
kafka 日志系统,高效、可靠的日志管理解决方案
Kafka日志系统:高效、可靠的日志管理解决方案
随着大数据时代的到来,企业对日志管理的要求越来越高。Kafka作为一种高性能、可扩展的分布式消息队列系统,在日志管理领域发挥着越来越重要的作用。本文将详细介绍Kafka日志系统的特点、架构以及应用场景。
一、Kafka日志系统的特点
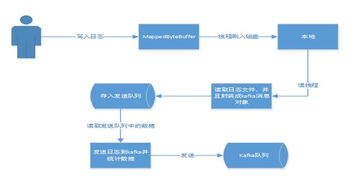
1. 高性能:Kafka采用分布式架构,能够实现高吞吐量的日志收集和处理,满足大规模日志系统的需求。
2. 可扩展性:Kafka支持水平扩展,通过增加Broker节点,可以轻松提升系统处理能力。
3. 容错性:Kafka采用副本机制,确保数据在发生故障时不会丢失,提高系统的可靠性。
4. 易于集成:Kafka支持多种客户端语言,方便与其他系统进行集成。
5. 支持多种消息格式:Kafka支持多种消息格式,如JSON、XML、Avro等,满足不同场景下的日志需求。
二、Kafka日志系统架构
1. 生产者(Producer):负责将日志数据发送到Kafka集群。生产者可以是应用程序、日志收集器或其他系统。
2. 消费者(Consumer):负责从Kafka集群中读取日志数据。消费者可以是应用程序、日志分析工具或其他系统。
3. Broker:Kafka集群中的节点,负责存储和转发消息。Broker之间通过Zookeeper进行协调。
4. 主题(Topic):Kafka中的消息分类标识,类似于数据库中的表。每个主题可以包含多个分区(Partition)。
5. 分区(Partition):Kafka中的数据存储单元,每个分区存储一定范围内的日志数据。
6. Zookeeper:Kafka集群的协调服务,负责存储集群元数据、配置信息等。
三、Kafka日志系统应用场景
1. 日志收集:Kafka可以收集来自各个系统的日志数据,如Web服务器、数据库、应用程序等。
2. 日志分析:Kafka可以与Elasticsearch、Logstash、Kibana等工具结合,实现日志数据的实时分析和可视化。
3. 实时监控:Kafka可以实时监控系统运行状态,及时发现异常并进行处理。
4. 数据归档:Kafka可以将历史日志数据存储在HDFS、OSS等存储系统中,实现数据归档和备份。
5. 流处理:Kafka可以与Apache Flink、Spark等流处理框架结合,实现实时数据处理和分析。
四、Kafka日志系统优势
1. 高性能:Kafka采用异步IO和内存映射技术,实现高吞吐量的日志收集和处理。
2. 可靠性:Kafka采用副本机制和Zookeeper协调服务,确保数据在发生故障时不会丢失。
3. 可扩展性:Kafka支持水平扩展,通过增加Broker节点,可以轻松提升系统处理能力。
4. 易于集成:Kafka支持多种客户端语言,方便与其他系统进行集成。
5. 支持多种消息格式:Kafka支持多种消息格式,满足不同场景下的日志需求。
Kafka日志系统凭借其高性能、可扩展性、可靠性等特点,已成为企业日志管理的重要解决方案。随着大数据时代的到来,Kafka在日志管理领域的应用将越来越广泛。