
【网络】Socket | RPC 通信细节 知识点
文章目录
- 序
- TCP拆包粘包问题
- 发生原因
- 解决方案
- 字节序 | 大小端模式 | 字节翻转
- 【拓】网络字节序
- 序列化器
- 服务发现
序
常用的两种通信方式,一种是HTTP通信,另一种就是Socket通信
- HTTP 是基于TCP Socket的高级封装,是一种简单易用的通信协议,使用时一般不会碰到底层问题。
- Socket 是操作系统提供的对于传输层(TCP/UDP)抽象的接口,使用时会接触到很多底层细节。
HTTP虽然方便,但性能较低。对性能有要求时,我们就需要直接使用 Socket编程 实现通信目的,加快传输效率,例如分布式服务间、游戏C/S端的高效、低延迟的通信需求。
Socket通信大多用于远程方法调用,即RPC。
目前有大量成熟可靠、高效的第三方RPC框架可供我们选择,如Dubbo、gRPC等等。这些RPC框架封装了拆包粘包、异常、超时等常见的传输细节,不需要程序员自己处理,相对得简单易用。但做为技术人员,如果长期对底层细节失去了解,对技术生涯或有不好的影响。所以本文的立意在于自己动手进行Socket编程(也可以说是手写RPC),而非借用现有的RPC库使用Socket。
直接进行Socket编程时,我们会遇到一些底层问题,以及一些可以或需要自己选择的东西(组件)。本文即旨在描述 Socket层 通信的重要事项和常见问题。
TCP拆包粘包问题
摘自:如何解决TCP拆包粘包问题
发生原因
- 应用程序写入的数据大于套接字缓冲区大小,这将会发生拆包。
- 应用程序写入数据小于套接字缓冲区大小,网卡将应用多次写入的数据发送到网络上,这将会发生粘包。
- 接收端不及时读取套接字缓冲区数据,这将发生粘包。
解决方案
无论拆包还是粘包,本质问题都是无法区分数据包的界限,解决包界限的问题主要有以下几种方式
1. 将数据包定长,比如定长100字节,不足补空格,接收端收到后按照100字节长度解析出的数据即为完整数据包。但这样的做的缺点是会有大量的空格,浪费部分存储空间和带宽。
2. 消息数据使用特定分割符区分界限,比如使用换行符号做分割。接收端读到该符号即知道接收到了一段完整数据
比如Java Netty中,LineBasedFrameDecoder解析器就是利用换行符号做分隔
3. 数据包用"包头"+"包体"组成
- 包头 包含了用来描述 包体等信息 的数据,比如包体长度、消息号(包体消息类型的唯一标识,作为对包体序列化和反序列化的依据)、包体解密密钥等数据。接收端收到后根据消息头中的长度解析一段完整的数据。
例如包头可以用一个uint16(最大能表示65535)来表示包体长度,同时也间接限制了包体不能草好过65535byte,即64k - 包体 即消息的主要内容,也叫消息体
字节序 | 大小端模式 | 字节翻转
字节序指的是多字节的数据(如int、float)中各字节的存储顺序。
在几乎所有计算机中,多字节数据被存储为连续的字节序列。例如,一个4字节的int类型变量a,其存储的起始地址为0x100,那么a的4个字节将被分别存在0x100,0x101,0x102,0x103的位置。实际上a的最低位可以存在最前面,也可以存在最后面。即有两种不同的存储顺序,也就是大端序和小端序。
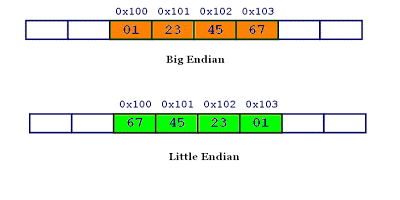
我们规定:①内存空间是从低地址(起始地址)到高地址排列的。②字节序的 左->右 对应的是 高位->低位。于是有:
- 大端序/模式 Big-Endian:将高位字节存储在起始地址(低地址)。高位字节在前,低位字节在后,这也符合人类的阅读习惯。
- 小端序/模式 Little-Endian:将低位字节存储在起始地址(低地址)。低位字节在前,高位字节在后。
(大端/小端模式也俗称大尾/小尾模式)
影响字节序的因素
1. CPU架构
字节序通常只和处理器架构有关,而和编程语言无关。比如PowerPC系列的CPU采用Big-Endian方式存储数据,而x86与x86_64系列则采用Little-Endian方式存储数据。很多的ARM、DSP都为小端模式,有些ARM处理器还可以由硬件来选择是大端模式还是小端模式。
平常大多数PC与服务器如果使用的是Intel与AMD CPU,一般都是Little-Endian
2. 有关写入字节的代码
除了处理器架构的关系外,也有一些需要程序员手写字节数据的场景。比如当我们遇到要把int转[]byte的情况时,可能会采用位移运算符的方式实现。这时也需要明确选择以大端模式写入还是小端模式写入,读取时也应使用同样的模式读取。
// 大端序
var b [4]byte
var i int32 = 65536
b[3] = byte(i)
b[2] = byte(i >> 8)
b[1] = byte(i >> 16)
b[0] = byte(i >> 24)
fmt.Println(b) // [0 1 0 0]// 小端序
var b [4]byte
var i int32 = 65536
b[0] = byte(i)
b[1] = byte(i >> 8)
b[2] = byte(i >> 16)
b[3] = byte(i >> 24)
fmt.Println(b) // [0 0 1 0]
PS:当我们使用某些二进制序列化器时,序列化器就帮我们完成了"手动写入字节数据"的过程。
Protobuf的消息总是使用小端模式。(以下是Protobuf生成的代码)
以上涉及到字节序的情况需要我们注意。因为计算机从字节流中取出数据,和把数据存入字节流时,如果不遵循同一种字节序,就无法取到正确的数据。
所以,在读写字节数据时,应当注意明确字节序
————
那有的同学可能就要问了,既然这么麻烦,为什么不统一字节序呢?
实际上,大小端各有优劣:
- 在计算机内部的处理都是小端字节序,因为计算都是从低位开始的,先处理低位字节效率较高。
- 而大端序存储的时候,由于符号位在高位,因此对于数据正负、大小的判断也就方便许多。另外,大端序也更符合人类的阅读习惯。
再由于各个芯片厂商的坚持,字节序的问题也就一直没有统一。
————
关于"大端"和"小端"叫法的由来,还有一则趣谈。
《程序设计实践》第9章中提到,“大端”和“小端”可以追溯到1726年的Jonathan Swift的《格列佛游记》,其中一篇讲到有两个国家因为吃鸡蛋究竟是先打破较大的一端还是先打破较小的一端而争执不休,他们分别被称为"大端(big-endian)派"和"小端(little-endian)派",因为这种争执,甚至爆发了战争,其中一个皇帝送了命,另一个丢了王位。
(看到没有,仅仅是剥鸡蛋就能产生这么大的分歧,原来“大端”和“小端”真的有这么重要!)
1981年10月,Danny Cohen的文章《论圣战以及对和平的祈祷》(On holy wars and a plea for peace)将这一对词语引入了计算机界。这么看来,所谓大端和小端,也就是big-endian和little-endian,其实就是从描述鸡蛋的部位而引申到计算机地址的描述,也可以说,是从一个俚语衍化来的计算机术语。稍有些英语常识的人都会知道,如果单靠字面意思来理解俚语,那是很难猜到它的正确含义的。在计算机里,对于地址的描述,很少用“大”和“小”来形容;对应地,用的更多的是“高”和“低”;很不幸地,这对术语直接按字面翻译过来就成了“大端”和“小端”,让人产生迷惑也不是很奇怪的事了。
【拓】网络字节序
主要参考 网络字节顺序
以上谈论的都是围绕"主机字节序",与之相对的还有"网络字节序"。主机字节序与CPU架构有关,而网络字节序与任何都无关
如果不使用c/c++编程,网络字节序通常不需要我们关心。
网络传输一般采用大端序,也被称之为网络字节序,或网络序。TCP/IP协议中定义大端序为网络字节序。
网络字节序是TCP/IP中的一个约定,它与具体的CPU类型、操作系统等无关,从而可以保证在不同主机之间建立连接和传输
为什么要有网络字节序?
解决好主机序的问题 仅仅能保证通信传输的业务内容可以被对方正确解析,而这些工作要先建立在网络传输的基础之上。
但是网络传输过程中不仅仅只涉及两台机器,我们无法知道通信过程中所有路由机器的主机序,所以要有一种约定的数序,而TCP/IP通过约定统一采用网络字节序(即大端序)的方式解决了这个问题。
网络字节序并不影响我们传输的字节数据,因为它们仅仅是传输内容,与TCP/IP的传输过程无关。
网络字节序仅作用于TCP/IP所关心的数据,如IP、Port等。
在网络编程时,一般用htonl()宏将本机序装换成网络序。消息传输过程中,TCP/IP总会按照大端序解析出目标IP和Port
// 相关代码片段
add.sin_family = AF_INET; // 协议簇。使用互联网际协议,即IP协议
add.sin_port = htons(11111); // 本机序转为网络序
(感觉网络字节序的问题其实是可以隐藏在Socket内的,不知道为什么没有那么做?)
Berkeley套接字定义了一组转换函数:htons(), ntohs(), htons(),htonl(),位于头文件
htons和ntohs完成16位无符号数的相互转换,htonl和ntohl完成32位无符号数的相互转换。
htons和htonl用于本机序转换到网络序,ntohl和ntohs用于网络序转换到本机序。
在使用little endian的系统中,这些函数会把字节序进行转换;
在使用big endian类型的系统中,这些函数会定义成空宏;
序列化器
序列化器(即序列化库)涉及到了"如何表示数据"这一问题。
Socket通信大多用于远程方法调用,即RPC。
通信的数据包括了传递给方法的参数,以及方法执行后的返回值。
进程内的方法调用,使用程序语言预置的和程序员自定义的数据类型,就很容易解决数据表示问题,远程方法调用则完全可能面临交互双方各自使用不同程序语言的情况;即使只支持一种程序语言的 RPC 协议,在不同硬件指令集、不同操作系统下,同样的数据类型也完全可能有不一样表现细节,譬如数据宽度、字节序的差异等等。有效的做法是将交互双方所涉及的数据转换为某种事先约定好的中立数据流格式来进行传输,将数据流转换回不同语言中对应的数据类型来进行使用,这个过程说起来拗口,但相信大家一定很熟悉,就是序列化与反序列化
(摘自凤凰架构-RPC-三个基本问题-如何表示数据)
常见的序列化格式有:XML、JSON、二进制等等。
- XML和JSON 会将程序对象序列化为字符串,所以序列化后依旧是人类可读的。进行网络传输时,字符串再转为二进制流传输。
反序列化时,字节数组转回字符串,即XML/JSON字符串,然后再用XML/JSON库转为程序对象 - 二进制序列化 会直接将程序对象序列化为二进制,虽然序列化后人类不可读,但效率是最高的。可直接用于网络传输。
- 如果是手写自定义的序列化,则应当有接口文档 描述接口有多少字段、字段的类型、顺序,对于不确定长度的字段(如string),要在写入值之前先把长度写入(类似于在数据包头中写入包体的长度)。反序列化时按文档描述解析即可。
—— 这是在没有protobuf前常用的方式 - 如果是用现成的第三方序列化器(如protobuf),则上述细节均由序列化器实现,不再需要手动解析,十分方便。
- 如果是手写自定义的序列化,则应当有接口文档 描述接口有多少字段、字段的类型、顺序,对于不确定长度的字段(如string),要在写入值之前先把长度写入(类似于在数据包头中写入包体的长度)。反序列化时按文档描述解析即可。
常见的序列化器,除了语言自带的原生序列化器,还有更高效的第三方序列化器,如fastjson、msgpack、protobuf等等。其中msgpack和protobuf都属于二进制序列化格式
如果不追求效率,那么直接使用json、xml这种简单易用、人类可读的序列化格式即可,并且他们还都是语言中立、平台中立的
如果追求效率,那就要选用二进制序列化格式。很多语言本身也提供有二进制序列化格式,如Java的java.io.Serializable,go的gob,但它们都无法跨语言反序列化。如果需要跨语言通信,则应当选择语言中立、平台中立的序列化。Google开发的protobuf即是比较推荐的一款
服务发现
要向某个服务器建立连接,需要知道它的ip和端口。找到服务对应的ip和端口的过程,就是服务发现。
HTTP 依靠DNS做服务发现。通过域名+DNS解析服务器的ip,默认80端口(如果要用其它端口,可以在服务端做反向代理)
而直接采用Socket通信(TCP/UDP)时,一般会使用中间件来保存服务的ip和端口,比如consul等"服务发现"中间件,甚至Redis等存储服务。
此处只简单提一下。详细可看服务发现-简书