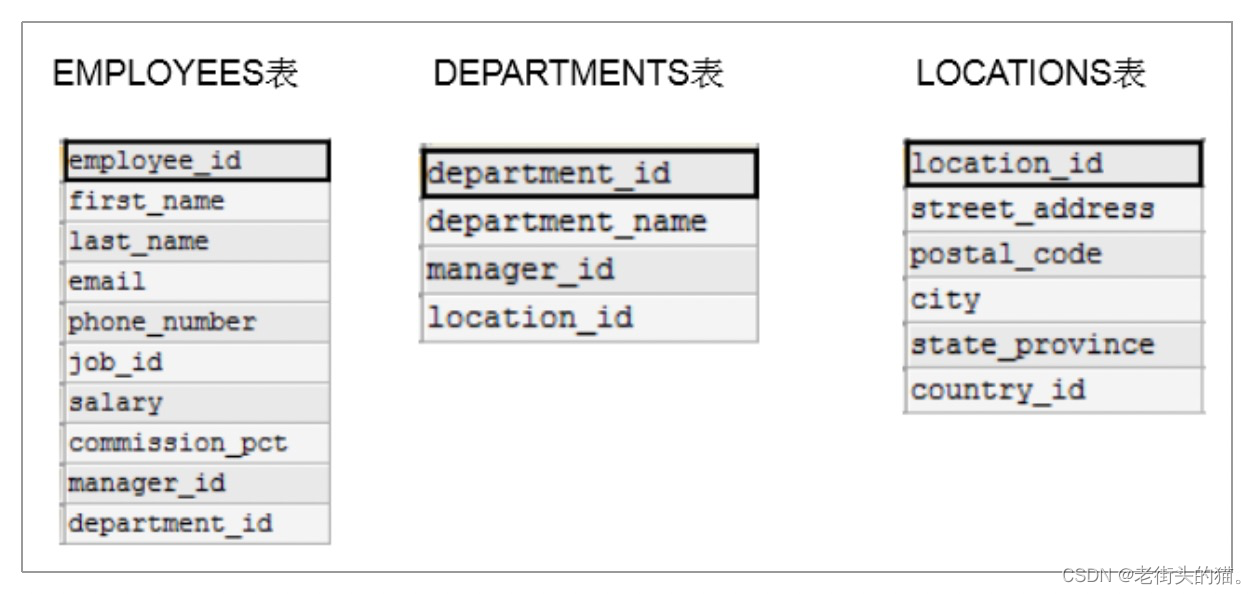
多表查询,也称为关联查询,指两个或更多个表一起完成查询操作。
- 如果查询语句中出现了多个表中都存在的字段,则必须指明此字段所在的表。
SELECT tb_a.id, tb_b.id FROM tb_a,tb_b WHERE tb_a.id=tb_b.id;
- 可以给表起别名,在SELECT和WHERE中使用表的别名
SELECT t1.id, t2.id FROM tb_a as t1,tb_b as t2 WHERE t1.id=t2.id;
- 如果给表起了别名,一旦在SELECT或WHERE中使用表名的话,则必须使用表的别名,而不是使用表的原名。
- 如果有n个表实现多表的查询,则需要至少n-1个连接条件
1. 多表查询示例
新建表:
SELECT e.employee_id as '员工id',e.last_name as '员工名称',d.department_name as '员工所在部门',l.city as '部门所在城市'
FROM employees e, departments d, locations l
WHERE e.department_id=d.department_idAND d.location_id=l.location_id;
结果:
| 员工id | 员工名称 | 员工所在部门 | 部门所在城市 |
|---|---|---|---|
| 200 | Whalen | Administration | Seattle |
| 201 | Hartstein | Marketing | Toronto |
| 202 | Fay | Marketing | Toronto |
| 114 | Raphaely | Purchasing | Seattle |
| 115 | Khoo | Purchasing | Seattle |
2. 多表查询分类
2.1 等/非等值连接
2.1.1 等值连接
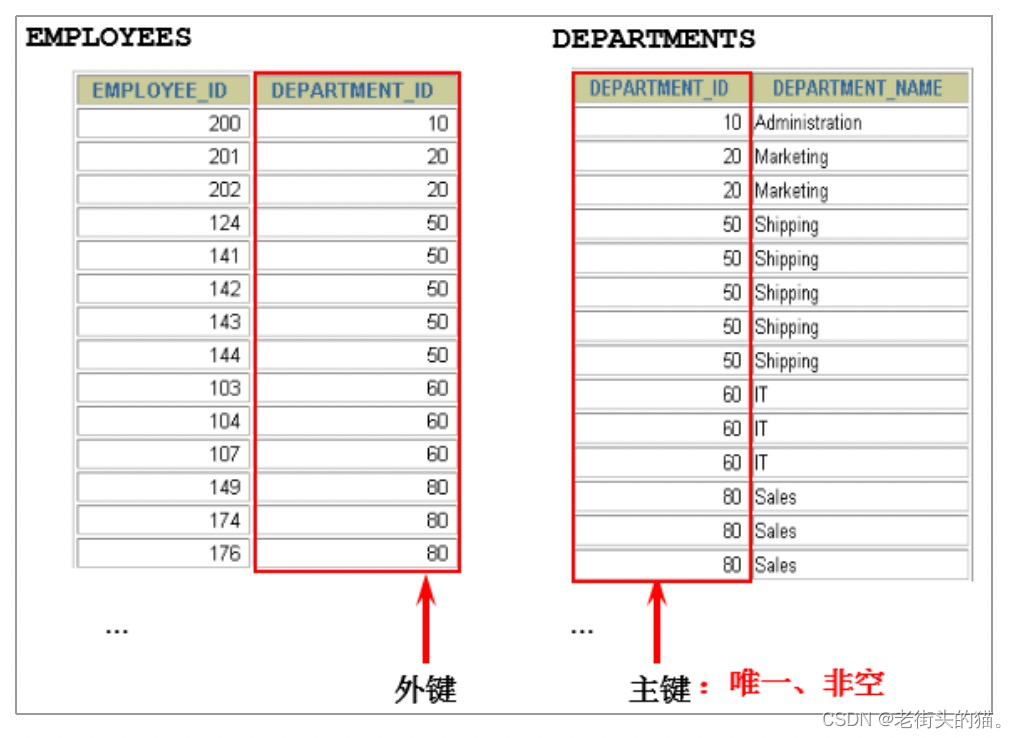
SELECT employees.employee_id as '员工id',employees.last_name as '员工名称',employees.department_id as '部门id',departments.department_id as '部门id',departments.department_name as '部门名称',departments.location_id as '位置id'
FROM employees, departments
WHERE employees.department_id = departments.department_id;
| 员工id | 员工名称 | 部门id | 部门id | 部门名称 | 位置id |
|---|---|---|---|---|---|
| 200 | Whalen | 10 | 10 | Administration | 1700 |
| 201 | Hartstein | 20 | 20 | Marketing | 1800 |
| 202 | Fay | 20 | 20 | Marketing | 1800 |
| 114 | Raphaely | 30 | 30 | Purchasing | 1700 |
| … |
2.1.2非等值连接
SELECT e.last_name as '员工名称',e.salary as '员工薪资',j.grade_level as '员工级别'
FROM employees e, job_grades j
WHERE e.salary BETWEEN j.lowest_sal AND j.highest_sal;
-- 或者
WHERE e.salary >= j.lowest_sal AND e.salary <= j.highest_sal;
| 员工名称 | 员工工资 | 员工级别 |
|---|---|---|
| King | 24000 | E |
| Kochhar | 17000 | E |
| De Haan | 17000 | E |
| Hunold | 9000 | C |
| Ernst | 6000 | C |
| Austin | 4800 | B |
2.2 自然/非自然连接
SELECT emp.employee_id as '员工id', emp.last_name as '员工名称', mgr.employee_id as '管理者id', mgr.last_name as '管理者名称'
FROM employees emp, employees mgr
WHERE emp.manager_id = mgr.employee_id;
或者
SELECT CONCAT(worker.last_name ,' works for ' , manager.last_name)
FROM employees worker, employees manager
WHERE worker.manager_id = manager.employee_id ;| 员工id | 员工名称 | 管理者id | 管理者名称 |
|---|---|---|---|
| 101 | Kochhar | 100 | King |
| 102 | De Haan | 100 | King |
| 103 | Hunold | 102 | De Haan |
| 104 | Ernst | 103 | Hunold |
| 105 | Austin | 103 | Hunold |
| 106 | Pataballa | 103 | Hunold |
2.3 内/外连接
- 内连接: 合并具有同一列的两个以上的表的行, 结果集中不包含一个表与另一个表不匹配的行
- 外连接: 两个表在连接过程中除了返回满足连接条件的行以外**还返回左(或右)表中不满足条件的行,这种连接称为左(或右)外连接。**没有匹配的行时, 结果表中相应的列为空(NULL)。
- 如果是左外连接,则连接条件中左边的表也称为主表,右边的表称为从表。
- 如果是右外连接,则连接条件中右边的表也称为主表,左边的表称为从表。
2.3.1 内连接
SELECT e.employee_id, d.department_id, l.city
FROM employees eINNER JOIN departments dON e.department_id = d.department_idINNER JOIN locations lON d.location_id = l.location_id;-- 返回 employees_id和department_id都不为NULL的数据
2.3.2 外连接
-- 左外连接
SELECT e.employee_id, d.department_id
FROM employees eLEFT OUTER JOIN departments dON e.department_id = d.department_id;-- 右外连接SELECT e.employee_id, d.department_id
FROM employees eRIGHT OUTER JOIN departments dON e.department_id = d.department_id;
3.UNION的使用
3.1 合并查询结果
利用UNION关键字,可以给出多条SELECT语句,并将它们的结果组合成单个结果集。合并时两个表对应的列数和数据类型必须相同,并且相互对应,各个SELECT语句之间使用UNION或UNION ALL关键字分隔。
语法格式:
SELECT column,... FROM table1
UNION [ALL]
SELECT column,... FROM table2
3.1.1 UNION操作符
UNION 操作符返回两个查询的结果集的并集,去除重复记录。
3.1.2 UNION ALL操作符
UNION ALL操作符返回两个查询的结果集的并集。对于两个结果集的重复部分,不去重。
select 'newMember' as "memberType", count(distinct full_union_id) as "memberCount"
from XXX.XXX
where XX_id = cast(66666666 as varchar) and XX_time >= '2021-06-16 00:00:00' and XX_time <= '2022-06-16 00:00:00' union allselect 'oldMember' as "memberType", count(distinct full_union_id) as "memberCount"
from XXX.XXX
where XX_id = cast(66666666 as varchar) and XX_time <'2021-06-16 00:00:00'
| memberType | memberCount |
|---|---|
| oldMember | 2,666,888 |
| newMember | 1,888,666 |
注意:执行UNION ALL语句时所需要的资源比UNION语句少。如果明确知道合并数据后的结果数据不存在重复数据,或者不需要去除重复的数据,则尽量使用UNION ALL语句,以提高数据查询的效率。
4. 7种JOIN操作
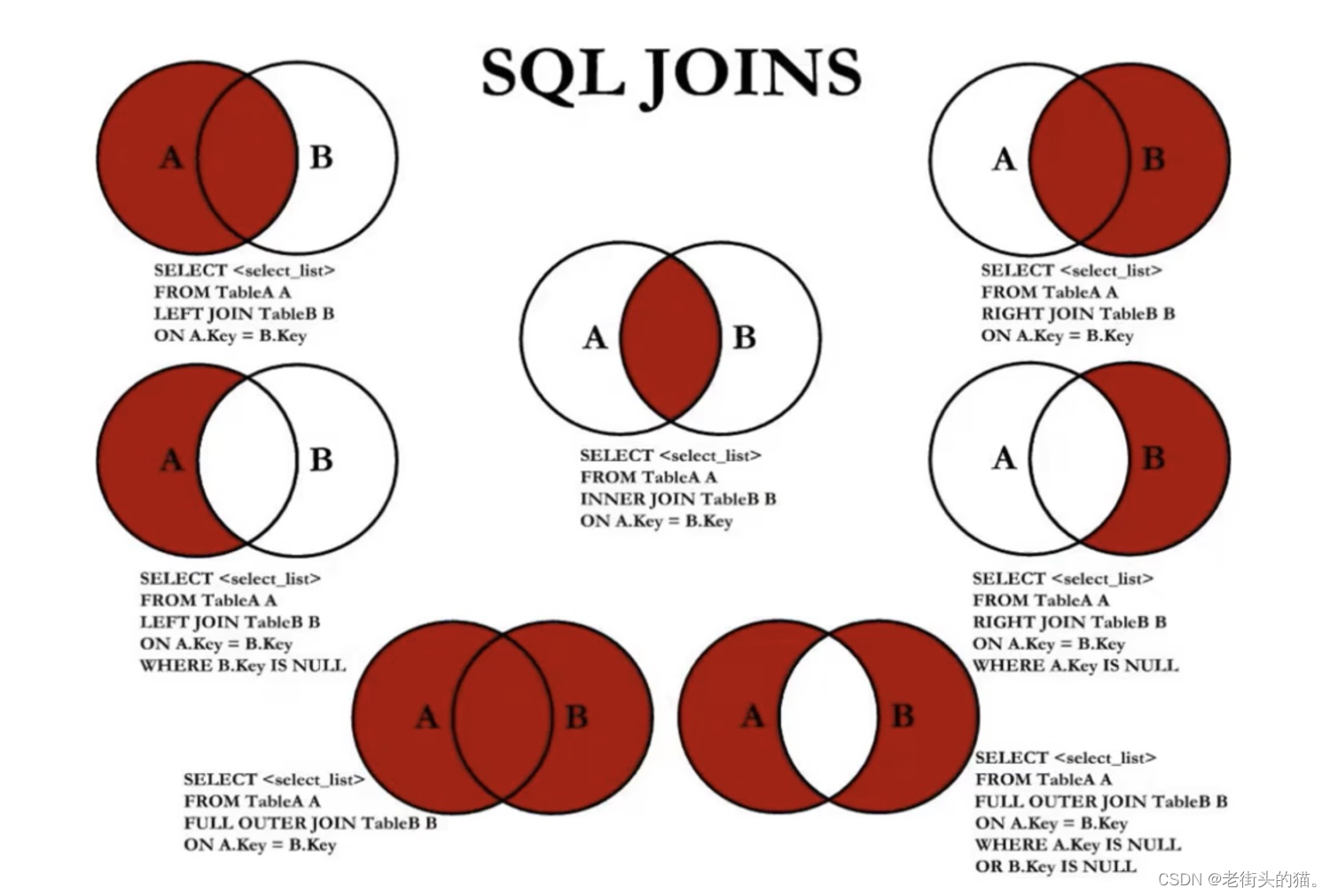
中图:内连接
SELECT employee_id, last_name, department_name
FROM employees eJOIN departments dON e.department_id = d.department_id;
左上图:左外连接
SELECT employee_id, last_name, department_name
FROM employees eLEFT JOIN departments dON e.department_id = d.department_id;
右上图:右外连接
SELECT employee_id,last_name,department_name
FROM employees eRIGHT JOIN departments dON e.department_id = d.department_id;
左中图
SELECT employee_id, last_name, department_name
FROM employees eLEFT JOIN departments dON e.department_id = d.department_id
WHERE d.department_id IS NULL;
右中图
SELECT employee_id, last_name, department_name
FROM employees eRIGHT JOIN departments dON e.department_id = d.department_id
WHERE e.department_id IS NULL;
左下图: 左中图 + 右上图
SELECT employee_id,last_name,department_name
FROM employees eLEFT JOIN departments dON e.department_id = d.department_id
WHERE d.department_id IS NULL
UNION ALL #没有去重操作,效率高
SELECT employee_id,last_name,department_name
FROM employees eRIGHT JOIN departments dON e.department_id = d.department_id;
右下图:左中图 + 右中图
SELECT employee_id,last_name,department_name
FROM employees eLEFT JOIN departments dON e.department_id = d.department_id
WHERE d.department_id IS NULL
UNION ALL
SELECT employee_id,last_name,department_name
FROM employees eRIGHT JOIN departments dON e.department_id = d.department_id
WHERE e.department_id IS NULL
5. join 多张表
SELECT B.id, A.sid, C.c_type, C.c_name, D.sku_id
FROM db_name.table_name_a ARIGHT JOIN db_name.table_name_b B ON A.id = B.idRIGHT JOIN db_name.table_name_c C ON B.channel_id = C.channel_idRIGHT JOIN db_name.table_name_d D ON A.id = D.oid
WHERE A.code = 16AND A.order_status != 4AND A.create_time > '2023-03-08 21:00:00'AND A.tid = '1234567890'
ORDER BY A.create_time DESC
LIMIT 200;
注意:
我们要控制连接表的数量。多表连接就相当于嵌套 for 循环一样,非常消耗资源,会让 SQL 查询性能下降得很严重,因此不要连接不必要的表。在许多 DBMS 中,也都会有最大连接表的限制。
【强制】超过三个表禁止 join。需要 join 的字段,数据类型保持绝对一致;多表关联查询时,保证被关联的字段需要有索引。
说明:即使双表 join 也要注意表索引、SQL 性能。
来源:阿里巴巴《Java开发手册》
相关内容
热门资讯
电视安卓系统哪个品牌好,哪家品...
你有没有想过,家里的电视是不是该升级换代了呢?现在市面上电视品牌琳琅满目,各种操作系统也是让人眼花缭...
安卓会员管理系统怎么用,提升服...
你有没有想过,手机里那些你爱不释手的APP,背后其实有个强大的会员管理系统在默默支持呢?没错,就是那...
安卓系统软件使用技巧,解锁软件...
你有没有发现,用安卓手机的时候,总有一些小技巧能让你玩得更溜?别小看了这些小细节,它们可是能让你的手...
安卓系统提示音替换
你知道吗?手机里那个时不时响起的提示音,有时候真的能让人心情大好,有时候又让人抓狂不已。今天,就让我...
安卓开机不了系统更新
手机突然开不了机,系统更新还卡在那里,这可真是让人头疼的问题啊!你是不是也遇到了这种情况?别急,今天...
安卓系统中微信视频,安卓系统下...
你有没有发现,现在用手机聊天,视频通话简直成了标配!尤其是咱们安卓系统的小伙伴们,微信视频功能更是用...
安卓系统是服务器,服务器端的智...
你知道吗?在科技的世界里,安卓系统可是个超级明星呢!它不仅仅是个手机操作系统,竟然还能成为服务器的得...
pc电脑安卓系统下载软件,轻松...
你有没有想过,你的PC电脑上安装了安卓系统,是不是瞬间觉得世界都大不一样了呢?没错,就是那种“一机在...
电影院购票系统安卓,便捷观影新...
你有没有想过,在繁忙的生活中,一部好电影就像是一剂强心针,能瞬间让你放松心情?而我今天要和你分享的,...
安卓系统可以写程序?
你有没有想过,安卓系统竟然也能写程序呢?没错,你没听错!这个我们日常使用的智能手机操作系统,竟然有着...
安卓系统架构书籍推荐,权威书籍...
你有没有想过,想要深入了解安卓系统架构,却不知道从何下手?别急,今天我就要给你推荐几本超级实用的书籍...
安卓系统看到的炸弹,技术解析与...
安卓系统看到的炸弹——揭秘手机中的隐形威胁在数字化时代,智能手机已经成为我们生活中不可或缺的一部分。...
鸿蒙系统有安卓文件,畅享多平台...
你知道吗?最近在科技圈里,有个大新闻可是闹得沸沸扬扬的,那就是鸿蒙系统竟然有了安卓文件!是不是觉得有...
宝马安卓车机系统切换,驾驭未来...
你有没有发现,现在的汽车越来越智能了?尤其是那些豪华品牌,比如宝马,它们的内饰里那个大屏幕,简直就像...
p30退回安卓系统
你有没有听说最近P30的用户们都在忙活一件大事?没错,就是他们的手机要退回安卓系统啦!这可不是一个简...
oppoa57安卓原生系统,原...
你有没有发现,最近OPPO A57这款手机在安卓原生系统上的表现真是让人眼前一亮呢?今天,就让我带你...
安卓系统输入法联想,安卓系统输...
你有没有发现,手机上的输入法真的是个神奇的小助手呢?尤其是安卓系统的输入法,简直就是智能生活的点睛之...
怎么进入安卓刷机系统,安卓刷机...
亲爱的手机控们,你是否曾对安卓手机的刷机系统充满好奇?想要解锁手机潜能,体验全新的系统魅力?别急,今...
安卓系统程序有病毒
你知道吗?在这个数字化时代,手机已经成了我们生活中不可或缺的好伙伴。但是,你知道吗?即使是安卓系统,...
奥迪中控安卓系统下载,畅享智能...
你有没有发现,现在汽车的中控系统越来越智能了?尤其是奥迪这种豪华品牌,他们的中控系统简直就是科技与艺...