
java -- stream流
stream流一直在使用,但是感觉还不够精通,现在深入研究一下。 stream这个章节中,会用到
函数式接口–lambda表达式–方法引用的相关知识
介绍
是jdk8引进的新特性。
stream流是类似一条流水线一样的操作,每次对数据进行一个操作。
可以简化操作
我觉得还是以官方文档来说比较好
官方介绍
部分分散到后面去了,有的我用我自己的话换了一下
初步介绍
支持顺序和并行聚合操作的元素序列。以下示例说明了使用 和 IntStream的Stream聚合操作:
int sum = widgets.stream() .filter(w -> w.getColor() == RED).mapToInt(w -> w.getWeight()).sum();
在此示例中, widgets是一个单列集合。我们通过创建一个Collection.stream()对象流,过滤它以生成仅包含红色小部件的流 Widget,然后将其转换为代表每个红色小部件权重的值流 int。然后将此流相加以生成总重量。
流的组成
为了执行计算,流操作被组合到流管道中。
流管道组成:
- 源(可能是数组、集合、生成器函数、I/O 通道等)
- 零个或多个中间操作
- 一个终端操作组成。
流是懒惰的;仅在启动终端操作时对源数据执行计算,并且仅在需要时使用源元素。
实现
没看懂
流实现在优化结果计算方面允许很大的自由度。例如,流实现可以自由地从流管道中执行操作(或整个阶段),因此可以免除行为参数的调用,如果它可以证明它不会影响计算结果。这意味着行为参数的副作用可能并不总是被执行,也不应该被依赖,除非另有规定(例如通过终端操作 forEach 和 forEachOrdered)。
和集合的区别
集合和流虽然具有一些表面上的相似之处,但具有不同的目标。
流主要关注其元素的有效管理和访问。相比之不提供直接访问或操作其元素的方法,而是关注以声明方式描述其源以及将在该源上聚合执行的计算操作。但是,如果提供的流操作不提供所需的功能,则和 iterator() spliterator() 操作可用于执行受控遍历。
并发
流管道可以被视为对流源的查询。除非源明确设计为并发修改(例如 ConcurrentHashMap),否则在查询流源时修改流源可能会导致不可预测或错误的行为。
除了明确说可以修改的,一般都可以对其进行修改,向迭代器一样,下面是对上面的解释
大多数流操作接受描述用户指定行为的参数,例如在上面的示例中传递给 mapToInt的 lambda 表达式 w -> w.getWeight()。为了保持正确的行为,这些行为参数:
必须是非干扰的(它们不修改流源);和
在大多数情况下,必须是无状态的(其结果不应依赖于在流管道执行期间可能更改的任何 状态 )。
参数
此类参数始终是函数接口(如 Function)的实例,并且通常是 lambda 表达式或方法引用。除非另有指定,否则这些参数必须为非空值。
一个流只能操作一次(调用中间流或终端流操作)。
不可用重复操作,stream对象不可用第二次,所以我们一般使用链式编程。
例如,这排除了“分叉”流,其中同一源馈送两个或多个管道,或同一流的多个遍历。如果流实现检测到流正在重用,则可能会引发 IllegalStateException 。但是,由于某些流操作可能会返回其接收器而不是新的流对象,因此可能无法在所有情况下都检测到重用。
最后
流有一个 close() 方法并实现 AutoCloseable.在流关闭后对其进行操作将引发 IllegalStateException。
自动关闭
大多数流实例在使用后实际上并不需要关闭,因为它们由集合、数组或生成函数支持,不需要特殊的资源管理。通常,只有源为 IO 通道的流(例如 返回 Files.lines(Path)的流)才需要关闭。如果流确实需要关闭,则必须在 try-with-resources 语句或类似控制结构中将其作为资源打开,以确保在其操作完成后立即关闭它。
流管道可以按顺序或并行执行。此执行模式是流的属性。流是通过顺序执行或并行执行的初始选择创建的。
(例如,创建一个顺序流, Collection.stream() 并 Collection.parallelStream() 创建一个并行流。这种执行模式的选择可以由 or sequential() parallel() 方法修改,也可以用该方法 isParallel() 查询。
获取stream流
双列集合是不可用直接获取的。
| 数据类型 | 获取方法 |
|---|---|
| 数组 | Arrays.stream(数组); |
| 单列集合 | 直接调用Collection的stream方法 |
| 双列集合 | 转换为单列在获取,如keyset/entryset |
| 零散数据 | stream.of(T…values); |
数组

单列集合

双列集合
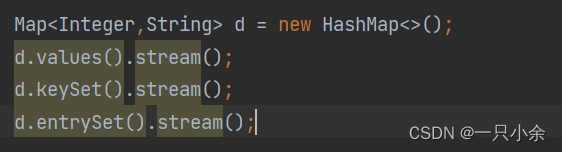
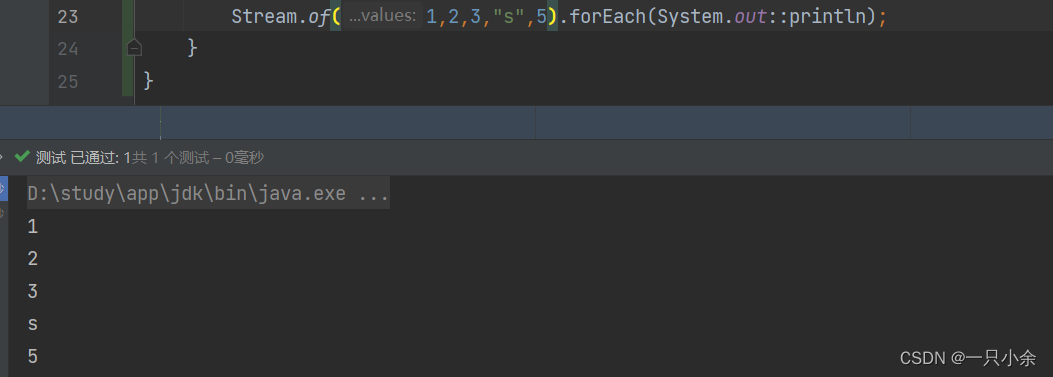
零散数据
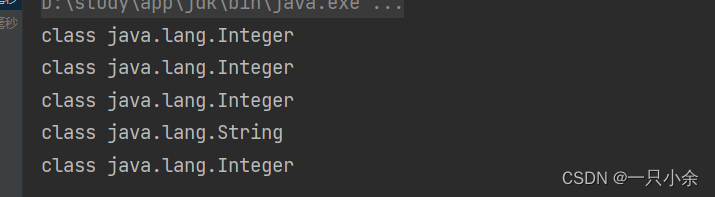
不过不理解为什么不是一个类型也可以

获取其class对象,发现就是不同类型
除了 Stream对象引用流之外,还有LongStream和 的IntStream原始专用化,所有这些都称为“流”,并符合此处描述的特征和DoubleStream限制。
那么如果固定类型的话
选取固定的stream来进行封装
方法
中间方法
filter
过滤,只保留符合条件的数据
Stream filter(Predicate predicate);

limit
限制流元素的大小
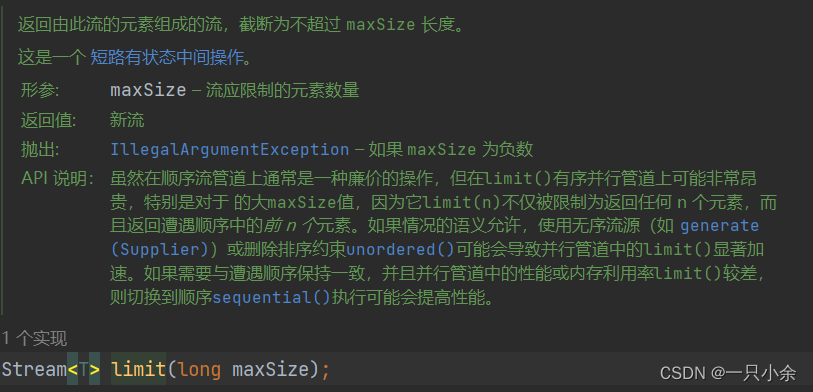
skip
舍弃前面的n个元素,如果少于n则返回空流

limit和skip可以组合使用,获取n-maxsize中的元素
distinct
去重,依靠hashcode和equals

依靠hashset去重
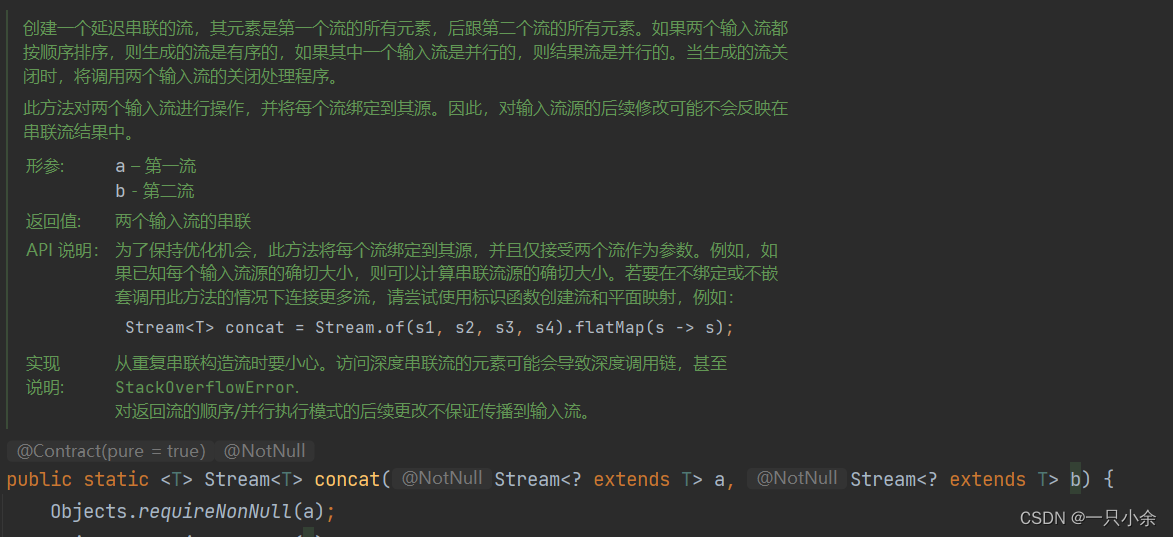
concat
将2个流合成一个
静态方法,需要类名调用
map
类型转换/对每一个进行操作
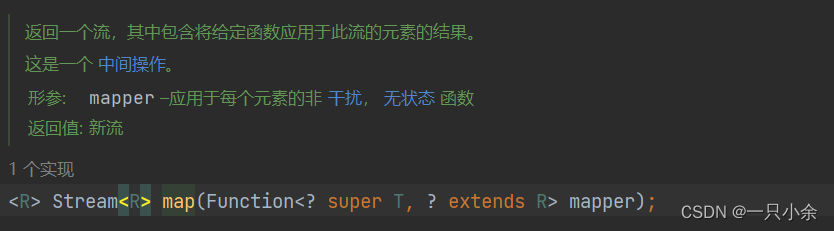
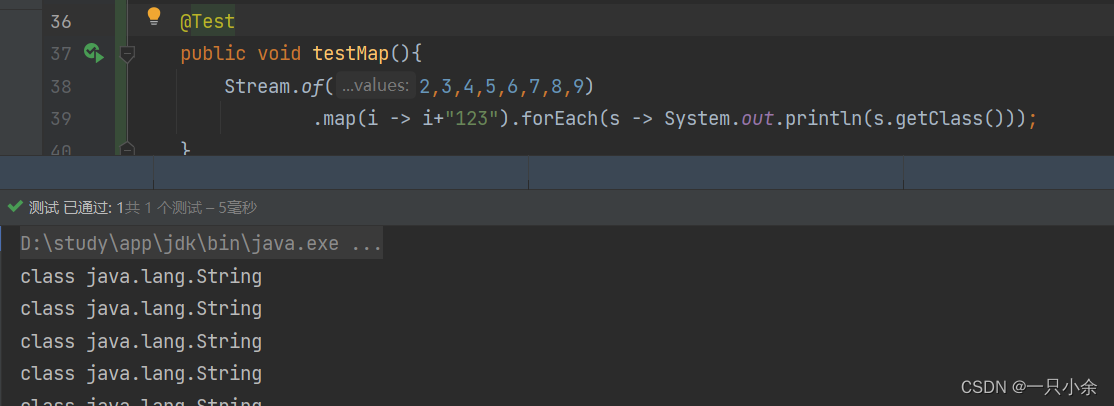
类型转换,T和R类型不相同
如果只是操作则T和R类型相同
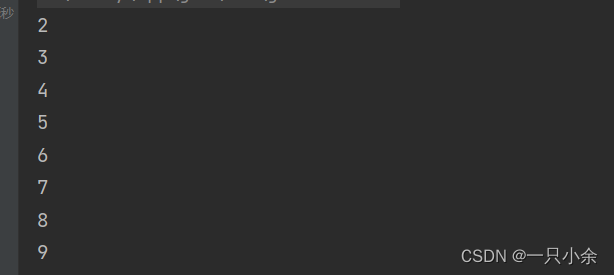
同类型的
Stream.of(2,3,4,5,6,7,8,9).map(i -> i++).forEach(System.out::println);
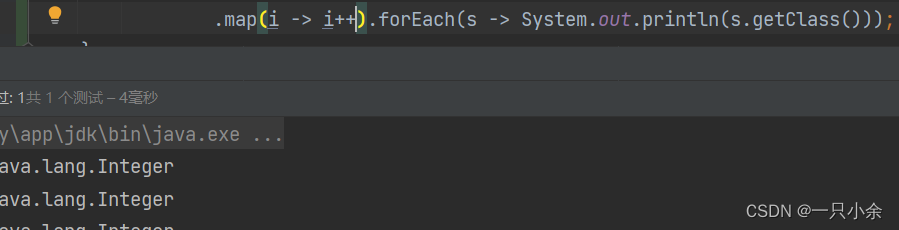
不同类型
终结方法
forEach
遍历,这个上面用过了
void forEach(Consumer action);
count
返回此流中的元素计数
long count = Stream.of(2, 3, 4, 5, 6, 7, 8, 9).map(i -> i++).count();System.out.println(count);
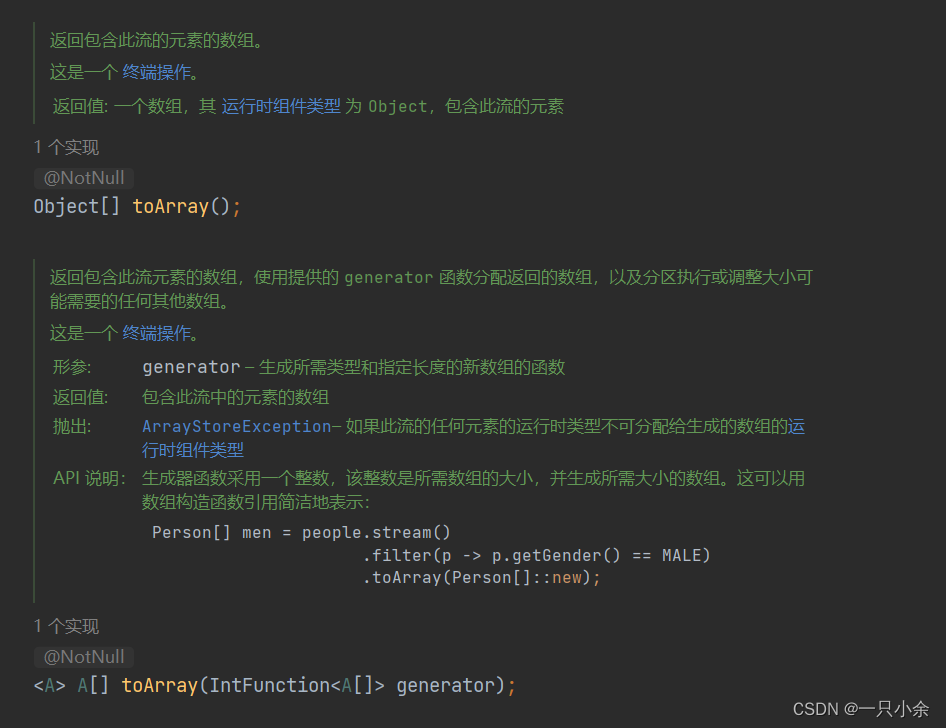
toArray
Object[] array =Stream.of(2, 3, 4, 5, 6, 7, 8, 9).map(i -> i++).toArray();System.out.println(Arrays.toString(array));
Integer[] arr = Stream.of(2, 3, 4, 5, 6, 7, 8, 9).map(i -> i++).toArray(Integer[]::new);System.out.println(Arrays.toString(arr));
collect
收集成集合,如set,list,map
list
List list = Stream.of(2, 3, 4, 5, 6, 7, 8, 9).filter(s -> s % 2 == 0).collect(Collectors.toList());Assert.assertEquals(list,List.of(2,4,6,8));
set
Set set = Stream.of(2, 3, 4, 5, 6, 7, 8, 9).filter(s -> s % 2 == 0).collect(Collectors.toSet());Assert.assertEquals(set,Set.of(2,4,6,8));
map
Stream.of("zhangsan-18","lisi-20","wangwu-22").map(s -> s.split("-")).collect(Collectors.toMap(s -> s[0], s -> s[1])).forEach((k,v) -> System.out.println(k + " : " + v));
这个代码呢,是我写完方法名和开头zhangsan自动生成的。
我开始还在疑惑,咦forEach和collect怎么可能继续用,后来我才想起,collect之后就变成Map集合了,后面这个forEach方法是map集合里面的,不是流里面的了。
测试结果,set和list通过了,map打印也正确
