
DMA cache一致性怎么保持(修改中)
标题dma如何保持和cache一致性
(1)一致性映射,代表函数:
void *dma_alloc_coherent(struct device *dev, size_t size, dma_addr_t *handle, gfp_t gfp);void dma_free_coherent(struct device *dev, size_t size, void *cpu_addr, dma_addr_t handle);
dma_alloc_coherent申请一片DMA缓冲区,以进行地址映射并保证缓冲区的Cache一致性。
2.流式DMA映射(DMA Streaming Mapping)
dma_addr_t dma_map_single(struct device *dev, void *cpu_addr, size_t size, enum dma_data_direction dir)
void dma_unmap_single(struct device *dev, dma_addr_t handle, size_t size, enum dma_data_direction dir)
void dma_sync_single_for_cpu(struct device *dev, dma_addr_t handle, size_t size, enum dma_data_direction dir)
void dma_sync_single_for_device(struct device *dev, dma_addr_t handle, size_t size, enum dma_data_direction dir)
在流式DMA映射场合,DMA传输通道所使用的缓冲区往往不是由当前驱动程序自身分配的,而且往往每次DMA传输都会重新建立一个流式映射的缓冲区。此外,由于无法确定外部模块传入的DMA缓冲区的映射情况,所以设备驱动程序必须小心地处理可能会出现的cache一致性问题。
(1)在向内传输(rx)时,DMA设备将数据写入内存后,DMAC将向CPU发出中断请求,在RX ISR中使用该内存之前,需要先InvalidateD-Cache(sync_single_for_cpu)使cache无效重填(refill),此时CPU通过高速缓存cache获得的才是最新的数据。
/* 确定中断是由对应的设备发来的*/
dma_unmap_single(dev->pci_dev->dev,dev->dma_addr,
dev->dma_size,dev->dma_dir);
/* 释放之后,才能访问缓冲区,把它拷贝给用户 */
2)在向外传输(tx)时,一种可能的情形是CPU构造的本地协议栈反馈包还在D-Cache中,故在send调用中需要先Flush D-Cache(sync_single_for_device)将数据写回(write back)到内存,使DMA缓存更新为最新鲜的待发送数据再启动DMA TX trigger。
说白了就是接收清cache操作sync_single_for_cpu,发送刷cache操作sync_single_for_device。
CPU的读/写用的是不同的cache(读用的是cache,写则用的是write buffer),所以建立流式DMA映射需要指明数据在DMA通道中的流向,以便由内核决定是操作cache还是write buffer。
Cache原理
CPU缓存(Cache Memory)是位于CPU与内存之间的临时存储器,它的容量比内存小的多但是交换速度却比内存要快得多。缓存的出现主要是为了解决CPU运算速度与内存 读写速度不匹配的矛盾,因为CPU运算速度要比内存读写速度快很多,这样会使CPU花费很长时间等待数据到来或把数据写入内存。在缓存中的数据是内存中的 一小部分,但这一小部分是短时间内CPU即将访问的,当CPU调用大量数据时,就可避开内存直接从缓存中调用,从而加快读取速度。
DMA:
直接内存访问(DMA,Direct Memory Access)是一些计算机总线架构提供的功能,它能使数据从附加设备(如磁盘驱动器)直接发送到计算机主板的内存上。
1、内存空间包括 内存 和 寄存器空间。
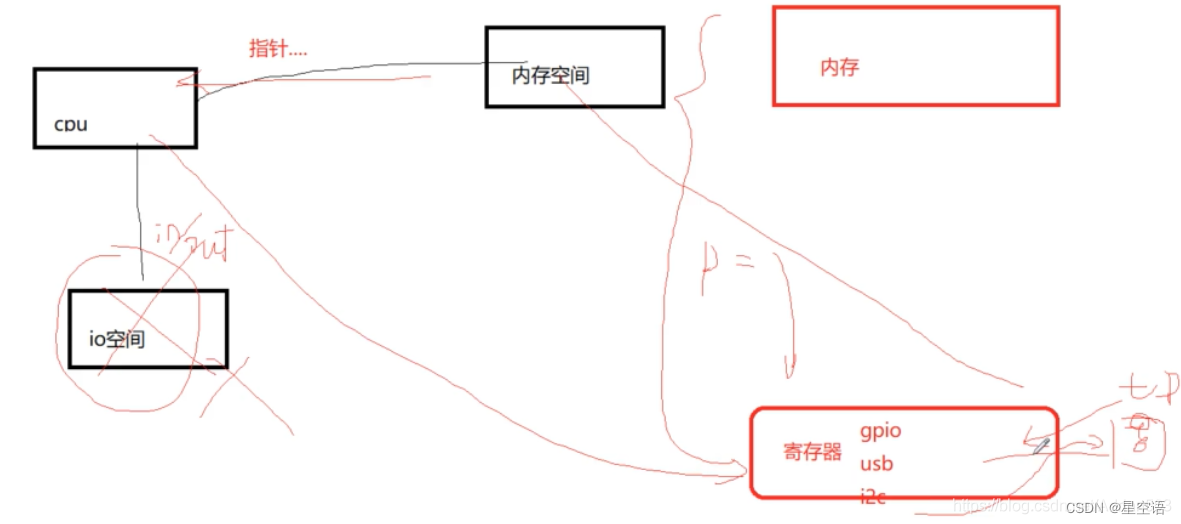
2、CPU 、cache、内存、外设 之间的关系。以及 cache 一致性 是如何导致的
CPU写内存的时候有两种方式:
- write through: CPU直接写内存,不经过cache。
- write back: CPU只写到cache中。cache的硬件使用LRU算法将cache里面的内容替换到内存。通常是这种方式。
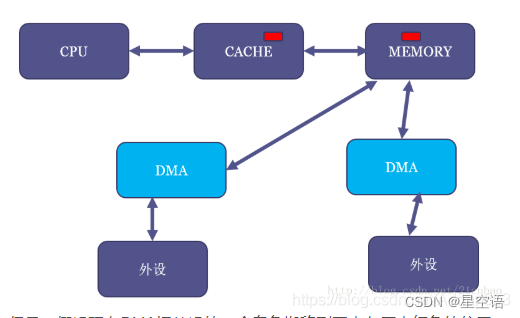
但是,假设现在DMA把外设的一个白色搬移到了内存原本红色的位置:
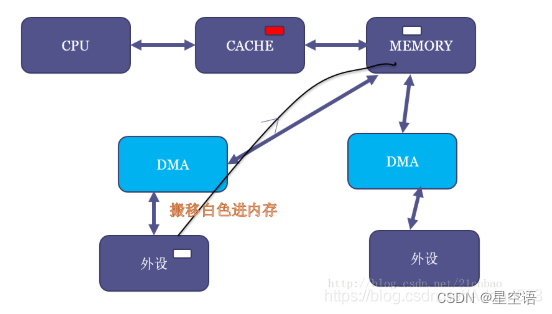
这个时候,内存虽然白了,CPU读到的却还是红色,因为CACHE命中了,这就出现了cache的不coherent。
当然,如果是CPU写数据到内存,它也只是先写进cache(不一定进了内存),这个时候如果做一个内存到外设的DMA操作,外设可能就得到错误的内存里面的老数据。
要解决 cache的不一致性 一般有4种方法。
1、一种是硬件方案,例如上面介绍的在SoC中集成了叫做“Cache Coherent interconnect”的硬件,它可以做到让DMA踏到CPU的cache或者帮忙做cache的刷新。这样的话,dma_alloc_coherent()申请的内存就没必要是非cache的了。
2、一种是软件上禁用 cache (kernel 机制 ------ 一致性映射)
3、一种是 DMA Streaming Mapping (kernel 机制 ------ 流式映射)
4、软件通过flush cache / invalid cache 来保证data 一致性。
DMA 从外设读取数据到供处理器使用时,可先进性invalidate 操作。这样将迫使处理器在读取cache中的数据时,先从内存中读取数据到缓存,保证缓存和内存中数据的一致性。
DMA 向外设写入由处理器提供的数据时,可先进性writeback 操作。这样可以DMA传输数据之前先将缓存中的数据写回到内存中。
参考
原文链接:https://blog.csdn.net/Adrian503/article/details/115536886