
Face Forgery Suvery
文章目录
- Face Forgery
- Face Forgery class
- Attribute Manipulation
- Expression Swap
- Identity Swap
- Entire Face Synthesis
- Face Forgery Detection
- Low-level
- On the Detection of Digital Face Manipulation(CVPR2020)
- High-level
- Protecting World Leaders Against Deep Fakes
- Detecting Deep-Fake Videos from Appearance and Behavior
- Out of Arms race
- Artificial GAN Fingerprints: Rooting Deepfake Attribution in Training Data
Face Forgery
对数字图像的优化一直是计算机应用技术的研究热点,对人脸图像进行修改自美颜相机的出现后持续受到广大主播用户的追捧。这些图像修改方式或多或少对人脸认证增加了难度。尤其是近些年数据的爆炸增长和计算能力的快速发展,出现的专门对人脸进行伪造的算法,其依靠训练学习方式对人脸外观或者属性进行伪造,伪造出来的人脸图像也愈加真实,已经到了人眼无法辨别的程度。由于利用了更加先进的算法,以往的图像认证技术也很难应对这种伪造图像。
Face Forgery class
目前还有没准确的人脸伪造方式分类方案,但按照伪造程度大致可以分为Attribute Manipulation, Expression Swap(inc. Lip Sync), Identity Swap Entire Face Synthesis. (TODO: 优化分类方案)
Attribute Manipulation
这种伪造方式包括对人脸或头发的颜色,性别、年龄、是否佩戴眼镜等内容进行篡改。该类伪造方式通常以
Expression Swap
Identity Swap
Entire Face Synthesis
Face Forgery Detection
为了应对人脸伪造带来了巨大安全隐患,研究员也提出了诸多检测办法。在这里,我将其分类为两种:
- Low-level Approach:侧重于检测人脸图像合成过程中引入的像素级痕迹。比如,基于GAN网络生成的伪造图像,存在明显的与真实图像不同的频率分布特征。
- High-level Approach:侧重于检测伪造视频中存在的语义级别的不一致性。比如,视频中说话人的口型与声音存在明显的差异。
Low-level
On the Detection of Digital Face Manipulation(CVPR2020)
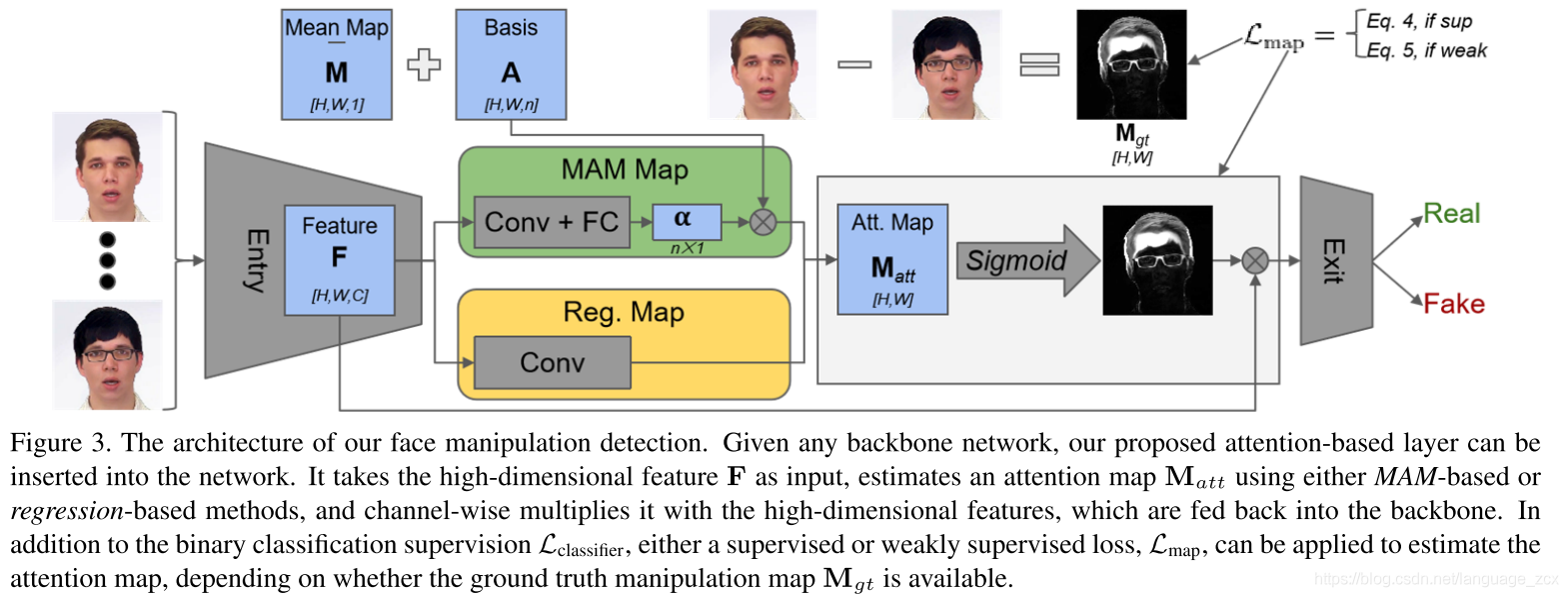
本文采用multi-task的方式同时对图像进行伪造检测和伪造区域的定位,文中对比了两种Attention机制和不同监督程度下训练得到的模型的准确度。除此之外,本文推出首个包含多种人脸伪造类型的数据集Diverse Fake Face Datasets(DFD),并提出逆交叉非包容Inverse Intersection Non- Containment(IINC)度量标准,用于评估attention map与GT的一致性,与现有的度量(IoU等)相比更加稳定准确。详见>>
High-level
以下介绍的检测方式,尽量以发表的时间为序
Protecting World Leaders Against Deep Fakes
Here
Detecting Deep-Fake Videos from Appearance and Behavior
这篇文章与上一篇一脉相承,作者也属于同一波人。所采用的基本原理一致,所不同的是,本篇利用了CNN,并在常见伪造检测数据集上做了实验和对比。
here
Out of Arms race
众所周知,伪造的生成算法与伪造的检测算法彼此相互抗争,在此过程中,双方都可以利用对方现存算法的缺陷实现算法的改进,这使得双方的算法不断的提升效果,但这种模式无疑进入一种死循环。对于伪造检测算法而言,这使得其无法做到真正的有效和泛化。因此,逐渐有学者另辟蹊径,跳出这场你来我往的竞争中,试图从根本上找到一种一劳永逸的伪造检测办法。
Artificial GAN Fingerprints: Rooting Deepfake Attribution in Training Data
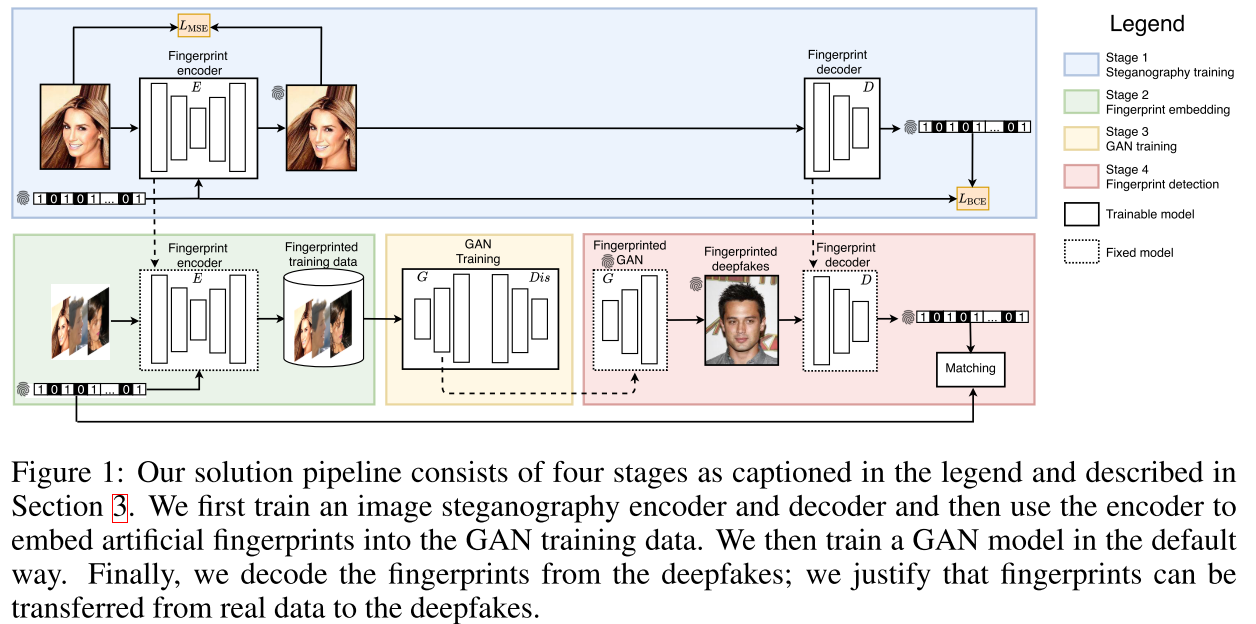
作者认为当前的伪造检测方与伪造生成算法构成的“军备竞赛”是无休止的。必须要从根源入手来解决伪造检测问题。基于GAN的伪造生成算法,作者提出利用隐写分析技术对训练GAN的数据集加入指定指纹,并证明在该数据集上训练的GAN模型生成的图像具有相同的指纹,即指纹从训练数据传递到了GAN模型。基于此,可以通过对图像进行指纹检测,并与指纹数据库进行对比,以此来进行伪造检测并进行生成算法溯源。具体的研究进一步证明了该方案的几个有益特性,包括通用性,与GAN发展的协同性,保真度和鲁棒性。
其中与GAN发展的协同性指GAN的生成效果越好,在其生成的图片中检测到指纹的概率越高。
If a GAN technique can approximate real data distribution more accurately, it also transfers the artificial fingerprints more accurately.