
【Day3】链表理论基础、203移除链表元素、707设计链表、206反转链表
【Day3】链表理论基础、203移除链表元素、707设计链表、206反转链表
- 链表理论基础
- 链表的类型
- 链表的存储方式
- 链表的定义
- 链表的操作
- 203 移除链表元素
- 设置虚拟头节点
- 无虚拟头节点
- 707设计链表
- 206反转链表
- 双指针法
- 递归法
- while和for
链表理论基础
链表是一种通过指针串联在一起的线性结构,每一个节点由两部分组成,一个是数据域一个是指针域(存放指向下一个节点的指针),最后一个节点的指针域指向null(空指针的意思)。
链表的入口节点称为链表的头结点也就是head。
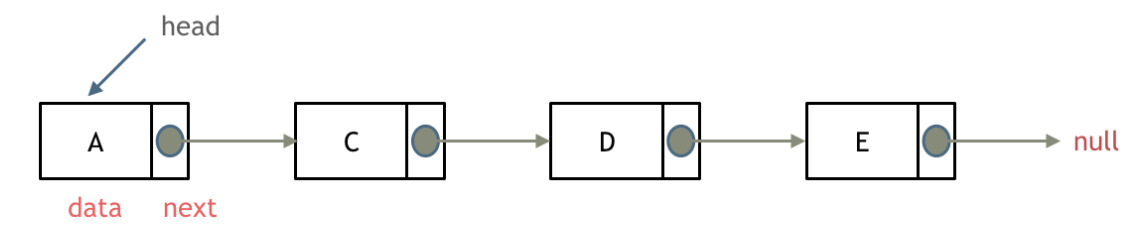
链表的类型
链表的类型:单链表、双链表、循环链表
单链表:上面的就是
双链表:每一个节点有两个指针域,一个指向下一个节点,一个指向上一个节点。
双链表 既可以向前查询也可以向后查询。

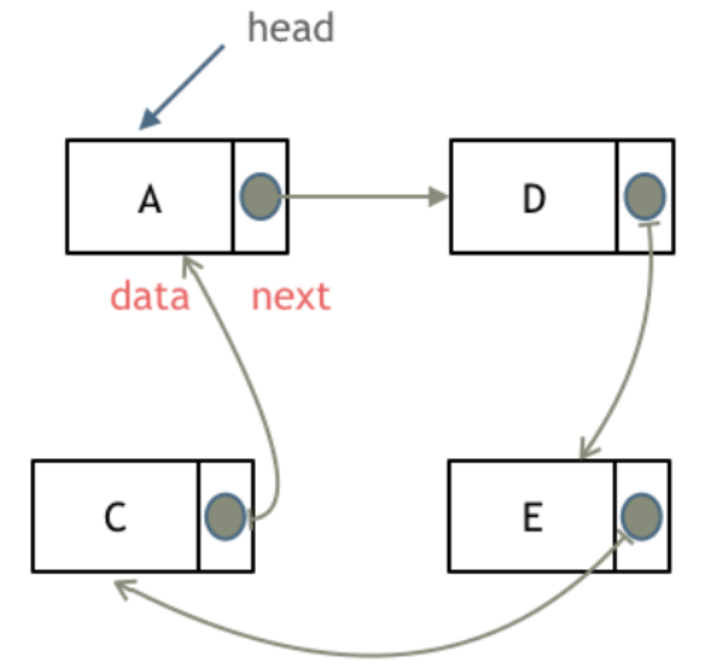
循环链表:链表首位相连,可以用来解决约瑟夫环问题。
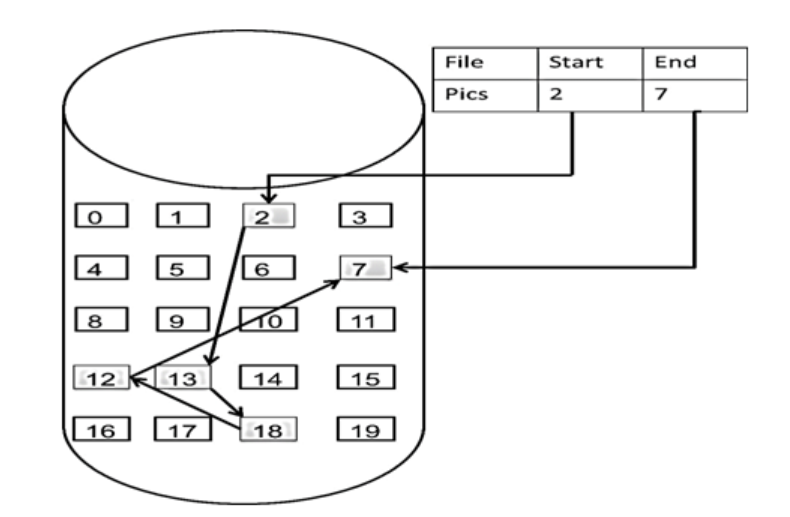
链表的存储方式
数组是在内存中是连续分布的,但是链表在内存中可不是连续分布的。
链表是通过指针域的指针链接在内存中各个节点。
所以链表中的节点在内存中不是连续分布的 ,而是散乱分布在内存中的某地址上,分配机制取决于操作系统的内存管理。
如图:这个链表起始节点为2, 终止节点为7, 各个节点分布在内存的不同地址空间上,通过指针串联在一起。
链表的定义
// 单链表 C++
struct ListNode {int val; // 节点上存储的元素ListNode *next; // 指向下一个节点的指针ListNode(int x) : val(x), next(NULL) {} // 节点的构造函数
}
链表的操作
删除节点
删除D节点,如图所示:
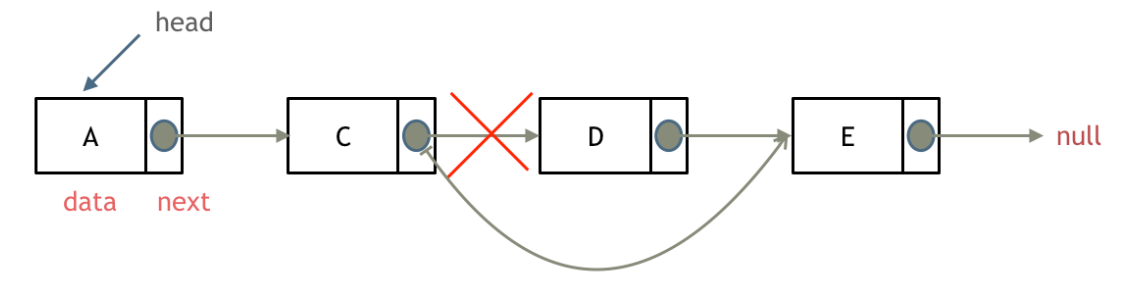
删除D节点,只要将C节点的next指针 指向E节点就可以了。
但D节点依然存留在内存里,只不过是没有在这个链表里而已。所以在C++里最好是再手动释放这个D节点,释放这块内存。
其他语言例如Java、Python,就有自己的内存回收机制,就不用自己手动释放了。
添加节点
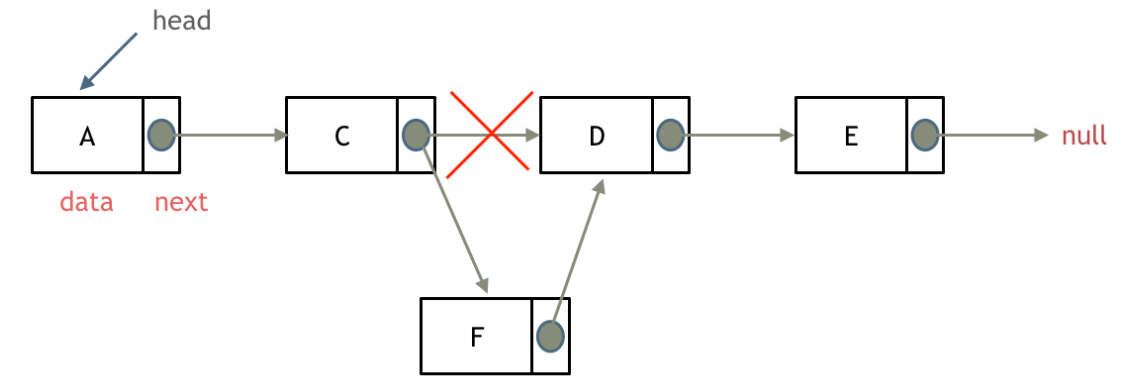
性能分析
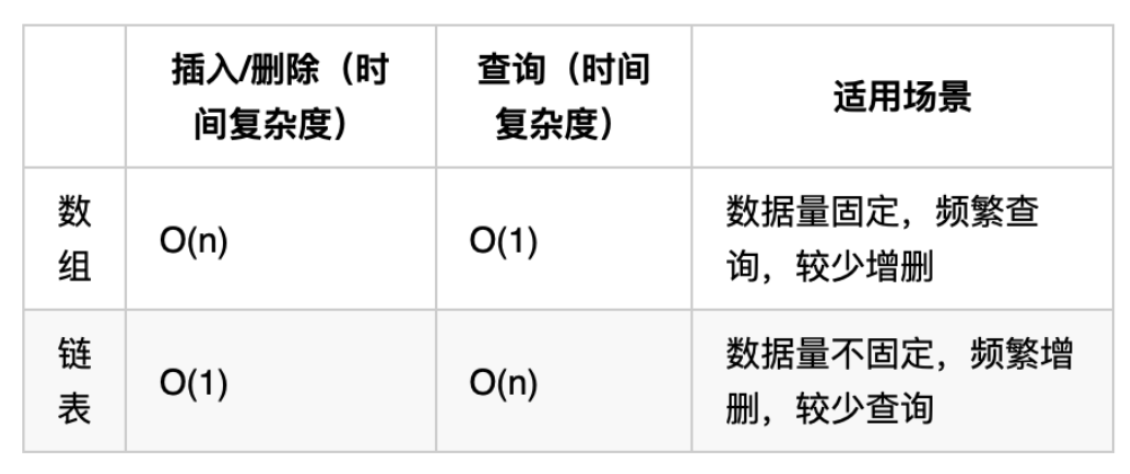
数组在定义的时候,长度就是固定的,如果想改动数组的长度,就需要重新定义一个新的数组。
链表的长度可以是不固定的,并且可以动态增删, 适合数据量不固定,频繁增删,较少查询的场景。
203 移除链表元素
题目链接:203
题目:给你一个链表的头节点 head 和一个整数 val ,请你删除链表中所有满足 Node.val == val 的节点,并返回 新的头节点 。
使用C++来做leetcode,如果移除一个节点之后,没有手动在内存中删除这个节点,leetcode依然也是可以通过的,只不过,内存使用的空间大一些而已,但建议依然要养成手动清理内存的习惯。
链表操作的两种方式:
- 直接使用原来的链表来进行删除操作。
- 设置一个虚拟头结点在进行删除操作。
设置虚拟头节点
建议使用虚拟头节点 这样无论移除的元素是不是头节点,都可以按照一种方式操作。
设置一个虚拟头结点在进行移除节点操作:
class Solution {
public:ListNode* removeElements(ListNode* head, int val) {ListNode* dummyHead = new ListNode(0); // 设置一个虚拟头结点dummyHeaddummyHead->next = head; // 将虚拟头结点指向head,这样方面后面做删除操作ListNode* cur = dummyHead; //设置临时指针current 来遍历链表 cur指向临时头节点while (cur->next != NULL) {if(cur->next->val == val) {cur->next = cur->next->next;} else { cur = cur->next; //如果没有找到目标值,cur就继续遍历}}return dummyHead->next; //返回虚拟节点的下一个 才是新链表的头节点delete dummyHead; //删除虚拟节点}
};
无虚拟头节点
没有设置虚拟头节点,就需要考虑要删除的元素是不是头节点,如果要删除的元素是头节点,那么把头节点向后移一位,进行删除操作;如果删除的元素不是头节点,就照常删除链表元素。
class Solution {
public:ListNode* removeElements(ListNode* head, int val) {// 删除头结点while (head != NULL && head->val == val) { // 注意这里不是ifListNode* tmp = head;head = head->next;delete tmp;}// 删除非头结点ListNode* cur = head;while (cur != NULL && cur->next!= NULL) {if (cur->next->val == val) {ListNode* tmp = cur->next;cur->next = cur->next->next;delete tmp;} else {cur = cur->next;}}return head;}
};
707设计链表
【经典题型】
题目链接:707
题目:
设计链表的实现。您可以选择使用单链表或双链表。单链表中的节点应该具有两个属性:val 和 next。val 是当前节点的值,next 是指向下一个节点的指针/引用。如果要使用双向链表,则还需要一个属性 prev 以指示链表中的上一个节点。假设链表中的所有节点都是 0-index 的。
在链表类中实现这些功能:
get(index):获取链表中第 index 个节点的值。如果索引无效,则返回-1。
addAtHead(val):在链表的第一个元素之前添加一个值为 val 的节点。插入后,新节点将成为链表的第一个节点。
addAtTail(val):将值为 val 的节点追加到链表的最后一个元素。
addAtIndex(index,val):在链表中的第 index 个节点之前添加值为 val 的节点。如果 index 等于链表的长度,则该节点将附加到链表的末尾。如果 index 大于链表长度,则不会插入节点。如果index小于0,则在头部插入节点。
deleteAtIndex(index):如果索引 index 有效,则删除链表中的第 index 个节点。
index是从0开始的
需要专门定义一个临时指针current来遍历链表。而不是直接操作头指针
因为操作完链表后要返回头节点,如果一开始就操作头节点,那头节点的值都改了,无法返回链表的头节点。
代码如下
class MyLinkedList {
public:// 定义链表节点结构体struct LinkedNode {int val;LinkedNode* next;LinkedNode(int val):val(val), next(nullptr){}};// 初始化链表MyLinkedList() {_dummyHead = new LinkedNode(0); // 这里定义的头结点 是一个虚拟头结点,而不是真正的链表头结点_size = 0;}// 获取到第index个节点数值,如果index是非法数值直接返回-1, 注意index是从0开始的,第0个节点就是头结点int get(int index) { if (index > (_size - 1) || index < 0) { //index不能小于0 不能大于size-1return -1;}LinkedNode* cur = _dummyHead->next; //设置临时指针cur 指向真实的头节点while(index--){ // 如果--index 就会陷入死循环cur = cur->next; //遍历找index}return cur->val;}// 在链表最前面插入一个节点,插入完成后,新插入的节点为链表的新的头结点//这里应该先让newnode的next指向虚拟头节点的next_dummyHead->next;再让虚拟头节点dummyHead->next指向newnodevoid addAtHead(int val) { LinkedNode* newNode = new LinkedNode(val); //创建一个新节点newnodenewNode->next = _dummyHead->next; // newNode的next指向实际的头节点 就是虚拟节点的next_dummyHead->next = newNode; //虚拟头节点指向这个Node,_size++;}// 在链表最后面添加一个节点void addAtTail(int val) {LinkedNode* newNode = new LinkedNode(val); //先定义一个新节点LinkedNode* cur = _dummyHead; //当前的遍历节点指向尾部while(cur->next != nullptr){ //cur的next不为空就一直遍历,直到为空是cur指向尾部cur = cur->next; //遍历}cur->next = newNode; _size++;}// 在第index个节点之前插入一个新节点,例如index为0,那么新插入的节点为链表的新头节点。// 如果index 等于链表的长度,则说明是新插入的节点为链表的尾结点// 如果index大于链表的长度,则返回空// 如果index小于0,则在头部插入节点//在第index前插入一个节点,一定要知道index前一个节点的指针。cur为index的前一个节点,cur->next是第index节点void addAtIndex(int index, int val) {if(index > _size) return;if(index < 0) index = 0; LinkedNode* newNode = new LinkedNode(val); //newnode是要插入的节点LinkedNode* cur = _dummyHead;while(index--) {cur = cur->next; }newNode->next = cur->next;cur->next = newNode;_size++;}// 删除第index个节点,如果index 大于等于链表的长度,直接return,注意index是从0开始的//删除第index个节点,cur-next是index,cur是index的前一个节点void deleteAtIndex(int index) {if (index >= _size || index < 0) {return;}LinkedNode* cur = _dummyHead;while(index--) {cur = cur ->next;}LinkedNode* tmp = cur->next;cur->next = cur->next->next;delete tmp;_size--;}// 打印链表void printLinkedList() {LinkedNode* cur = _dummyHead;while (cur->next != nullptr) {cout << cur->next->val << " ";cur = cur->next;}cout << endl;}
private:int _size;LinkedNode* _dummyHead;
};206反转链表
【面试高频题】
题目链接:206
题目:
给你单链表的头节点 head ,请你反转链表,并返回反转后的链表。
示例: 输入: 1->2->3->4->5->NULL 输出: 5->4->3->2->1->NULL
双指针法
class Solution {
public:ListNode* reverseList(ListNode* head) {ListNode* temp; // 保存cur的下一个节点ListNode* cur = head;ListNode* pre = NULL;while (cur) { //当cur指向null 遍历结束temp = cur->next; // 保存一下 cur的下一个节点,因为接下来要改变cur->nextcur->next = pre; // 翻转操作// 更新pre 和 cur指针pre = cur;cur = temp;}return pre;}
};
递归法
归法相对抽象一些,但是其实和双指针法是一样的逻辑,同样是当cur为空的时候循环结束,不断将cur指向pre的过程。
关键是初始化的地方,可以看到双指针法中初始化 cur = head,pre = NULL,在递归法中可以从如下代码看出初始化的逻辑也是一样的,只不过写法变了。
class Solution {
public:ListNode* reverse(ListNode* pre,ListNode* cur){if(cur == NULL) return pre;ListNode* temp = cur->next;cur->next = pre;// 可以和双指针法的代码进行对比,如下递归的写法,其实就是做了这两步// pre = cur;// cur = temp;return reverse(cur,temp);}ListNode* reverseList(ListNode* head) {// 和双指针法初始化是一样的逻辑// ListNode* cur = head;// ListNode* pre = NULL;return reverse(NULL, head);}};
while和for
while可以干的事情,for都可以干,就是写起来会别扭一下。一般来说,while擅长于条件控制的循环,for擅长起始位置和终止位置固定好的循环,当你的循环条件没有收尾终止的时候,可以想一想while。
for循环适合已知循环次数的操作,while循环适合未知循环次数的操作。
for循环执行末尾循环体后将再次进行条件判断,若条件还成立,则继续重复上述循环,当条件不成立时则跳出当下for循环。
while循环当满足条件时进入循环,进入循环后,当条件不满足时,执行完循环体内全部语句后再跳出(而不是立即跳出循环)。
for循环的目的是为了限制循环体的执行次数,使结果更精确。
while循环的目的是为了反复执行语句或代码块。
上一篇:Acwing——第二场热身赛
下一篇:node.js全栈项目