
[MySQL核心]3.连接查询
MySQL核心--连接查询
- 内连接查询
- 关于内连接查询的执行过程
- 外连接查询
- left连接查询
- right连接查询
- 外连接和内连接的区别
一个SQL语句查询多表
场景一:
// 学生信息表
CREATE TABLE student
(uid INT UNSIGNED NOT NULL PRIMARY KEY AUTO_INCREMENT,name VARCHAR(50) NOT NULL,age TINYINT NOT NULL,sex ENUM('M','W') NOT NULL
)ENGINE=INNODB,DEFAULT CHARSET=utf8;// 课程信息表
CREATE TABLE course
(cid INT UNSIGNED NOT NULL PRIMARY KEY AUTO_INCREMENT,cname VARCHAR(50) NOT NULL,credit FLOAT UNSIGNED NOT NULL
)ENGINE=INNODB,DEFAULT CHARSET=utf8;// 考试信息表
CREATE TABLE exame
(uid INT UNSIGNED NOT NULL,cid INT UNSIGNED NOT NULL,time DATE NOT NULL,score FLOAT UNSIGNED NOT NULL,PRIMARY KEY(uid,cid)
)ENGINE=INNODB,DEFAULT CHARSET=utf8;
// 查看各表结构
desc 表名;
添加一些数据
INSERT INTO student(name,age,sex) VALUES
('zhangsan',18,'M'),
('gaoyang',20,'W'),
('chenwei',22,'M'),
('linfeng',21,'W'),
('liuxiang',19,'W');INSERT INTO course(cname,credit) VALUES
('C++基础课程', 5.0),
('C++高级课程', 10.0),
('C++项目开发',8.0),
('C++算法课程',12.0);INSERT INTO exame(uid,cid,time,score) VALUES
(1,1,'2021-04-19',99.0),
(1,2,'2021-04-10',80.0),
(2,2,'2021-04-10',90.0),
(2,3,'2021-04-12',85.0),
(3,1,'2021-04-09',56.0),
(3,2,'2021-04-10',93.0),
(3,3,'2021-04-12',89.0),
(3,4,'2021-04-11',100.0),
(4,4,'2021-04-11',99.0),
(5,2,'2021-04-10',59.0),
(5,3,'2021-04-12',94.0),
(5,4,'2021-04-11',95.0);
内连接查询
内连接查询student表和exame表
// 我们先写出单表查询的SQL语句
select a.name,a.age,a.sex from student a where a.uid=1;
select c.score from exame c where c.uid=1 and c.cid=2; // 内连接查询(查student表和exame表)
// 把student表和exame表都起了一个别名,避免出现两个表中字段重复,MySQL Server无法识别的情况
// on a.uid=c.uid 是用来根据数据量来区分大表和小表,数据量大的为大表,小表永远是整表扫描,然后去大表搜索,所以要在大表上建立索引
// 在这里a是小表,所以在a上整表扫描,取出所有a.uid,然后拿着这些uid到exame大表中去搜索
// 最后再加上where限制条件
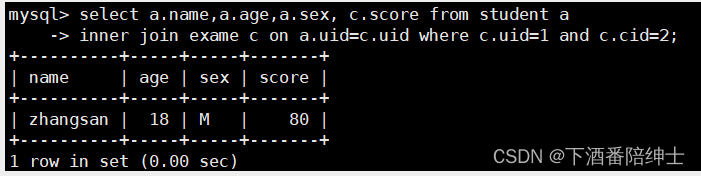
select a.name,a.age,a.sex, c.score from student a
inner join exame c on a.uid=c.uid where c.uid=1 and c.cid=2;
进一步的我们想要内连接查询student表、course表和exame表
// 对于course表的单表查询
select b.cid,b.cname,b.credit from course b where b.cid=2;// 把对course表的单表查询语句和上面两张表的连接查询再联合起来,我们需要利用exame表来连接student表和course表,所以exame表放在最开始
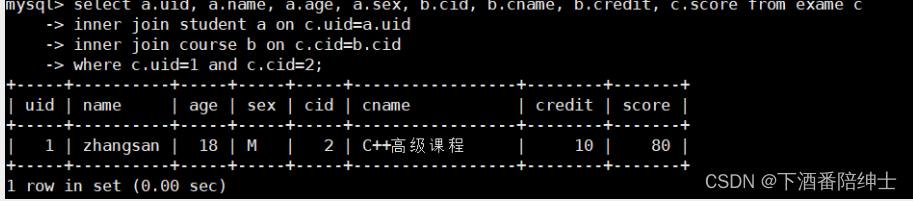
select a.uid, a.name, a.age, a.sex, b.cid, b.cname, b.credit, c.score from exame c
inner join student a on c.uid=a.uid
inner join course b on c.cid=b.cid
where c.uid=1 and c.cid=2;
结合limit
select * from t_user limit 1500000,10;
select id from t_user limit 1500000,10;// 查询性能和select后面的字段是相关的

// 有时是可以使用分页查询中的方法,加入含索引字段的限制条件来过滤数据where id>1500000,来实现高效查询
// 但是很多时候我们并不知道id值是多少,我们又希望能够获取(id,email,password字段)并且有不错的查询效率,我们可以这么做select a.id, a.email, a.password from t_user a
inner join (select id from t_user limit 1500000,10) b on a.id=b.id;

可以看到查询效率有了不少的提升

来点练习
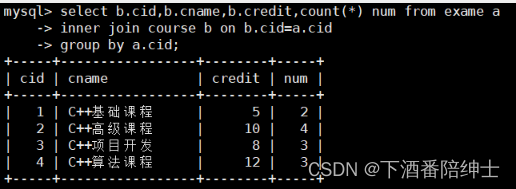
- 统计每门课程的考试人数(显示课程基本信息和考试人数)
// count(*) num 重新命名为num
select b.cid,b.cname,b.credit,count(*) num from exame a
inner join course b on b.cid=a.cid
group by a.cid;
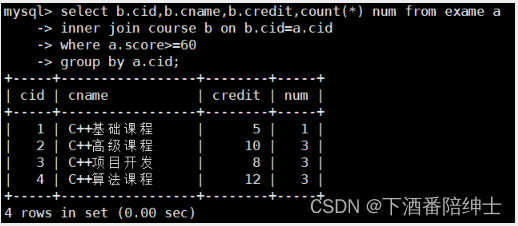
// 统计每门课程考试成绩>=60的人数
select b.cid,b.cname,b.credit,count(*) num from exame a
inner join course b on b.cid=a.cid
where a.score>=60 // 先筛选再分组
group by a.cid;
select b.cid,b.cname,b.credit,count(*) num from exame a
inner join course b on b.cid=a.cid
where a.score>=60
group by a.cid
order by num desc;

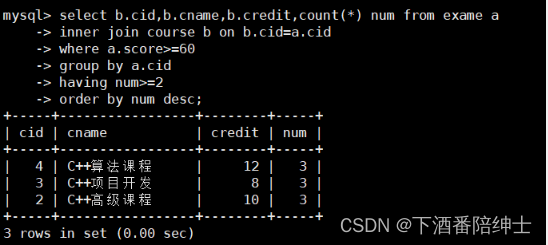
// 显示考试成绩>=60的人数>=2人的课程
select b.cid,b.cname,b.credit,count(*) num from exame a
inner join course b on b.cid=a.cid
where a.score>=60
group by a.cid
having num>=2
order by num desc;
- cid=2这门课程考试成绩的最高分的学生信息和课程信息
select c.uid,c.name, c.age, c.sex, b.cid, b.cname, b.credit, a.score from exame a
inner join course b on a.cid=b.cid
inner join student c on a.uid=c.uid
where a.cid=2;- cid=2这门课程的考试平均成绩&每门课程考试的平均成绩+课程信息
场景二:用户、商品、订单四张表
…
关于内连接查询的执行过程
select a.uid, a.name, a.age, a.sex, b.cid, b.cname, b.credit, c.score from exame c
inner join student a on c.uid=a.uid
inner join course b on c.cid=b.cid
where c.uid=1 and c.cid=2;// 以上面的SQL语句为例,MySQL Server首先执行的是where条件进行过滤,而过滤之后再根据数据量区分大小表(注意这里大小表是根据过滤后的结果来作区分),在小表上整表扫描,然后去大表进行搜索
// 注意使用explain查看执行计划
// 1
select a.name,a.age,a.sex, c.score from student a
inner join exame c on a.uid=c.uid where c.uid=1;// 2
select a.name,a.age,a.sex, c.score from student a
inner join exame c on a.uid=c.uid and c.uid=1;// 执行explain我们可以看到1,2的执行是一样的,也就是说对于inner join把过滤条件写到on连接里面和写到where后面,效果是一样的

外连接查询

外连接的应用场景主要是找一张表有,另一张没有的数据,比如下面的谁没有参加考试类似的场景
预置条件:
(1)场景一
// 在学生信息表中添加一个新的学生信息
INSERT INTO student(name,age,sex) VALUES('lihua',23,'M');
left连接查询
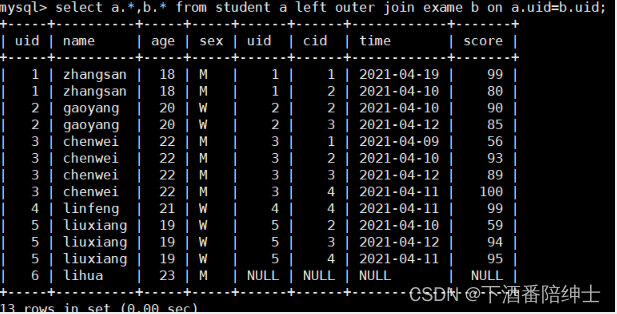
// 把left这边的表中的所有数据都显示出来,在右表中不存在的相应数据,则显示为空(NULL)
// 新添加的学生还没有考试信息,所以这部分信息都为NULL
select a.*,b.* from student a left outer join exame b on a.uid=b.uid;
right连接查询
// 显示右表的数据,如果左表中不存在相应的数据,则显示为空
select a.*, b.* from student a right outer join exame b on a.uid=b.uid;
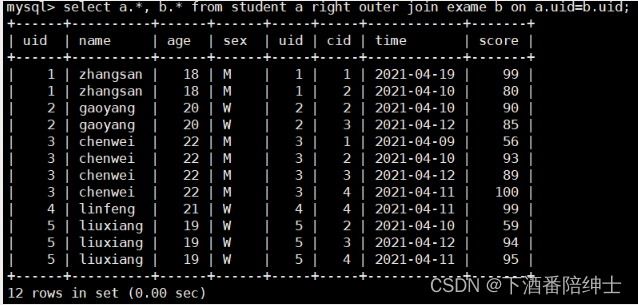

从上面截图可以看到,这个右连接查询的执行过程是先在右表上进行扫描,然后在左表上进行搜索,搜索的时候用到了左表的主键索引字段,提高查找效率,(左连接查询同理,先扫描左表,然后搜索右表);
和内连接查询inner join不一样,并不是根据数据量区分大小表后,对小表整表扫描,然后搜索大表
现在我想知道有哪些学生没有参加考试:
// 方式1
select a.* from student a where a.uid not in (select distinct b.uid from exame b);// select distinct b.uid from exame b ==>可能会产生一张中间临时表供外部sql查询(也可能不会产生中间表,MySQL Server会进行优化)
// not in 对于索引的命中并不高(in用得到索引,not in 并非用不到索引,而是要看select后面跟的列)
// 我们都可以使用explain查看执行过程// 方式2
select a.* from student a
left outer join exame b on a.uid=b.uid
where b.uid is NULL; // 注意这里要用is[NOT] NULL ,不能用b.uid=NULL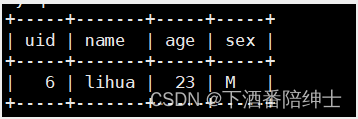
我们执行explain查看方式2的执行过程:
explain select a.* from student a
left outer join exame b on a.uid=b.uid
where b.uid is NULL;

可以看到先在左表上进行整表扫描(type:ALL),然后将左表上取出的结果(a.uid)到右表上进行搜索,搜索时执行过滤条件,利用右表上的索引字段(联合主键)优化查询过程
外连接和内连接的区别
//1
select a.*,b.* from student a
left outer join exame b on a.uid=b.uid
where b.cid = 3;//2
select a.*,b.* from student a
left outer join exame b on a.uid=b.uid and b.cid = 3;
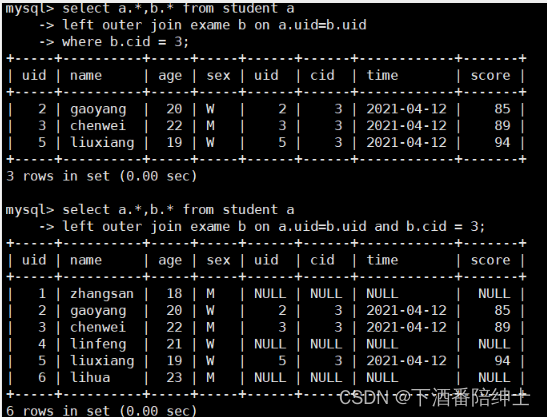
可以看到两种方式执行后得到的结果是不一样的,1的结果和内连接查询一样了,而2才是我们想要的外连接查询,我们可以进一步通过explain加以验证:
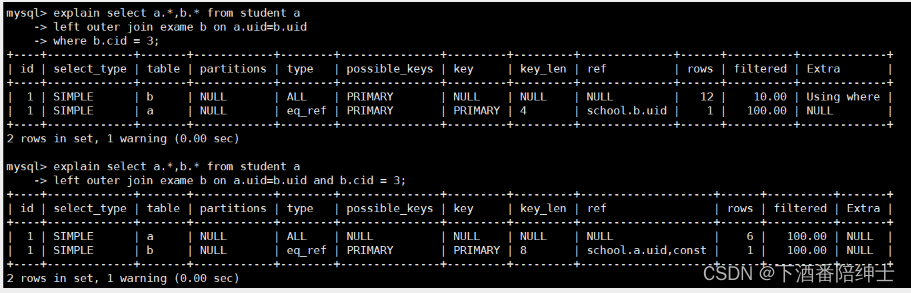
方式1和内连查询的过程是完全一致的,都是where条件先进行过滤,然后根据数据量区分大小表后,扫描小表,然后到大表上搜索;
而方式2就是先在左表上进行扫描,然后拿扫描后的uid去右表上搜索,如果右表上没有相应的数据就置为NULL
然后我们再加上判空的where条件去过滤数据,得到的是没有去参加cid=3课程的学生信息
select a.* from student a
left outer join exame b on a.uid=b.uid and b.cid = 3
where b.cid is NULL;
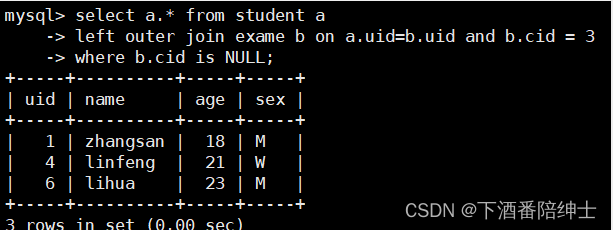
查看执行过程:

所以对于外连接where过滤条件只写NULL值判断,其他条件过滤都写到on后面;
对于外连接如果on后面只写连接条件,而过滤条件都写到where后面,那么外连接和内连接就一样了
对于内连接,过滤条件写到on后面还是where后面都一样,实际上MySQL Server执行内连接时会把写到on 后面的过滤条件写成where条件
这也是外连接和内连接的一大区别