
J5、String,geo
String
背景:使用 string存储key,value,当保存的数据较小时,反而空间占用大,可以考虑使用hash 进行解决空间过大的问题。
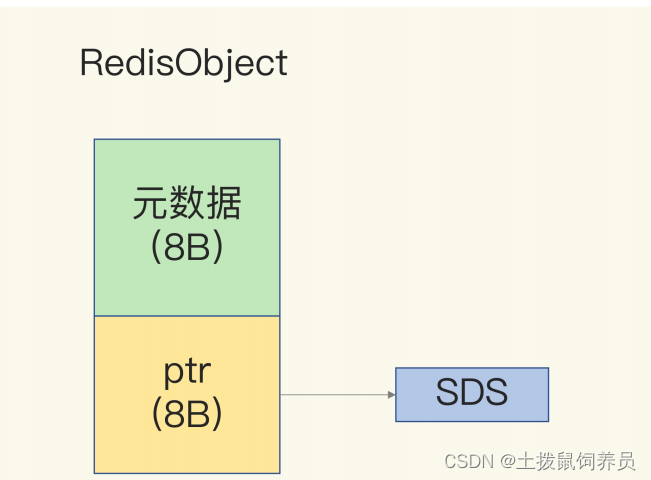
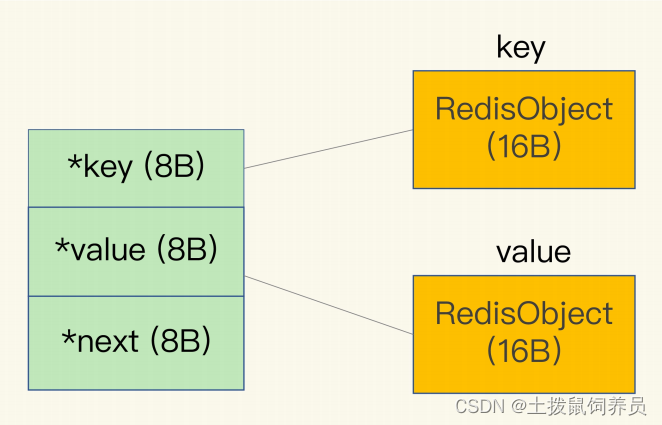
- Redis会使用一个全局哈希表保存所有键值对,hash表的每一项都是一个dictEntry,指向一个键值对。
- dictEntry有3个8字节的指针。
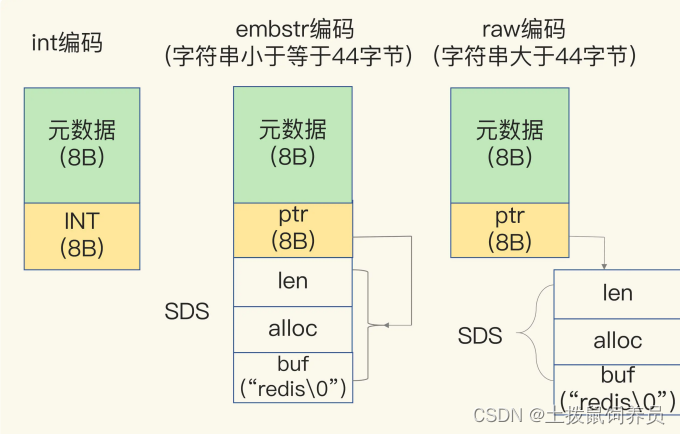
- jemalloc 在分配内存时,会根据我们申请的字节数 N,找一个比 N 大,但是最接近 N 的 2
的幂次数作为分配的空间,这样可以减少频繁分配的次数。
用什么数据结构可以节省内存?
- Redis 有一种底层数据结构,叫压缩列表(ziplist),这是一种非常节省内存的结构。
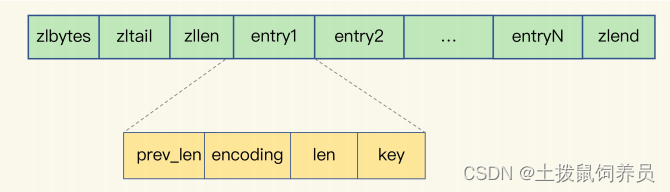
压缩列表之所以能节省内存,就在于它是用一系列连续的 entry 保存数据。每个 entry 的元
数据包括下面几部分。 - prev_len:前一个entry的长度,2种取值: 1字节(上一个entry长度小于254字节)或者5字节。
- len:自身长度,4字节
- encoding:编码方式,1字节
- content:保存实际数据。
这些entry不需要指针进行连接。
Redis 基于压缩列表实现了 List、Hash 和 Sorted Set 这样的集合类型,这样做的最大好处就是节省了 dictEntry 的开销。当你用 String 类型时,一个键值对就有一个 dictEntry,要用32 字节空间。但采用集合类型时,一个 key 就对应一个集合的数据,能保存的数据多了很多,但也只用了一个 dictEntry,这样就节省了内存。
如何用集合类型保存单值的键值对?
- 在保存单值的键值对时,可以采用基于 Hash 类型的二级编码方法。这里说的二级编码,就是
把一个单值的数据拆分成两部分,前一部分作为 Hash 集合的 key,后一部分作为 Hash 集合的 value,这样一来,我们就可以把单值数据保存到 Hash 集合中了。
127.0.0.1:6379> info memory
# Memory
used_memory:1039120
127.0.0.1:6379> hset 1101000 060 3302000080
(integer) 1
127.0.0.1:6379> info memory
# Memory
used_memory:1039136
一旦超过下面的阈值,hash类型就会使用哈希表来保存数据,一旦由压缩列表转为哈希表就不会逆转了。
- hash-max-ziplist-entries:表示用压缩列表保存时哈希集合中的最大元素个数。
- hash-max-ziplist-value:表示用压缩列表保存时哈希集合中单个元素的最大长度。
例如上面使用了 后三位作为hash的key,这样hash-max-ziplist-entries设置为1000,就可以一直使用Hash来节省空间了。
- 注意:也会有一个新的问题,查询需要遍历整个ziplist,这种方法是以空间换时间,需要权衡使用
- 使用ziplist尽量存储int数据,对存储的数据尽量采用内存小的方式存储,因为是紧凑排列,如果一个元素超过一定大小时,可能引起级联调整
- 使用hash对单个元素的过期时间很难设置,string可以给key单独设置过期时间,也可以控制实例内存上限
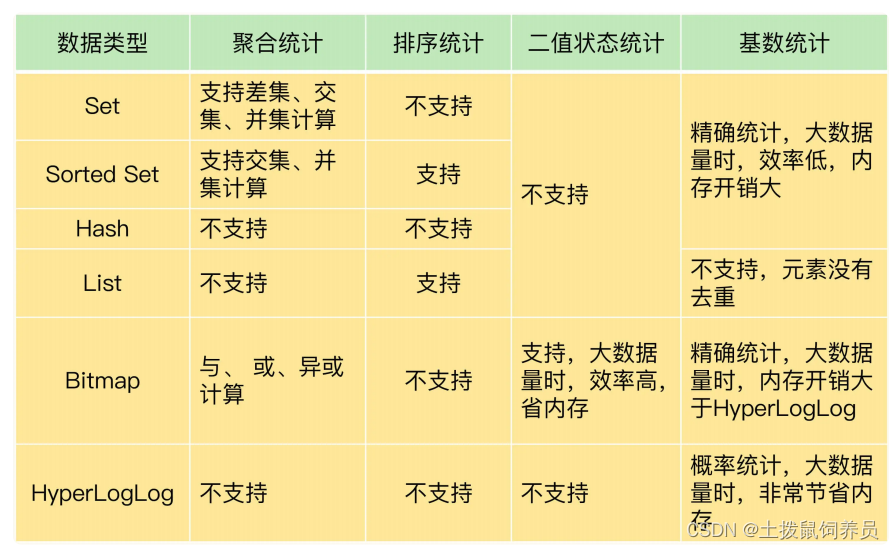
大数据量的统计
-
set的交,并, 差 计算复杂度高,会导致reids阻塞,可以选择一个从库,专门进行计算。
-
list 按照进入顺序排序,zset根据权重排序
-
二值状态,0 ,1类型 使用bitmap
-
HyperLogLog 适合基数统计,误差概率 0.81%
-
zadd online_users $timestamp $user_id统计一段时间在线的用户数zcount online_users $start_timestam p $end_timestamp -
sadd user1 apple orange banana、sadd user2 apple banana peach记录2个用户喜欢的水果,zunionstore fruits_union 2 user1 user2结果存储到fruits_union 中,zrange fruits_union 0 -1 withscores可以得出每种水果被喜欢的次数。 -
HyperLogLog的
pfcount page1:uv page2:uv page3:uv或pfmerge page_union:uv page1:uv page2:uv page3:uv得出3个页面的UV总和。 -
如果是在集群模式使用多个key聚合计算的命令,一定要注意,因为这些key可能分布在不同的实例上,多个实例之间是无法做聚合运算的,这样操作可能会直接报错或者得到的结果是错误的!
GEO格式
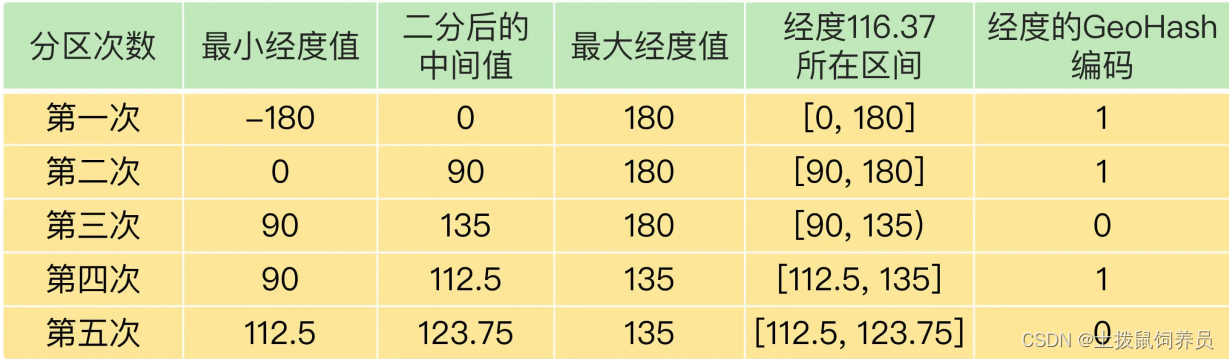
geo使用GeoHash编码,“二分区间,区间编码”
1.先对经度和纬度分别编码,然后再把经纬度各自的编码组合成一个最终编码
经度值 116.37,经度 编码[-180,180]。
纬度值 39.86,维度编码[-90,90]
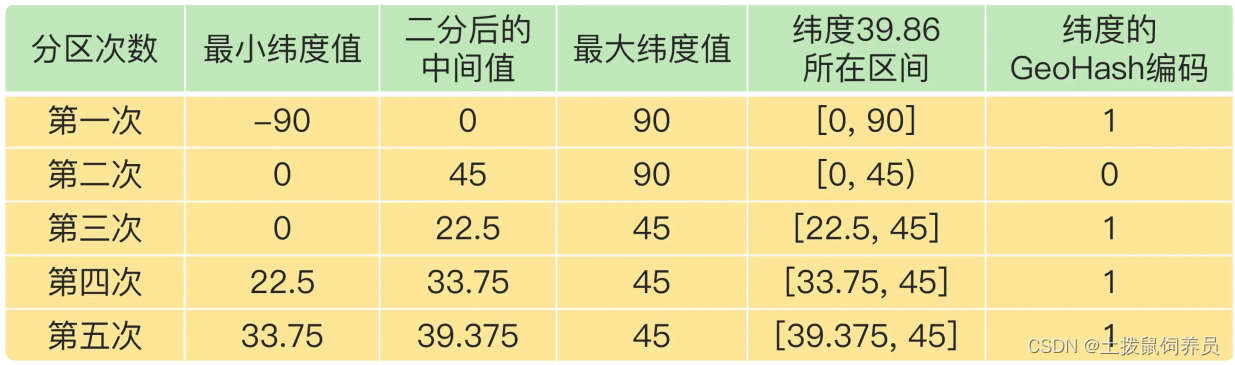
我们刚刚计算的经纬度(116.37,39.86)的各自编码值是 11010 和 10111,组合之后,第0 位是经度的第 0 位 1,第 1 位是纬度的第 0 位 1,第 2 位是经度的第 1 位 1,第 3 位是纬度的第 1 位 0,以此类推,就能得到最终编码值 1110011101,
GEO 类型是把经纬度所在的区间编码作为 Sorted Set 中元素的权重分数,把和经纬度相关的车辆 ID 作为 Sorted Set 中元素本身的值保存下来,这样相邻经纬度的查询就可以通过编码值的大小范围查询来实现了。
GEOADD cars:locations 116.034579 39.030452 33
GEORADIUS cars:locations 116.054579 39.030452 5 km ASC COUNT 10
在Redis中保存时间序列的数据
- Hash 类型来实现单键的查询很简单
- zset实现范围查询
上一篇:R语言基础(八):绘图函数
下一篇:数据科学复习学习