
安装语音识别系统,从入门到实战
语音识别系统安装指南:从入门到实战
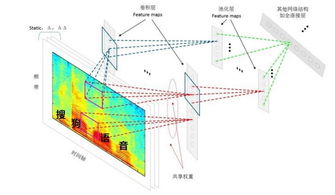
一、环境准备
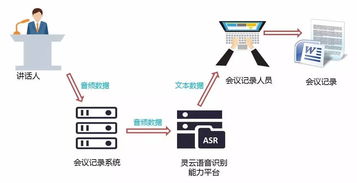
在开始安装语音识别系统之前,我们需要确保计算机满足以下基本条件:
操作系统:Windows、macOS或Linux
Python环境:Python 3.7及以上版本
GPU支持:CUDA支持的GPU(可选,但推荐,以提升模型的运行速度)
开发工具:Git、FFmpeg等
二、安装Python及相关依赖

首先,确认您的系统中已安装Python 3.7及以上版本。如果没有,请前往Python官网下载并安装。接下来,我们将使用Miniconda来管理Python环境。
下载并安装Miniconda:https://docs.conda.io/en/latest/miniconda.html
打开终端,创建一个新的虚拟环境:
激活虚拟环境:
安装必要的Python包,如torch、torchaudio等:
三、安装PyTorch
Whisper依赖于PyTorch,因此需要先安装它。根据您的系统配置,选择合适的安装命令。
对于使用CUDA的安装命令,请参考PyTorch官网:https://pytorch.org/get-started/locally/
如果不使用GPU,可以直接使用以下命令:
四、安装Whisper
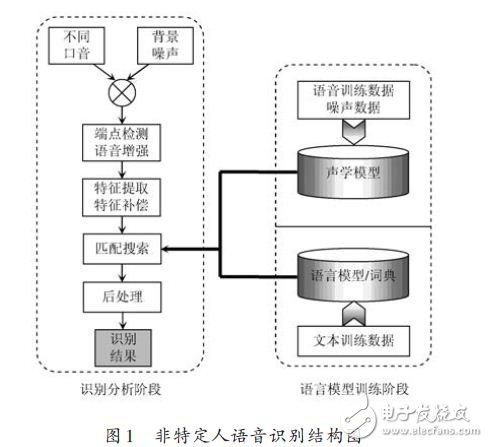
打开终端,运行以下命令来克隆和安装Whisper:
克隆Whisper的GitHub仓库:
进入Whisper目录:
安装Whisper所需的Python包依赖:
五、安装FFmpeg
Whisper依赖于FFmpeg进行音频处理,因此需要确保已安装FFmpeg。
在macOS上:
在Ubuntu上:
在Windows上,可以从FFmpeg官网下载并配置路径。
六、运行Whisper
完成上述步骤后,您就可以运行Whisper进行语音转文本任务了。
打开终端,运行以下命令:
选择一个音频文件进行语音识别:
查看识别结果:
通过以上步骤,您已经成功安装了一个基本的语音识别系统。接下来,您可以进一步学习如何使用该系统进行语音识别、语音合成等任务。祝您学习愉快!