
gleam流式计算(分布式/单机)
介绍
Gleam 是一个高效、可伸缩的分布式map/reduce系统,DAG(有向无环图)执行模式,数据可以纯内存或磁盘的方式进行流转。 可单点,也可以分布式部署 https://github.com/chrislusf/gleam
使用Gleam之前,我们需要先了解下map/reduce的概念(看源码之前先找一些相关资料了解其工作原理)
MapReduce讲的就是分而治之的程序处理理念,把一个复杂的任务划分为若干个简单的任务分别来做。map和reduce函数是要执行的任务,由master分配任务给worker执行。map函数读取被分配的输入数据片段,输出中间key/value pair值的集合,reduce函数收集具有相同中间key值的value值,合并这些value值,形成一个较小的value值的集合。
比如要做一个统计词频的工作流:
- 输入(input)为文件内容
Hello PHP
Hello Java
Hello C
Hello Java
Hello C++
- 拆分(split)把文件进行分片,交给worker,进行map处理,将上述文档中每一行的内容转换为key-value对,
(PHP ,1)
(Java, 1)
(C, 1)
(Java, 1)
(C++, 1)
3.分发(shuffle)将key相同的扔到一起去,即:
(PHP ,1)
(Java, 1, 1)
(C, 1)
(C++, 1)
- 归并(reduce),上一步的结果集分发给对应的reduce函数,对相同key的value进行遍历
(PHP ,1)
(Java, 2)
(C, 1)
(C++, 1)
\5. 之后就可以做一些排序、topN等等操作。
单机模式
数据量不是很大(数GB)的情况下,单机模式就可以满足需求,以下是单机模式的流程图
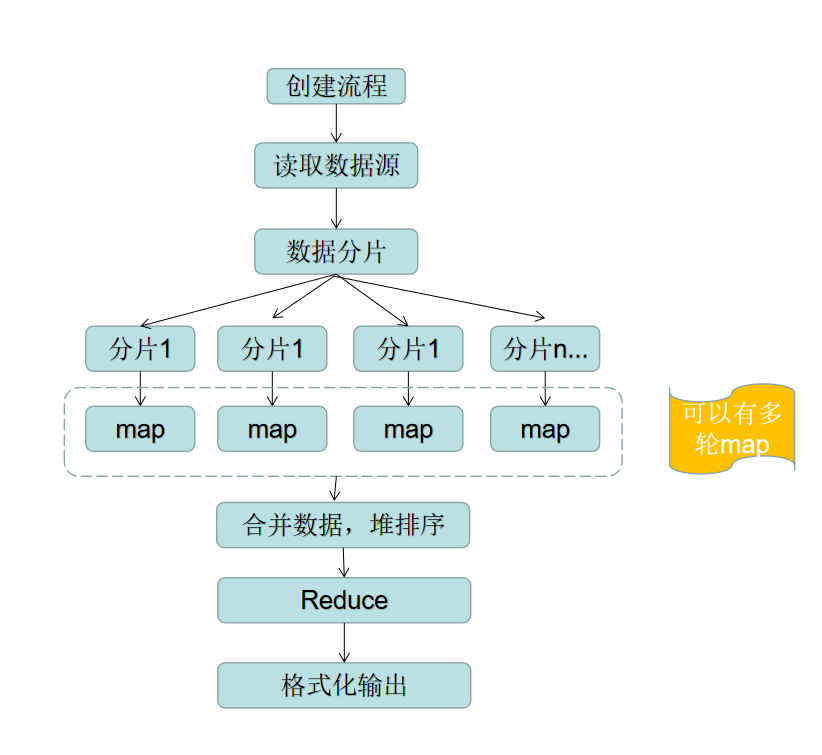
在gleam中,从数据源 …-> map …-> reduce …-> 输出,整个链中数据均通过管道io.Piper进行流转
-
数据源
默认支持txt、csv、Tsv、Parquet、Orc、Sokect监听、Channel、Bytes、Strings、Ints、Slices 除此之外,框架对数据源的读取已经做了高度封装,只要实现一个接口就可以无缝融入到Flow流程当中type Sourcer interface {Generate(*Flow) *Dataset } -
map函数
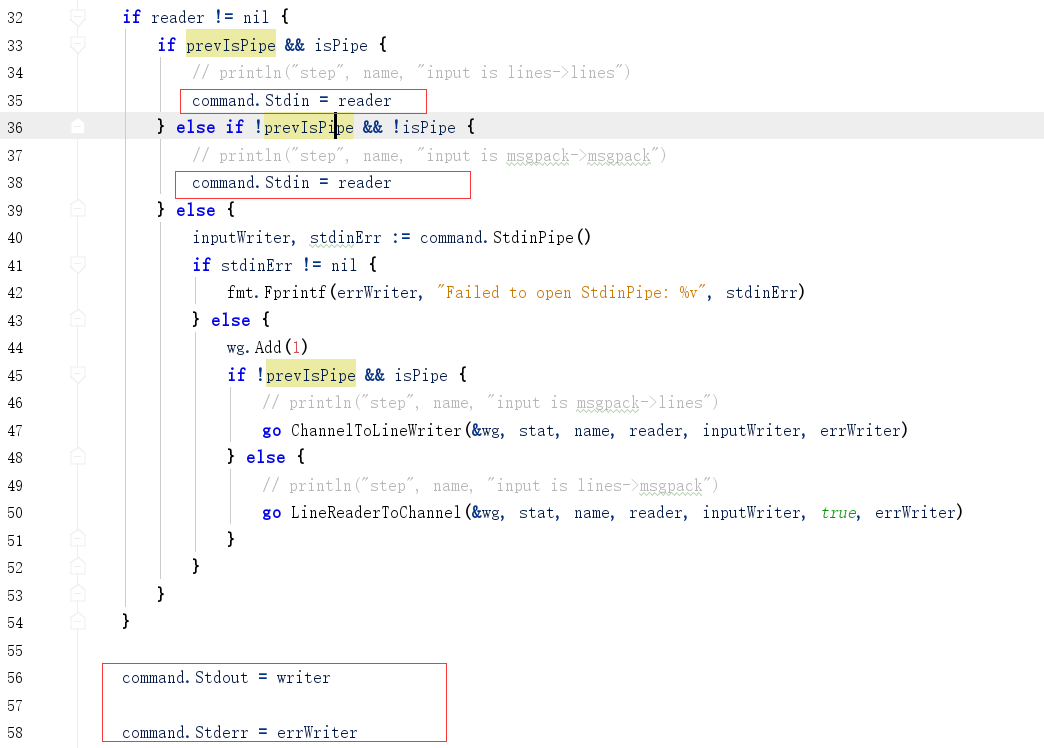
map函数是一个类型:type Mapper func([]interface{}) error , 所以自定义的map函数必须和该类型匹配,如var Token = gio.RegisterMapper(token) //必须是全局变量。 Token为maperId,框架的Map函数是通过此ID进行定位用户自定义map函数的, token为自定义函数名//读取一行数据 func token(row []interface{}) error {...//对每行数据进行切割,并设置key , value...//gio.Emit(key, value)//Emit 函数对key ,value编码后,写入了os.Stdout中, 刚才提到,Gleam中数据是通过io.Pipe进行流转的,所以此处的os.Stdout 不会输出到终端,//因为此处的os.Stdout 被重定向了return nil }IO重定向,位置:github.com\chrislusf\gleam\util\exec_util.go. 下图中的reader和writer 实际上分别是一个ioPipe()的实例 PipeReader和PipeWriter
-
reduce
reduce 也函数是一个类型:type Reducer func(x, y interface{}) (interface{}, error) , 所以自定义的reduce 函数必须和该类型匹配,如var Sum = gio.RegisterReducer(sum) //必须是全局变量。 Sum 为reduceId,框架的Reduce函数是通过此ID进行定位用户自定义reduce函数的, sum为自定义函数名//对相同key的元素进行遍历 //x代表一个key的累计值, y代表该key的当前一个处理值 //最终实现了对key的值进行求和 func sum(x, y interface{}) (interface{}, error) {return gio.ToInt64(x) + gio.ToInt64(y), nil }注:当map后dataSet中没有重复key, 则后续的reduce函数不会执行
-
输出
带缓冲的:Fprintf
直接输出:Fprintlnf
自定义输出:OutputRow ,此接口我们可以自定义一个回调函数,灵活实现个性化需求。除此之外也可以添加其他的处理节点,Gleam所提供的有:Sort 排序、取TopN、SelectKv、Select选择Key,从1开始、Partition 分区 等等
提示
官方示例中 “Word Count” 存在一个bug
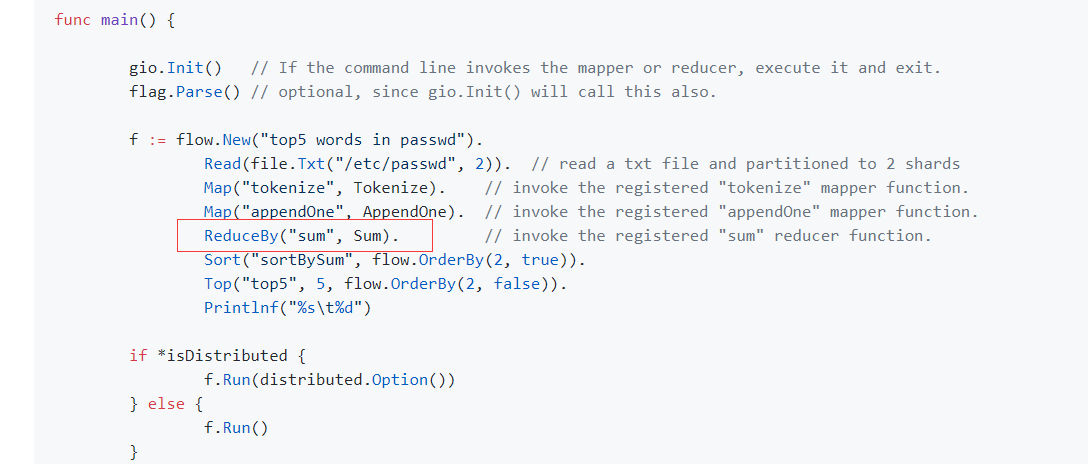
正确写法:那么A, 要么B
A. ReduceByKey(“sum”, Sum). //按第一个key降序排序
B. ReduceBy(“sum”, Sum, flow.OrderBy(1, false)). //按第一个key降序排序
示例:
自定义Json数据源,计算学生的平均值,并取前三名
package mainimport ("github.com/chrislusf/gleam/gio""flag""github.com/chrislusf/gleam/distributed""encoding/json""github.com/chrislusf/gleam/flow""github.com/chrislusf/gleam/util""fmt""os""strconv")var (isDistributed = flag.Bool("distributed", false, "run in distributed or not")verbose = flag.Bool("verbose", false, "print out actual mapper and reducer function names")
)var (Token1 = gio.RegisterMapper(token1)Avg = gio.RegisterMapper(avg)Combine = gio.RegisterReducer(combine)//学科数目subjectsNum int64 = 2
)type Submit struct {Name string `json:"name"`Score int `json:"score"`Subject string `json:"subject"`
}
type test []Submitfunc main() {if *verbose {gio.ListRegisteredFunctions()}gio.Init()json_str := `[{"name":"stu1","score": 21,"subject": "数学"},{"name":"stu2","score": 100,"subject": "数学"},{"name":"stu3","score": 50,"subject": "数学"},{"name":"stu4","score": 70,"subject": "数学"},{"name":"stu5","score": 80,"subject": "数学"},{"name":"stu5","score": 77,"subject": "语文"}]
`subs := &test{}json.Unmarshal([]byte(json_str), subs)db := make([][]interface{}, len(*subs))for i, v := range *subs{t, _ := json.Marshal(v)db[i] = append(db[i], t)}f := flow.New("平均分为前三且不是stu2的学生").Slices(db).Map("tokenize", Token1).ReduceByKey("combine", Combine).Map("avg", Avg).Sort("按学生成绩倒序排序(中英文都可以)", flow.OrderBy(2, false)).Top("top3,用此函数可以省略排序如:Sort,SortByKey", 3, flow.OrderBy(2, false)).OutputRow(func(row *util.Row) error{decodedObjects := make([]interface{}, 0)decodedObjects = append(decodedObjects, row.K...)decodedObjects = append(decodedObjects, row.V...)fmt.Printf("output: %v ,%v\n", decodedObjects...)return nil})if *isDistributed {f.Run(distributed.Option())}else {f.Run()}
}//处理数据获取可用字段
func token1(row []interface{}) error{sub := &Submit{}b, _ := row[0].([]interface{})json.Unmarshal(b[0].([]byte), sub)//排除学生stu2if sub.Name == "stu2"{return nil}gio.Emit(sub.Name, []int64{gio.ToInt64(sub.Score)})return nil
}//计算平均值
func avg(row []interface{}) (error){var total int64if r, ok := row[1].([]interface{}); ok{for _, v := range r{if score, ok := v.(int64); ok {total += score}}}avg := Decimal(float64(total)/ float64(subjectsNum))//myPrint("avg: %v\n", avg)gio.Emit(row[0], avg)return nil
}//合并学科分数
func combine(x, y interface{}) (interface{}, error){switch t := x.(type) {case []interface{}:t = append(t, convertToSlice(y)...)//myPrint("t: %v\n", reflect.TypeOf(t))return t, nil}return x, nil
}func convertToSlice(v interface{}) ([]interface{}){switch t := v.(type) {case []interface{}:return tdefault:return nil}
}func Decimal(value float64) float64 {value, _ = strconv.ParseFloat(fmt.Sprintf("%.2f", value), 64)return value
}//由于在map中 os.Stdout 被重定向了,所以用os.Stderr来打印数据
func myPrint(format string, v...interface{}){fmt.Fprintf(os.Stderr, format, v...)
}
总结
像Slices、Bytes、Channel 等,数据获取方式,可以很好的和golang的kafkaWorker结合进行流计算