
GPT-2:无监督多任务学习语言模型
论文标题:Language Models are Unsupervised Multitask Learners
论文链接:https://d4mucfpksywv.cloudfront.net/better-language-models/language-models.pdf
论文来源:OpenAI
一、概述
机器学习系统现在通过使用大型数据集、高容量模型和监督学习的组合,在任务中表现出色。然而这些系统很脆弱,对数据分布和任务规范的微小变化很敏感。目前的机器学习系统更像一个狭隘的专家而非合格的通用人才。我们希望转向更通用的系统,可以执行许多任务,最终不需要为每个任务手动创建和标注训练数据集。建立机器学习系统的主要流程是为想要执行的任务训练数据来表现特定的行为,然后训练一个系统来模仿这些行为,并且在独立同分布的测试集上测试性能。这样的模式在特定场景效果的确不错,但是对于一些特定的任务(如描述模型、阅读理解、图像分类等)来说,输入的多样性和不确定性就会把缺点给暴露出来。
我们怀疑,单一领域数据集上单一任务训练的流行是当前系统中观察到的缺乏泛化性的主要原因。在当前体系结构下,向鲁棒系统的进展可能需要在广泛的领域和任务上进行训练和评估性能。最近GLUE和decaNLP这些benchmark数据集被提出以研究这一点。多任务学习是一种提升泛化性能的很有前景的框架。然而在NLP领域多任务训练才刚刚起步。最近的两项研究分别在10个和17个(dataset, objective)对上进行训练。从元学习的视角来看,每个(dataset, objective)对都是从数据集和目标函数的分布中采样出来的单个训练样本。然而目前的机器学习系统需要成本上千个样本才能获得较好的泛化性能。多任务训练可能需要同样数量的有效训练对来达成目标。使用当前的技术,要继续扩展数据集的创建和目标设计的规模,以强制实现这一点将非常困难。因此,需要探索其他方式来执行多任务学习。
目前最优的自然语言处理系统采用预训练加有监督微调的框架。这一类的方法为了执行特定的任务仍然需要监督训练。当只有很少或者没有监督数据可用时,另一类的方法为语言模型执行特定任务展现了可观的前景,比如常识推理(commonsense reasoning)和情感分析(sentiment analysis)。在本文中,我们将这两类工作联系起来,并继续采用更通用的迁移方法。我们展示了语言模型可以在zero-shot设置下执行下游任务——无需任何参数或架构修改。我们通过强调语言模型在zero-shot设置下执行广泛任务的能力,证明了这种方法的潜力。本文的GPT-2在多个任务上取得了可观的结果。
二、方法
主要思想
GPT-2的核心是语言建模。语言建模通常是基于一组样本上的无监督分布估计,每个样本也就是一个变长的符号序列。由于语言序列具有天然的顺序,因此很自然地可以将符号序列的联合概率建模成条件概率的乘积:
❝❞
这种方法允许对以及任何这样形式的条件概率进行易于处理的抽样和估计。近年来,可以计算这些条件概率的模型的表达能力有了显著的改进,例如Transformer这样的自注意架构。
学习执行单个任务可以在概率的框架中表示为估计条件分布。由于一个通用的系统应该能够执行许多不同的任务,即使对于相同的输入,它不仅应该以输入为条件,而且还应以要执行的任务为条件,也就是说应该要建模。这在多任务和元学习的形式中广泛应用。任务条件化通常可以在模型架构层面上实现,比如采用特定于任务的encoder和decoder,或者也可在算法的层面上实现,比如MAML的内外循环优化框架。不过在语言领域,正如McCann等人(2018)所示,语言提供了一种灵活的方式来将任务、输入和输出特别表示为符号序列。举例来说,一个翻译训练样本可以被写作序列(translate to french, english text, french text),一个阅读理解训练样本可以被写作序列(answer the question, document, question, answer)。McCann等人认为可以训练一个单独的模型(也就是MQAN)在这种格式的样本上推断和执行多种不同的任务。
原则上,语言建模也能够学习McCann等人(2018)的任务,而不需要明确监督哪些符号是要预测的输出。由于监督目标与无监督目标相同,监督任务只是在序列的子集上进行测试,无监督目标的全局最小值也是监督目标的全局最小值。这意味着,如果我们可以在无监督目标函数下找到全局最小值,那么监督目标函数也会得到优化。在这种简要的设置中,对密度估计作为一个合理的训练目标的关注是被回避的。这个问题转而变成了我们能否在实践中将无监督的目标函数优化到收敛。初步的实验证实,足够大的语言模型能够在这种toy-ish的设置下执行多任务学习,但学习速度比显式监督的方法要慢得多。
从精心设计的实验设置转向从“混乱”的自然语言中学习是很大的一步。Weston(2016)认为在对话的背景下需要开发能够直接从自然语言中学习的系统,并证明了一种概念——通过对teacher模型的输出进行前向预测来学习问答任务,而不需要奖励信号。问答任务虽然是种有吸引力的方法,但是本文认为这会受到一些限制,主要是因为互联网中的大量信息只需要被动获取,而非需要(像问答任务一样)互动交流。作者的推测是,一个具有足够容量的语言模型将开始学习推断和执行自然语言序列中展示的任务,以更好地预测它们,而不管它们的获取方法如何,下图是GPT-2训练语料中的一些翻译任务的自然语言演示。如果一个语言模型能够做到这一点,它将实际上执行无监督的多任务学习。作者通过分析语言模型在zero-shot设置下的表现来测试这个想法的可行性。

训练数据集
大多数先前的研究在一个域的文本上训练语言模型比如新闻文章、维基百科、小说类书籍等。我们的方法促使构建尽可能大且多样化的数据集,以便在尽可能多的领域和上下文中收集任务的自然语言演示。本文利用网络爬虫来构建大规模的训练文本数据,然而常规的不加筛选的爬取方式将会导致数据集面临严重的文档质量问题。因此本文采用一种新的强调文档质量的网络爬取方式。为了做到这一点,我们只抓取了由人类策划/过滤的网页。我们从社交媒体平台Reddit抓取了所有的出站链接,每个链接至少得到3个karma(Reddit平台通过被点赞获得的分数)。这可以被认为是一种启发式指标,用于判断其他用户是否认为该链接有趣、有教育意义或只是好笑。通过这种方式本文构建了WebText数据集,其包含这样的4500万个链接的文本子集。本文使用初步版本的WebText,它包含超过800万份文档,总文本量为40GB。
输入表示
通用语言模型应该能够计算任何字符串的概率或者生成任何字符串。目前大规模的语言模型包括一些预处理步骤,如小写、token化和out-of-vocabulary token的处理,这些步骤限制了可建模字符串的空间。将Unicode字符串处理成UTF-8字符序列可以满足这个需求,然而目前的研究表明字符级的语言模型相比与word级的语言模型并没有竞争力,本文在实验中也观察到了这一点。
Byte Pair Encoding (BPE)是一种实际上介于字符和word级别语言建模之间的方法,它有效地插值了频繁出现的符号序列的word级别输入和不频繁出现的符号序列的字符级别输入。然而,BPE的实现通常是基于Unicode编码点而不是字节序列的,这要求包括Unicode的全部符号才能建模所有的Unicode字符串。这会导致一个超过130,000的基本词汇表(不包括多符号token),与BPE通常使用的32,000到64,000令牌词汇表相比,这是无法承受的。如果采用字符级别的BPE版本,它只需要大小为256的基本词汇表。然而,直接将BPE应用于字符序列会导致合并效果不佳,因为BPE使用一种贪心的基于频率的启发式算法来构建token词汇表。作者发现BPE包括了许多常见单词的多个版本,比如dog.、dog!、dog?等,这会导致有限的词汇槽和模型容量的分配不够优化。为了避免这种情况,作者防止BPE在任何字节序列中跨字符类别(dog和.!?属于不同的字符类别)合并。他们为空格添加了一个例外,这显著提高了压缩效率,同时只对多个词汇token中的单词进行了最小的分段处理。
这种输入表示允许我们将词级语言模型的好处与字符级方法的一般性结合起来。由于我们的方法可以为任何Unicode字符串计算概率,这允许我们在任何数据集上评估,而不管预处理、token化或词汇表大小。
模型
GPT-2的模型与GPT差不多,只是做了一些修改。Layer normalization被转移到每个sub-block的输入上,并且在最后一个自注意力block后添加一个layer normalization。采用一种改进的初始化方法,该方法考虑了残差路径与模型深度的累积。在初始化时将残差层的权重按的因子进行缩放,其中是残差层的数量。词汇表扩大到50,257。我们还将上下文大小从512增加到1024个token,并使用512的更大的batchsize。
三、实验
模型大小
GPT-2主要包括四个size的模型:

主要实验结果
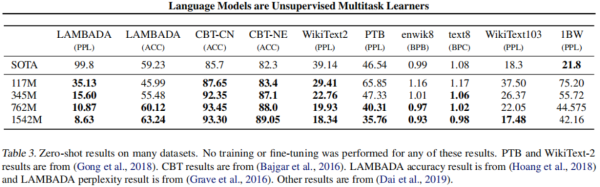
GPT-2在多个数据集上的zero-shot实验性能:
其他实验
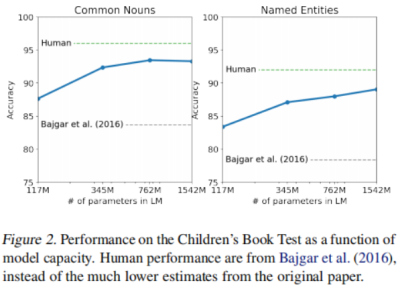
Children’s Book Test数据集上性能与模型容量的关系:
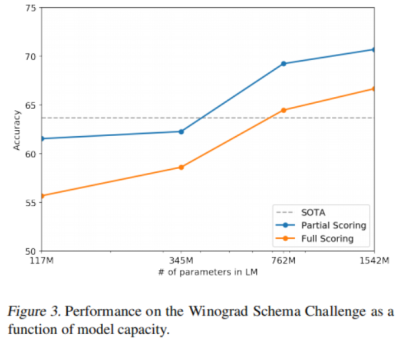
Winograd Schema challenge实验性能与模型容量的关系:
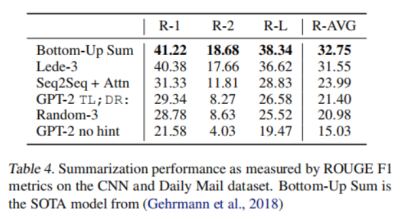
Summarization实验:
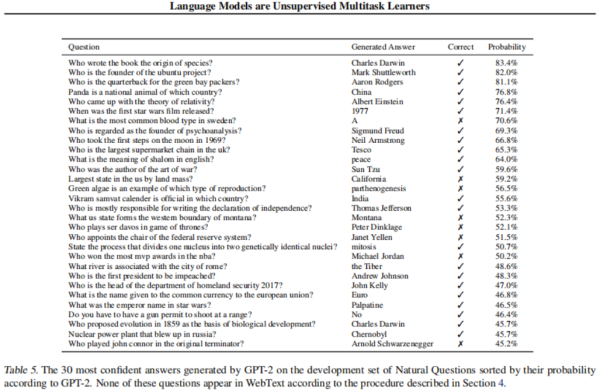
问答实验的前30个信心分数最高的回答:
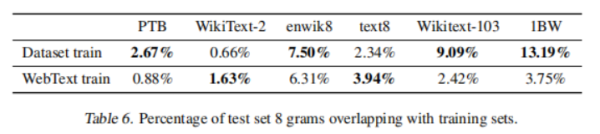
为了分析模型是在泛化还是记忆,调研了数据集直接的重复比例:
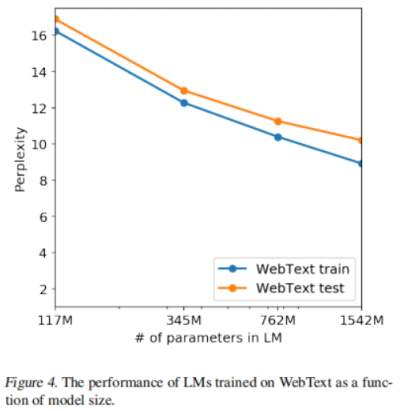
WebText上的性能,下图表明即使是最大size的GPT-2对于WebText数据集仍然是欠拟合的:
上一篇:java -- stream流
下一篇:2.JVM常识之 运行时数据区